


arXiv paper "Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions", uploaded on August 1, 22, work from Cornell and Ohio State universities.

In recent years, the perception capabilities of autonomous vehicles have improved due to the use of large-scale data sets, which are often collected in specific locations and under good weather conditions. However, in order to meet high safety requirements, these sensing systems must operate robustly in various weather conditions, including snow and rain conditions.
This article proposes a data set to achieve robust autonomous driving, using a new data collection process, that is, in different scenarios (cities, highways, rural areas, campuses), weather (snow, rain, sun), time Data were recorded repeatedly along a 15 km route under (day/night) and traffic conditions (pedestrians, cyclists and cars).
The dataset includes images and point clouds from cameras and lidar sensors, as well as high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations, local occlusions and 3-D bounding boxes captured with amodal masks.
Repeated paths open up new research directions for target discovery, continuous learning, and anomaly detection.
Ithaca365 link: A new dataset to enable robust autonomous driving via a novel data collection process
The picture shows the sensor configuration of data collection:
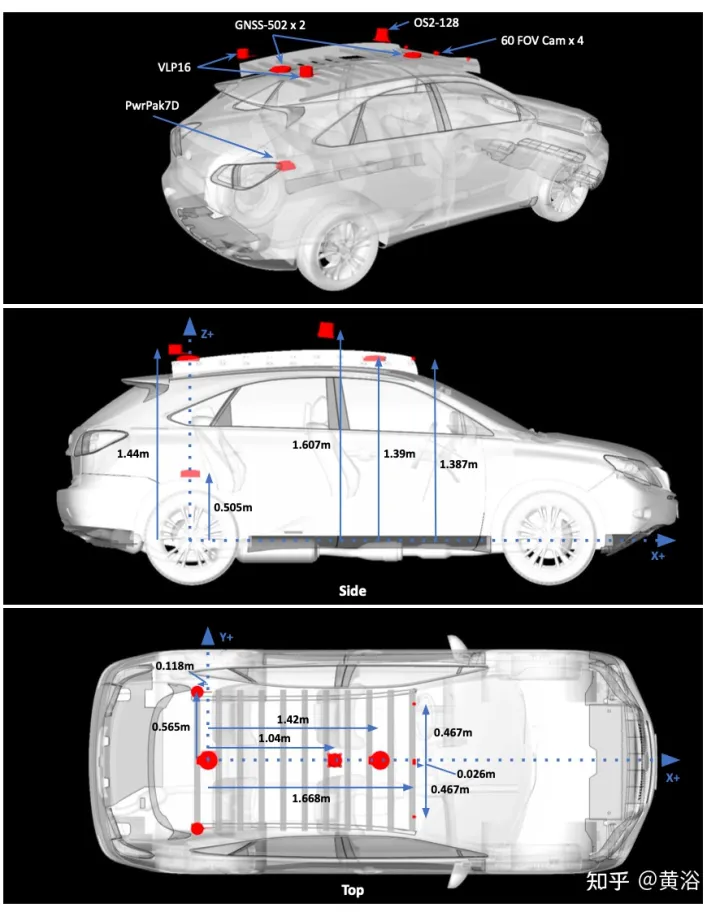
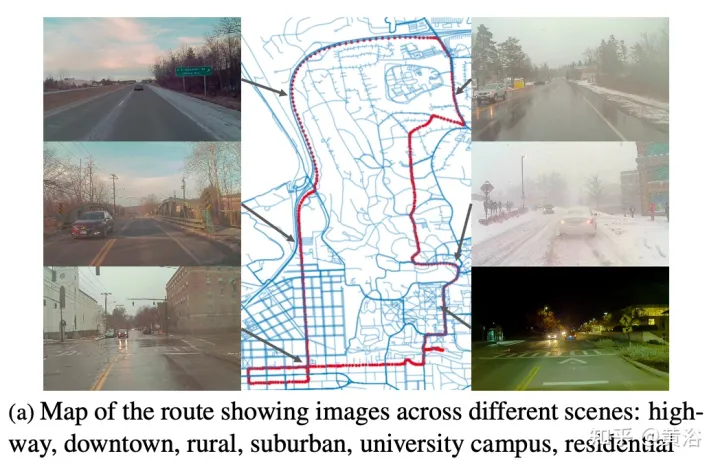
Figure a shows the route map with images captured at multiple locations. Drives were scheduled to collect data at different times of the day, including at night. Record heavy snow conditions before and after road clearing.
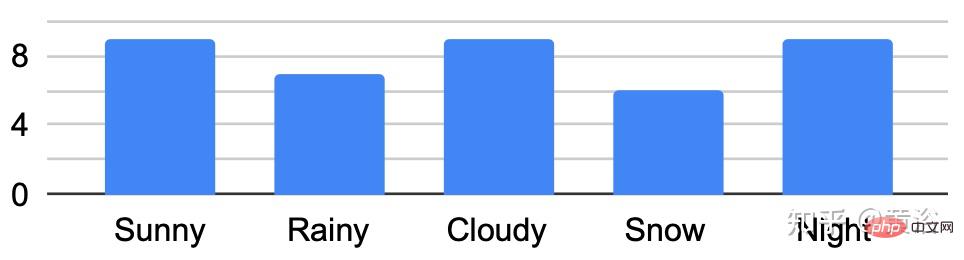
A key feature of the dataset is that the same locations can be observed under different conditions; an example is shown in Figure b.

The figure shows the traversal analysis under different conditions:
Develop a custom marking tool , used to obtain amodal masks of roads and objects. For road labels under different environmental conditions, such as snow-covered roads, use repeated traversals of the same route. Specifically, the point cloud road map constructed from GPS attitude and lidar data converts the road label of "good weather" into "bad weather".
Routes/data are divided into 76 intervals. Project the point cloud into BEV and label the road using polygon annotator. Once the road is marked in BEV (generating a 2-D road boundary), the polygon is decomposed into smaller 150 m^2 polygons, using a threshold of 1.5 m average height, and a plane fit is done to the points within the polygon boundary to determine the road height. .
Use RANSAC and a regressor to fit a plane to these points; then use the estimated ground plane to calculate the height of each point along the boundary. Project the road points into the image and create a depth mask to obtain the non-modal label of the road. Matching locations to marked maps with GPS and optimizing routes with ICP can project ground planes to specific locations on new collection routes.
A final check on the ICP solution by verifying that the average projected ground truth mask of the road label conforms to 80% mIOU with all other ground truth masks at the same location; if not, querying the location data will not be retrieved.
Non-modal targets are labeled with Scale AI for six foreground target categories: cars, buses, trucks (including cargo, fire trucks, pickup trucks, ambulances), pedestrians, cyclists, and motorcyclists.
This labeling paradigm has three main components: first identifying visible instances of an object, then inferring occluded instance segmentation masks, and finally labeling the occlusion order of each object. Marking is performed on the leftmost forward camera view. Follows the same standards as KINS ("Amodal instance segmentation with kins dataset". CVPR, 2019).
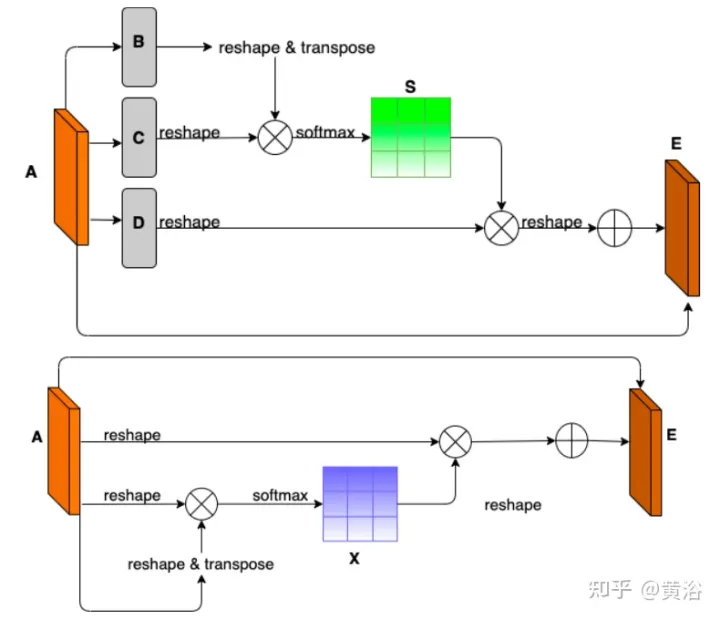
To demonstrate the environmental diversity and amodal quality of the dataset, two baseline networks were trained and tested to identify amodal roads at the pixel level, working even when the roads are covered with snow or cars. The first baseline network is Semantic Foreground Inpainting (SFI). The second baseline, as shown in the figure, adopts the following three innovations to improve SFI.
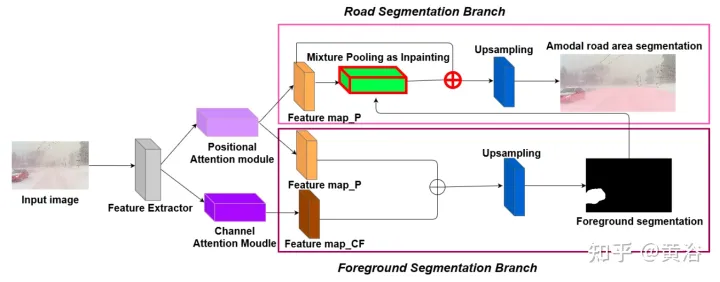
The picture shows the architecture diagram of PAM and CAM:
The pseudo code of the hybrid pooling patching algorithm is as follows:

The training and testing codes for non-modal road segmentation are as follows: https://github.com/coolgrasshopper/amodal_road_segmentation
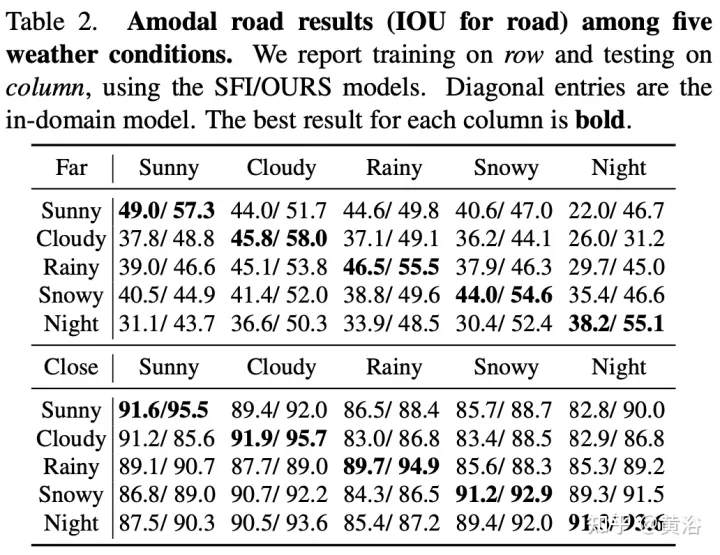
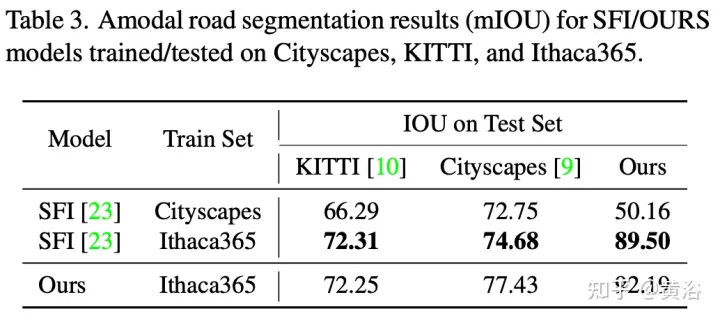
The experimental results are as follows:
##
The above is the detailed content of Datasets and driving perception in repetitive and challenging weather conditions. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



