


“Making large models smaller”This is the academic pursuit of many language model researchers. In view of the expensive environment and training costs of large models, Chen Danqi spoke at the Zhiyuan Conference A special report entitled "Making large models smaller" was given at the Qingyuan Academic Annual Meeting. The report focused on the TRIME algorithm based on memory enhancement and the CofiPruning algorithm based on coarse- and fine-grained joint pruning and layer-by-layer distillation. The former can take into account the advantages of language model perplexity and retrieval speed without changing the model structure; while the latter can achieve faster processing speed and smaller model structure while ensuring the accuracy of downstream tasks.

Chen Danqi Assistant Professor, Department of Computer Science, Princeton University
Chen Danqi was born in 2012 He graduated from the Yao Class of Tsinghua University in 2018 and received a PhD in computer science from Stanford University in 2018. He studied under Christopher Manning, a professor of linguistics and computer science at Stanford University.
In recent years, the field of natural language processing is rapidly being dominated by large language models. Since the advent of GPT 3, the size of language models has grown exponentially. Big tech companies continue to release larger and larger language models. Recently, Meta AI released the OPT language model (a large language model containing 175 billion parameters) and opened the source code and model parameters to the public.

The reason why researchers admire large language models so much is because of their excellent learning capabilities and performance. However, people are not satisfied with large language models. The black box nature is still poorly understood. Inputting a question into the language model and reasoning step by step through the language model can solve very complex reasoning problems, such as deriving answers to calculation problems. But at the same time, there are risks with large-scale language models, especially their environmental and economic costs. For example, the energy consumption and carbon emissions of large-scale language models such as GPT-3 are staggering.  Faced with the problems of expensive training of large language models and huge number of parameters, Chen Dan’s team hopes to reduce the calculation amount of pre-training models through academic research and make language models more efficient for lower-level applications. . To this end, two works of the team are highlighted. One is a new training method for language models called TRIME, and the other is an effective model pruning method suitable for downstream tasks called CofiPruning.
Faced with the problems of expensive training of large language models and huge number of parameters, Chen Dan’s team hopes to reduce the calculation amount of pre-training models through academic research and make language models more efficient for lower-level applications. . To this end, two works of the team are highlighted. One is a new training method for language models called TRIME, and the other is an effective model pruning method suitable for downstream tasks called CofiPruning.

Paper address: https:/ /arxiv.org/abs/2205.12674
#The training process of the traditional language model is as follows: given a document, input it into the Transformer encoder to obtain the hidden vector, and then These latent vectors are fed to the softmax layer, which outputs a matrix composed of V word embedding vectors, where V represents the size of the vocabulary. Finally, these output vectors can be used to predict the original text and compare it with the standard of the given document. The answers are compared to calculate the gradient and implement backpropagation of the gradient. However, such a training paradigm will bring about the following problems: (1) A huge Transformer encoder will bring high training costs; (2) The input length of the language model is fixed, and the calculation amount of the Transformer will increase squarely with the change of the sequence length. level growth, so it is difficult for Transformer to handle long texts; (3) Today's training paradigm is to project the text into a fixed-length vector space to predict the next words. This training paradigm is actually a bottleneck of the language model.

To this end, Chen Danqi’s team proposed a new training paradigm - TRIME, which mainly uses batch memory for training, and based on this, three shared identical training goals were proposed The language models of functions are TrimeLM, TrimeLMlong and TrimeLMext. TrimeLM can be seen as an alternative to standard language models; TrimeLMlong is designed for long range text, similar to Transformer-XL; TrimeLMext combines a large data store, similar to kNN-LM. Under the training paradigm mentioned above, TRIME first defines the input text as  , then transmits the input to the Transformer encoder
, then transmits the input to the Transformer encoder  , and obtains the latent vector
, and obtains the latent vector  , after passing the softmax layer
, after passing the softmax layer  , the next word that needs to be predicted is obtained
, the next word that needs to be predicted is obtained  . The trainable parameters in the entire training paradigm are
. The trainable parameters in the entire training paradigm are  and E. The work of Chen Danqi’s team was inspired by the following two works: (1) The continuous cache algorithm proposed by Grave et al. in 2017. This algorithm trains a common language model during the training process
and E. The work of Chen Danqi’s team was inspired by the following two works: (1) The continuous cache algorithm proposed by Grave et al. in 2017. This algorithm trains a common language model during the training process ; during the inference process, given the input text
; during the inference process, given the input text , first enumerate the given text The tag positions of all previously occurring words and all of them equal to the next word need to be predicted, and then the cache distribution is calculated using the similarity between latent variables and the temperature parameter. In the testing phase, linear interpolation of the language model distribution and cache distribution can achieve better experimental results.
, first enumerate the given text The tag positions of all previously occurring words and all of them equal to the next word need to be predicted, and then the cache distribution is calculated using the similarity between latent variables and the temperature parameter. In the testing phase, linear interpolation of the language model distribution and cache distribution can achieve better experimental results.

(2) The k-nearest neighbor language model (kNN-LM) proposed by Khandelwal et al. in 2020, This method is consistent with The continuous caching algorithm is similar. The biggest difference between the two is that kNN-LM constructs a data storage area for all training samples. In the testing phase, k-nearest neighbor search will be performed on the data in the data storage area to select the best top -k data. 
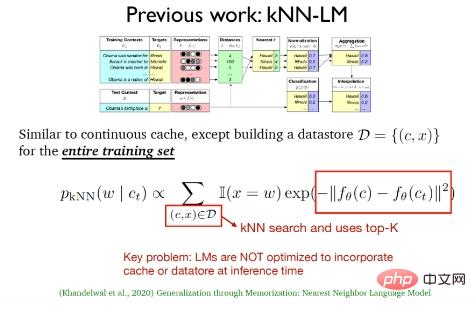
The above two works actually only used the cache distribution and k-nearest neighbor distribution in the testing phase, and only continued them during the training process. Traditional language models do not optimize the combination of cache and data storage during the inference phase.
In addition, there are some language model works for very long texts worthy of attention, such as the Transformer-XL proposed in 2019 that combines the attention recurrence (Attention recurrence) mechanism. and Compressive Transformers based on memory compression proposed in 2020.
Based on several previously introduced works, Chen Danqi’s team constructed a language model training method based on batch memory. The main idea is to build a working memory for the same training batch. (working memory). For the task of predicting the next word from a given text, the idea of TRIME is very similar to contrastive learning. It not only considers the task of using the softmax word embedding matrix to predict the probability of the next word, but also adds a new module. In this module Consider all other texts that appear in the training memory and have the same word as the given text that needs to be predicted.

Therefore, the training objective function of the entire TRIME includes two parts:
(1) Based on the output Word embedding matrix prediction task.
(2) Share the similarity of the same word text to be predicted in the training memory (training memory), where the vector representation that needs to measure the similarity is passed through the final feed-forward layer Input, scaled dot product is used to measure vector similarity.
The algorithm hopes that the final trained network can achieve the final predicted word as accurately as possible, and at the same time, the texts sharing the same word to be predicted in the same training batch are as similar as possible, so that the training process is In this method, all text memory representations are implemented through backpropagation to achieve end-to-end neural network learning. The implementation idea of the algorithm is largely inspired by the dense retrieval proposed in 2020. Dense retrieval aligns queries and positively related documents in the training phase and uses documents in the same batch as negative samples, and extracts data from large data in the inference phase. Retrieve relevant documents from the storage area.

The inference phase of TRIME is almost the same as the training process. The only difference is that different test memories may be used, including local memory. , long-term memory (Long-term memory) and external memory (External memory). Local memory refers to all words that appear in the current segment and have been vectorized by the attention mechanism; long-term memory refers to text representations that cannot be directly obtained due to input length limitations but originate from the same document as the text to be processed. Memory refers to the large data storage area that stores all training samples or additional corpora. 
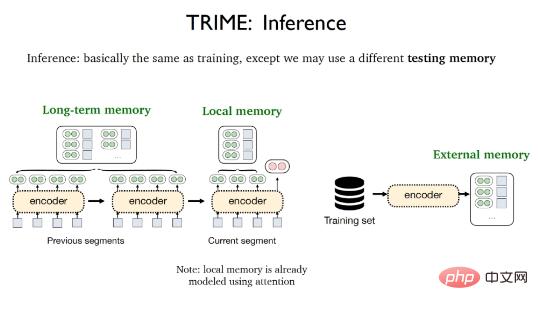
In order to minimize the inconsistency between the training and testing phases, certain data processing strategies need to be adopted to better construct Train your memory. Local memory refers to previous tokens in the same data fragment and is extremely cheap to use. Random sampling batch processing can be used to directly utilize local memory in the training phase and testing phase at the same time. This results in a basic version of the TrimeLM model based on local memory.

Long-term memory refers to tags in previous fragments of the same document and needs to rely on previous fragments of the same document. For this purpose, consecutive segments (consecutive segments) in the same document are put into the same training batch, which results in the TrimeLMlong model of collective long-term memory.

#External memory needs to be retrieved in conjunction with large data stores. For this purpose, BM25 can be used to put similar segments in the training data into the same training batch, which results in the TrimeLMext model combined with external memory.

To sum up, the traditional language model does not use memory in the training phase and the testing phase; the continuous caching method only uses local memory or long-term memory in the testing phase; the k-nearest neighbor language model uses memory in the testing phase. External memory; the three language models for the TRIME algorithm all use memory enhancement methods in the training phase and the testing phase. Among them, TrimeLM uses local memory in both the training phase and the testing phase, and TrimeLMlong targets the continuous processing of the same document in the training phase. Fragments are put into the same batch for training, and local memory and long-term memory are combined in the testing phase. TrimeLMext is put into the same batch for training for similar documents during the training phase, and local memory, long-term memory, and external memory are combined in the testing phase.

In the experimental stage, when testing the model parameter 247M and the slice length 3072 on the WikiText-103 data set, three methods based on the TRIME algorithm Both versions of the language model can achieve better perplexity effects than the traditional Transformer, among which the TrimeLMext model based on actual distance can achieve the best experimental results. At the same time, TrimeLM and TrimeLMlong can also maintain a retrieval speed close to that of the traditional Transformer, while having the advantages of perplexity and retrieval speed.

When testing the model parameter 150M and the slice length 150 on the WikiText-103 data set, you can see that TrimeLMlong targets the same Continuous fragments of documents are put into the same batch of training, and local memory and long-term memory are combined in the test phase. Therefore, although the slice length is only 150, the actual available data in the test phase can reach 15,000, and the experimental results are far better than other baseline models. .

For character-level language model construction, the language model based on the TRIME algorithm also achieved the best experimental results on the enwik8 data set. In the application task of machine translation, TrimeMT_ext also achieved experimental results that exceeded the baseline model.

In summary, the language model based on the TRIME algorithm adopts three memory construction methods, making full use of relevant data within the same batch. Memory enhancement introduces memory without introducing a large amount of computational cost, and does not change the overall structure of the model. Compared with other baseline models, it has achieved better experimental results.
Chen Danqi also focused on the retrieval-based language model. In fact, TrimeLMext can be regarded as a better version of the k-nearest neighbor language model, but in the inference process these two algorithms Compared with other baseline models, it is nearly 10 to 60 times slower, which is obviously unacceptable. Chen Danqi pointed out one of the possible future development directions of retrieval-based language models: whether it is possible to use a smaller retrieval encoder and a larger data storage area to reduce the computational cost to nearest neighbor search.
Compared with traditional language models, retrieval-based language models have significant advantages. For example, retrieval-based language models can better update and maintain, while traditional language models The model cannot achieve dynamic updating of knowledge because it uses previous knowledge for training; at the same time, the retrieval-based language model can also be better utilized in privacy-sensitive fields. As for how to make better use of retrieval-based language models, teacher Chen Danqi believes that fine-tuning, prompting or in-context learning may be used to assist in the solution. 

##Paper address: https://arxiv.org/abs/2204.00408
Model compression technology is widely used in large language models, allowing smaller models to be more quickly adapted to downstream applications. Among them, the traditional mainstream model compression methods are distillation (Distillation) and pruning (pruning). For distillation, it is often necessary to predefine a fixed student model. This student model is usually randomly initialized, and then the knowledge is transferred from the teacher model to the student model to achieve knowledge distillation.
For example, starting from the original version of BERT, after general distillation, that is, after training on a large number of unlabeled corpora, the basic version of TinyBERT4 can be obtained. For the basic version of TinyBERT4, Fine-tuned TinyBERT4 can also be obtained through the task-driven distillation method. The final model can be smaller and faster than the original BERT model at the expense of slight accuracy. However, this method based on distillation also has certain flaws. For example, for different downstream tasks, the model architecture is often fixed; at the same time, it needs to be trained from scratch using unlabeled data, which is too computationally expensive.

For pruning, it is often necessary to start from a teacher model and then continuously remove irrelevant parts from the original model. Unstructured pruning proposed in 2019 can obtain smaller models but has little improvement in running speed, while structured pruning achieves speed improvements in practical applications by removing parameter groups such as feedforward layers, such as in 2021 The proposed block pruning can achieve 2-3 times speed improvement.


To address the limitations of traditional distillation and pruning methods, Chen Danqi’s team proposed an algorithm called CofiPruning , We prune coarse-grained units and fine-grained units at the same time, and design a layer-by-layer distillation objective function to transfer knowledge from the unpruned model to the pruned model, and ultimately can maintain more than 90 On the basis of % accuracy, it achieves a speed increase of more than 10 times, and is less computationally expensive than traditional distillation methods.
The proposal of CofiPruning is based on two important basic works:
(1) The speed achieved by pruning the entire layer For improvement, related work points out that about 50% of the neural network layers can be pruned, but coarse-grained pruning has a greater impact on accuracy.
(2) Pruning smaller units such as the head can achieve better flexibility, but this method will be a more difficult optimization problem in implementation. , and there will not be much speed improvement.
For this reason, Chen Danqi’s team hopes to be able to prune both coarse-grained units and fine-grained units at the same time, thereby taking advantage of both granularities. In addition, in order to solve the problem of data transfer from the original model to the pruned model, CofiPruning adopts a layer-by-layer alignment method to transfer knowledge during the pruning process. The final objective function includes distillation loss and sparsity-based lag. Long day loss.

#In the experimental stage, on the GLUE data set for sentence classification tasks and the SQuAD1.1 data set for question and answer tasks, it can be found that CofiPruning has Outperforms all distillation and pruning baseline methods at the same speed and model size.

For TinyBERT, if universal distillation is not used, the experimental effect will be greatly reduced; but if universal distillation is used, although the experimental effect can be improved, the training time cost will be very expensive. The CofiPruning algorithm can not only achieve almost the same effect as the baseline model, but also greatly improve the running time and computational cost, and can achieve faster processing speed with less computational cost. Experiments show that for coarse-grained units, the first and last feed-forward layers will be retained to the greatest extent while the middle layers are more likely to be pruned; for fine-grained units, the head and middle dimensions of the upper neural network More likely to be pruned.

In summary, CofiPruning is a very simple and effective model compression algorithm that jointly prunes coarse-grained units and fine-grained units. , combined with the objective function of layer-by-layer distillation, the advantages of the two algorithms, structural pruning and knowledge distillation, can be combined to achieve faster processing speed and smaller model structure. Regarding the future trend of model compression, Chen Danqi also focused on whether large language models such as GPT-3 can be pruned, and whether upstream tasks can be pruned. These are research ideas that can be focused on in the future.
Large-scale language models have now achieved very gratifying practical application value, but due to expensive environmental and economic costs, Concerns about privacy and fairness, as well as the difficulty of real-time updates, mean that large language models still have much to be improved. Chen Danqi believes that future language models may be used as large-scale knowledge bases. At the same time, the scale of language models needs to be greatly reduced in the future. Retrieval-based language models or sparse language models may be used to replace dense retrieval and model compression. The work also requires researchers to focus on.
The above is the detailed content of Princeton Chen Danqi: How to make 'big models” smaller. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



