



We mentioned many years ago that training AI workloads using convolutional neural networks with sufficient data is becoming a growing trend. Mainstream, and major HPC (high-performance computing) centers around the world have been handing over this load to NVIDIA's GPU processing for many years. For tasks such as simulation and modeling, GPU performance is quite outstanding. In essence, HPC simulation/modeling and AI training are actually a kind of harmonic convergence, and GPUs, as massively parallel processors, are particularly good at performing this type of work.
But since 2012, the AI revolution officially broke out, and image recognition software improved the accuracy to a level beyond that of humans for the first time. So we are very curious about how long the commonality of efficient processing of HPC and AI on similar GPUs can last. So in the summer of 2019, through refinement and iteration of the model, we tried to use the mixed-precision math unit to achieve the same results as FP64 calculations in the Linpack benchmark. Before Nvidia launched the "Ampere" GA100 GPU the following year, we once again tried to test the processing performance of HPC and AI. At the time, Nvidia hadn't yet launched its "Ampere" A100 GPU, so the graphics card giant hadn't officially tilted toward training AI models on mixed-precision tensor cores. The answer is of course now clear. HPC workloads on FP64 vector units require some architectural adjustments to maximize GPU performance. There is no doubt that they are a bit of a "second-class citizen". But at that time, everything was still possible.
With the launch of Nvidia’s “Hopper” GH100 GPU earlier this year, there is a wider gap in intergenerational performance improvements between AI and HPC. Not only that, at the recent autumn GTC 2022 conference, Nvidia co-founder and CET Huang Jensen said that the AI workload itself has also become divergent, forcing Nvidia to start exploring the CPU business-or, more accurately, it should be called GPU-oriented Optimized extended memory controller.
We will discuss this issue in detail later.
Let us start with the clearest judgment. If Nvidia wants its GPU to have stronger FP64 performance to support 64-bit floating point HPC applications such as weather modeling, fluid dynamics calculations, finite element analysis, quantum chromodynamics and other high-intensity mathematical simulations, then the accelerator The design idea should be like this: create a product that does not have any tensor cores or FP32 CUDA cores (mainly used as graphics shaders in the CUDA architecture).
But I am afraid that only a few hundred customers are willing to purchase such a product, so the price of a single chip may be tens of thousands or even hundreds of thousands of dollars. Only in this way can the design and manufacturing costs be covered. In order to build a larger and more profitable business, Nvidia must design a more general architecture whose vector math capabilities are simply stronger than those of CPUs.
So ever since NVIDIA decided to seriously design products for HPC applications 15 years ago, they have been focusing on HPC scenarios that use FP32 floating point math operations - including use in seismic processing, signal processing, and genomics workloads. single-precision data and processing tasks, and gradually improve the FP64 capabilities of the GPU.
The K10 accelerator launched in July 2012 is equipped with two "Kepler" GK104 GPUs, which are identical to the GPUs used in gaming graphics cards. It has 1536 FP32 CUDA cores and does not use any dedicated FP64 cores. Its FP64 support is done purely in software, so it doesn't allow for significant performance gains: the dual GK104 GPUs performed at 4.58 teraflops on FP32 tasks and 190 gigaflops on FP64, a ratio of 24 to 1. The K20X, released at the SC12 Supercomputing Conference at the end of 2012, uses the GK110 GPU, with FP32 performance of 3.95 teraflops and FP64 performance of 1.31 teraflops, a ratio increased to 3:1. By this time, the product has initial availability for HPC applications and users training AI models in the academic/hyperscale computing space. The K80 GPU accelerator card uses two GK110B GPUs. This is because NVIDIA did not add FP64 support to the highest-end "Maxwell" GPU at the time, so GK110 B became the most popular and cost-effective option at the time. The K80's FP32 performance is 8.74 teraflops and FP64 performance is 2.91 teraflops, still maintaining a 3-to-1 ratio.
To the "Pascal" GP100 GPU, the gap between HPC and AI has further widened with the introduction of the FP16 mixed precision indicator, but the ratio of vector FP32 to vector FP64 has further converted to 2:1, and in "Volta" It has been maintained in newer GPUs such as the "Ampere" GA100 and the "Hopper" GH100 after the GV100. In the Volta architecture, NVIDIA introduced for the first time the Tensor Core matrix mathematics unit with fixed matrix Lei, which significantly improved floating point (and integer) computing capabilities and continued to retain vector units in the architecture.
These tensor cores are used to process larger and larger matrices, but the specific calculation accuracy is getting lower and lower, so this type of equipment has achieved extremely exaggerated AI load throughput. This is of course inseparable from the fuzzy statistical nature of machine learning itself, and it also leaves a huge gap with the high-precision mathematics required by most HPC algorithms. The figure below shows the logarithmic representation of the performance gap between AI and HPC. I believe you can already see the trend difference between the two:
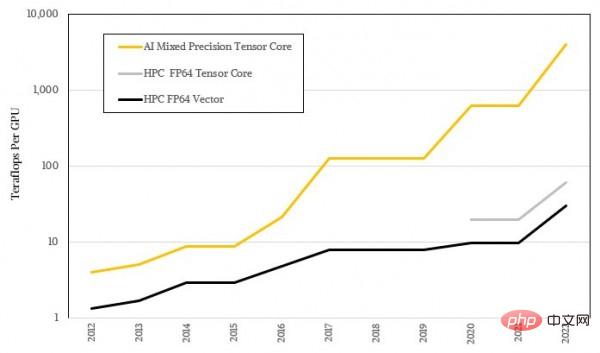
The logarithmic form doesn’t look impressive enough, let’s look at it again using the actual ratio:
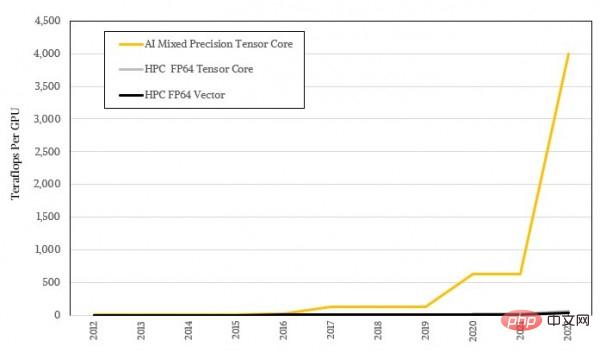
System The Art of Design: When HPC and AI applications become mainstream, where should the GPU architecture go?
Not all HPC applications can be adjusted for tensor cores, and not all applications can transfer mathematical operations to tensor cores, so Nvidia still retains some vector units in its GPU architecture. In addition, many HPC organizations cannot actually come up with iterative solvers like HPL-AI. The HPL-AI solver used in the Linpack benchmark test uses regular HPL Linpack with FP16 plus FP32 operations, and a little bit of FP64 operations to converge to the same answer as pure FP64 brute force calculations. This iterative solver is capable of delivering an effective speedup of 6.2x on Oak Ridge National Laboratory's Frontier supercomputer and 4.5x on RIKEN Laboratory's Fugaku supercomputer. If more HPC applications can receive their own HPL-AI solvers, then the problem of "separation" of AI and HPC will be solved. I believe this day will come.
But at the same time, for many workloads, FP64 performance remains the only deciding factor. And Nvidia, which has made a lot of money with its powerful AI computing power, will definitely not have much time to take care of the HPC market in a short period of time.
It can be seen that Nvidia’s GPU architecture mainly pursues higher AI performance while maintaining acceptable HPC performance, and uses a two-pronged approach to guide customers every day. Hardware is updated every three years. From a pure FP64 performance perspective, the FP64 throughput of Nvidia GPUs increased 22.9 times in the ten years from 2012 to 2022, from 1.3 teraflops of the K20X to 30 teraflops of the H100. If the tensor core matrix unit can be used with the iterative solver, the increase can reach 45.8 times. But if you are an AI training user who only needs low-precision large-scale parallel computing, then the performance change from FP32 to FP8 is exaggerated. The computing power of the earliest FP32 has been increased from 3.95 teraflops to 4 petaflops of FP8 sparse matrix, which is an improvement. 1012.7 times. And if we compare it with the FP64-encoded AI algorithm on the K20X GPU at the time (the mainstream practice at the time), the performance improvement in the past ten years is only a pitiful 2 times.
Obviously, the performance difference between the two cannot be described as huge. Huang Renxun himself also mentioned that the current AI camp itself is divided into two again. One type is a giant basic model supported by the transformer model, also known as a large language model. The number of parameters of such models is growing rapidly, and the demand for hardware is also increasing. Compared with the previous neural network model, today's transformer model completely represents another era, as shown in the following figure:

Please forgive this picture for being a bit blurry, but the point is Here’s the thing: For the first set of AI models that did not include transformers, the computing requirements increased 8 times in two years; but for the AI models that included transformers, the computing requirements increased by 275 times in two years. If floating point operations are used for processing, then there must be 100,000 GPUs in the system to meet the demand (this is not a big problem). However, switching to FP4 precision will double the amount of calculations. In the future, when the GPU uses 1.8nm transistors, the computing power will increase by about 2.5 times, so there is still a gap of about 55 times. If FP2 operations could be implemented (assuming such accuracy is sufficient to solve the problem), the amount of calculation could be halved, but that would require the use of at least 250,000 GPUs. Moreover, large language transformer models are often difficult to expand, especially not economically feasible. Therefore, this type of model has become exclusive to giant companies, just like nuclear weapons are only in the hands of powerful countries.
As for the recommendation system as a "digital economic engine", it requires not only an exponential increase in the amount of calculations, but also a data scale that far exceeds the memory capacity of a large language model or even a GPU. Huang Renxun mentioned in his previous GTC keynote speech:
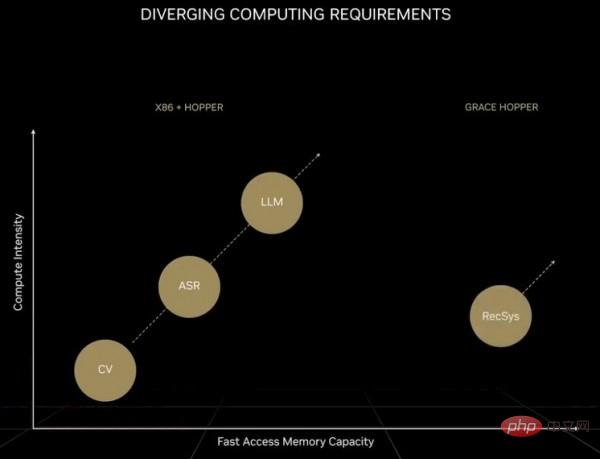
"Compared with the large language model, the amount of data faced by each computing unit when processing the recommendation system is an order of magnitude larger. Obviously, the recommendation system not only requires faster memory speed, but also requires 10 times that of the large language model The memory capacity of the model. Although large language models maintain exponential growth over time and require constant computing power, recommendation systems also maintain this growth rate and continue to consume more memory capacity. Large language models and recommendation systems can be said to be the two most important types of AI models today, and have different computing requirements. Recommendation systems can scale to billions of users and billions of items, every article, every video, every social post Each embedding table may contain tens of terabytes of data and needs to be processed by multiple GPUs. When processing recommendation systems, some parts of the network are required to implement data parallel processing. , and requires other parts of the network to implement model parallel processing, which puts forward higher requirements for various parts of the computer."
As shown in the figure below, it is the basic architecture of the recommendation system:
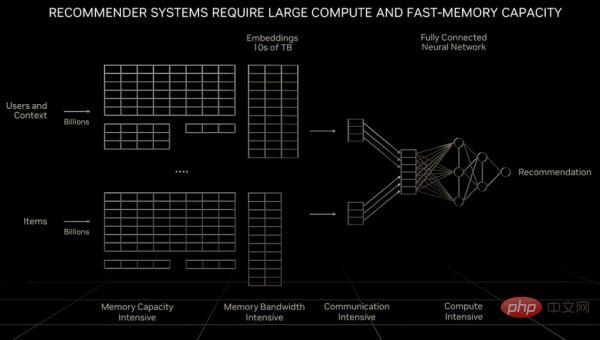
To understand the specific memory capacity and bandwidth issues that determine this, NVIDIA developed the "Grace" Arm server CPU and tightly coupled it with the Hopper GPU. We also joke that if the amount of main memory required is very large, Grace is actually just Hopper's memory controller. But in the long run, maybe just hook a bunch of CXL ports running the NVLink protocol into Hooper's next-generation GPU.
So the Grace-Hopper super chip produced by NVIDIA is equivalent to putting a "child" level CPU cluster into a huge "adult" level GPU acceleration cluster. These Arm CPUs can support traditional C and Fortran workloads, but at a price: the performance of the CPU part in the hybrid cluster is only one-tenth of the performance of the GPU in the cluster, but the cost is 3 to 3 times that of a conventional pure CPU cluster. 5 times.
By the way, we respect and understand any engineering choices made by NVIDIA. Grace is an excellent CPU, and Hopper is also an excellent GPU. The combination of the two will definitely produce good results. But what's happening now is that we're facing three distinct workloads on the same platform, each pulling the architecture in a different direction. High-performance computing, large language models and recommendation systems, these three brothers have their own characteristics, and it is simply impossible to optimize the architecture at the same time in a cost-effective manner.
And it is obvious that AI has great advantages, while HPC is gradually losing ground. This situation has lasted for nearly ten years. If HPC wants to complete its transformation, its code must move closer to recommendation systems and large language models, rather than continuing to insist on running existing C and Fortran code on FP64. And it is obvious that HPC customers have a premium for every operation compared to AI customers. So unless HPC experts figure out a universal development method for iterative solvers that can model the physical world with lower accuracy, it will be difficult to reverse this passive situation.
For decades, we have always felt that nature itself does not conform to mathematical laws. We are forced to use high-precision mathematics to describe the effects of nature, or we are using unsuitable language to describe objective reality. Of course, nature may be more subtle than we imagine, and iterative solvers are closer to the reality we want to model. If this is the case, it may be a blessing for mankind, even luckier than the accidental coincidence of HPC and AI ten years ago.
After all, there is no road in the world. When there are more people walking, it becomes a road.
The above is the detailed content of The Art of System Design: When HPC and AI applications become mainstream, where should GPU architecture go?. For more information, please follow other related articles on the PHP Chinese website!
 How to set transparency of html font color
How to set transparency of html font color What are the core technologies necessary for Java development?
What are the core technologies necessary for Java development? Common tools for software testing
Common tools for software testing The difference between vivox100s and x100
The difference between vivox100s and x100 c++sort sorting function usage
c++sort sorting function usage netframework
netframework How to create an encyclopedia entry
How to create an encyclopedia entry What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



