


This article brings you relevant knowledge aboutPython, which mainly introduces practical records of some problems in saving and loading pytorch models. Let’s take a look at them together. I hope it will be helpful to everyone. help.

[Related recommendations:Python3 video tutorial]
torch.save(model,path) torch.load(path)
torch.save(model.state_dict(),path) model_state_dic = torch.load(path) model.load_state_dic(model_state_dic)
When the model is saved, the path to the model structure definition file will be recorded. , when loading, it will be parsed according to the path and the parameters will be loaded; when the model definition file path is modified, an error will be reported when using torch.load(path).

After changing the model folder to models, an error will be reported when loading again.
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)
In this way of saving the complete model structure and parameters, be sure not to change the model definition file path.
If there are multiple graphics cards on a multi-card machine, starting from 0, the model is now n>= After the graphics card training on 1 is saved, the copy is loaded on a single-card machine
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)
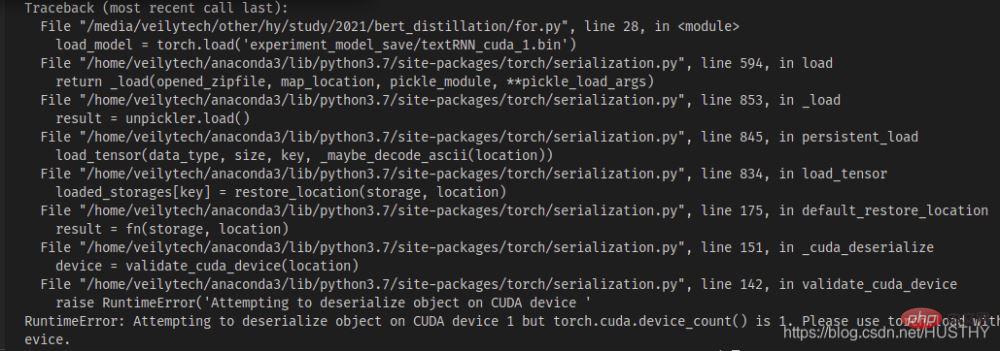
There will be a cuda device mismatch problem - the model code segment widget type you saved If you use cuda1, then when you use torch.load() to open it, it will look for cuda1 by default, and then load the model to the device. At this time, you can directly use map_location to solve the problem and load the model onto the CPU.
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
When using multiple GPUs to train the model at the same time, whether the model structure and parameters are saved together or separately Model parameters will cause problems when loading under a single card
a. Save the model structure and parameters together and then use them when loading

torch.distributed.init_process_group(backend='nccl')
The above-mentioned multi-process method, so you must declare it when loading, otherwise an error will be reported.
b. Saving model parameters separately
model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)
The same problem will occur, but the problem here is that the key of the parameter dictionary is different from the key defined by the model

The reason is that under multi-GPU training, when using distributed training, the model will be packaged. The code is as follows:
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin') print(model) model.cuda(args.local_rank) 。。。。。。 model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True) print('model',model)
Model structure before packaging:

Packaged model
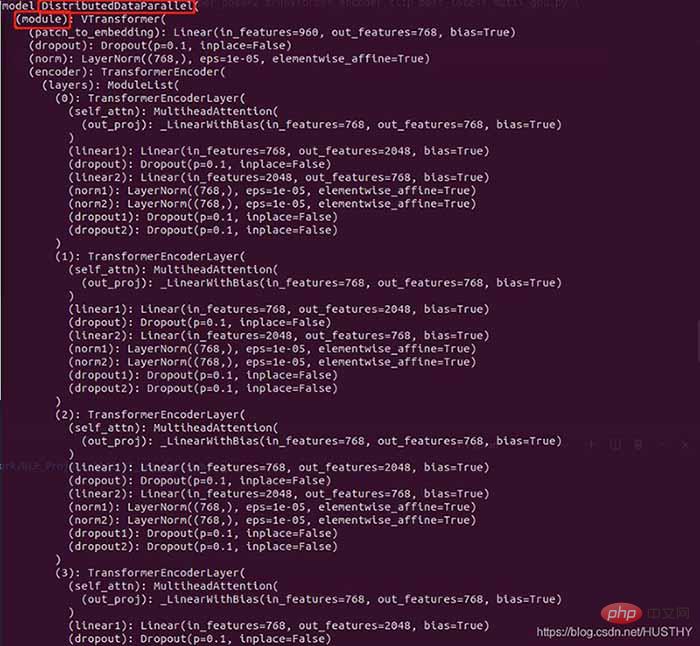
There are more DistributedDataParallel and modules in the outer layer, so the weight will appear when loading the model weight in a single card environment The keys are inconsistent.
if gpu_count > 1: torch.save(model.module.state_dict(),save_path) else: torch.save(model.state_dict(),save_path) model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load(save_path) model.load_state_dict(state_dict)
This is a better paradigm, and there will be no error in loading.
【Related recommendations:Python3 video tutorial】
The above is the detailed content of Practical records of some problems in saving and loading pytorch models. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



