##Full-text | Supported after version 5.6 | Supported
##Not supported |
|
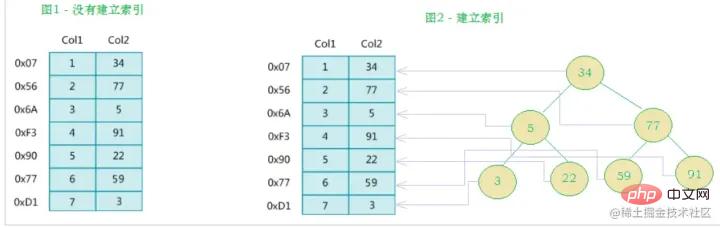
What we usually call indexes, unless otherwise specified, refers to indexes organized in a B-tree (multi-way search tree, not necessarily binary) structure. Among them, clustered index, compound index, prefix index and unique index all use B tree index by default, collectively called index.
BTREE
Multi-path balanced search tree, an m-order (m-fork) BTREE satisfies:
- Each node has a maximum of m children. Number of children: ceil(m/2) to m Number of keywords: ceil(m/2)-1 to m-1
ceil means rounding up, ceil(2.3)=3
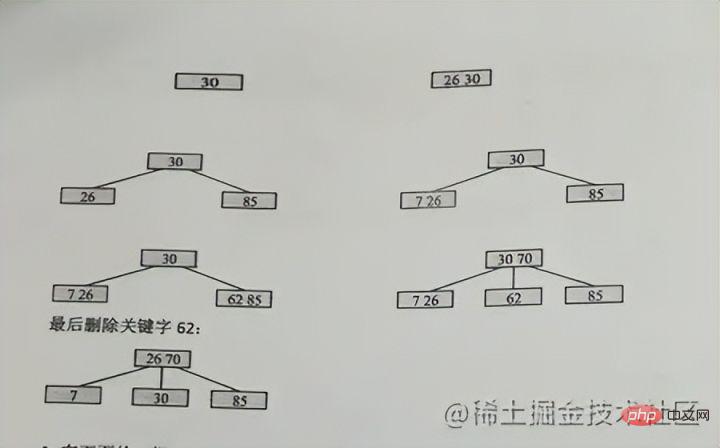
Insert keyword case

Guarantee not to destroy the properties of the m-order B-tree
Due to the 3rd order, it can only be 2 at most nodes, so 26 and 30 are together at the beginning, and then 85 will start to split. 30 will be the upper position in the middle, 26 will remain, and 85 will go to the right
, that is: the upper position in the middle , and then The left side stays at the old node, and the right side goes to the new node
When 70 is inserted in the picture, 70 happens to be in the middle position, then 62 is maintained, and 85 is divided into a new node.
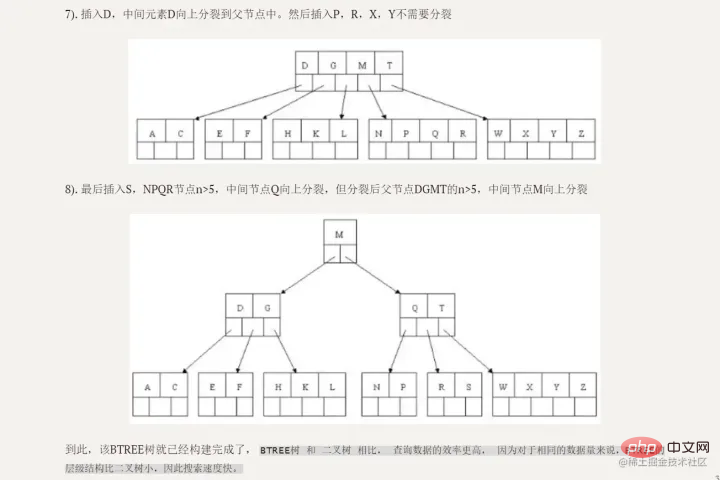
After ascending, you need to split again
Just continue to split upwards, the same thing
Comparative advantages
Compared with binary search trees, the height/depth is lower and the natural query efficiency is higher.
B TREE
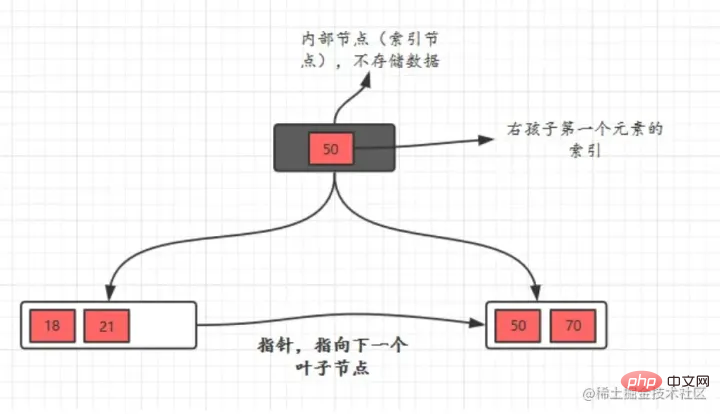
- B tree has two types of nodes: internal nodes (also called index nodes) and leaf nodes. Internal nodes are non-leaf nodes. Internal nodes do not store data, only indexes, and data are stored in leaf nodes.
- The keys in the internal nodes are arranged in order from small to large. For a key in the internal node, all keys in the left tree are smaller than it, and in the right subtree The keys are all greater than or equal to it. Records in leaf nodes are also arranged according to key size.
- Each leaf node stores pointers to adjacent leaf nodes. The leaf nodes themselves are connected in order from small to large according to the size of the keyword.
The parent node stores the index - of the first element of the right child.
Compared advantages
The query efficiency of B Tree is - more stable. Since only leaf nodes of B Tree store key information, querying any key requires going from the root to the leaves, so it is more stable.
You can traverse the entire tree by just traversing the leaf nodes. -
B Tree in MySQLMySql index data structure optimizes the classic B Tree. On the basis of the original B Tree, a linked list pointer pointing to the adjacent leaf node (the overall structure is similar to a doubly linked list) is formed to form a B Tree with a sequential pointer to improve the performance of interval access.
Careful students can see that what is the biggest difference between this picture and our binary search tree diagram?
Transitioning from - binary search tree to B-tree, there is a significant change that one node can store multiple data, which is equivalent to one disk block can store multiple data. data, greatly reducing our IO times! !
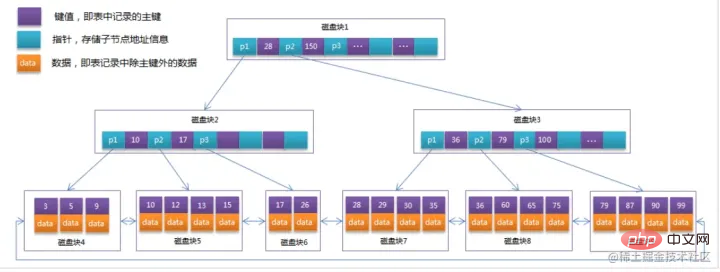
B Tree index structure diagram in MySQL:
Binary search tree diagram:
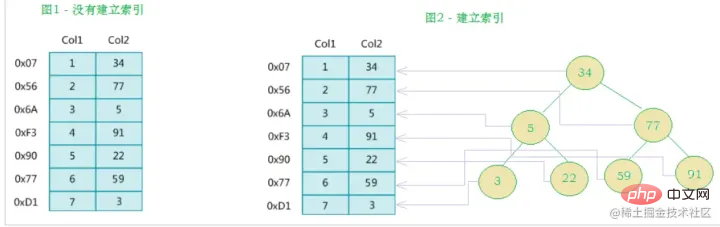
Index principleBTree index:Initialization introductionThe light blue one is called a disk block. You can see how many disk blocks each disk block contains. data items (shown in dark blue) and pointers (shown in yellow) For example, disk block 1 contains data items 17 and 35, including pointers P1, P2, and P3.
P1 represents a disk block less than 17, and P2 Represents disk blocks between 17 and 35, P3 represents disk blocks greater than 35.
-
The real data exists in the leaf nodesThat is, 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. `
- Non-leaf nodes do not store real data, only data items that guide the search direction, such as 17 and 35 do not actually exist in the data table. `
Search process
If you want to find data item 29, then disk block 1 will first be loaded from the disk to the memory, and an IO will occur at this time. Use a binary search in the memory to determine that 29 is between 17 and 35, and lock the P2 pointer of disk block 1. The memory time is negligible because it is very short (compared to the IO of the disk). Use the disk address of the P2 pointer of disk block 1 to Disk block 3 is loaded from the disk into the memory. The second IO occurs. 29 is between 26 and 30. The P2 pointer of disk block 3 is locked. Disk block 8 is loaded into the memory through the pointer. The third IO occurs. At the same time, the memory passes The binary search reaches 29 and ends the query, resulting in a total of three IOs.
The real situation is that a 3-layer B-tree can represent millions of data. If millions of data searches only require three IOs, the performance improvement will be huge. If there is no index, each data If an IO occurs for each item, a total of millions of IOs will be required. Obviously, the cost is very, very high.
Index classification
In InnoDB, tables are stored in the form of indexes according to the order of primary keys. Tables stored in this way are called index-organized tables. And because we mentioned earlier, InnoDB uses the B-tree index model, so the data is stored in the B-tree.
Each index corresponds to a B-tree in InnoDB.
Assume that we have a table with the primary key column as ID, there is field k in the table, and there is an index on k.
The table creation statement of this table is:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
复制代码
Copy after login
The (ID,k) values of R1~R5 in the table are (100,1), (200,2), (300,3), (500,5) and (600,6), the example diagrams of the two trees are as follows:
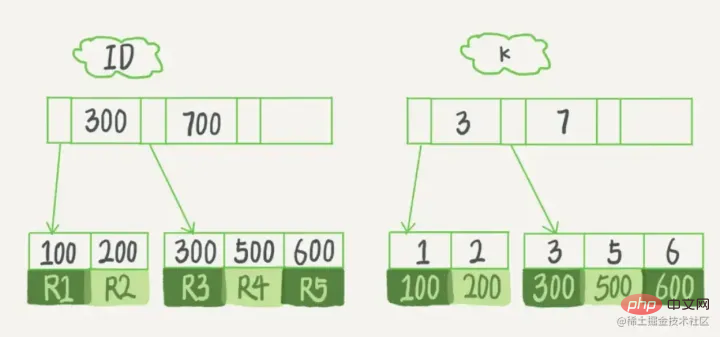
It is not difficult to see from the figure that according to the contents of the leaf nodes , index types are divided into primary key indexes and non-primary key indexes.
Primary key index
The primary key column of the data table uses the primary key index and will be created by default. This is why, before we learned indexing, the teacher often told us to query based on the primary key. It will be faster. It turns out that the primary key itself is indexed.
The leaf node of the primary key index stores the entire row of data. In InnoDB, the primary key index is also called clustered index (clustered index).
Auxiliary index
The leaf node content of the auxiliary index is the value of the primary key. In InnoDB, the auxiliary index is also called Secondary index (secondary index).
As shown below:
- The primary key index stores the entire row of data
- The auxiliary index only stores itself and the id The primary key is used for table query
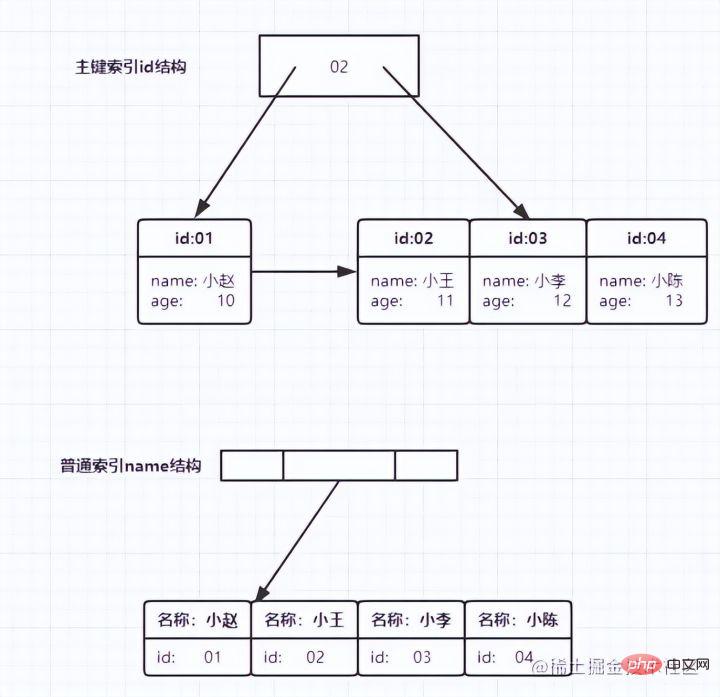
According to the above index structure, let’s discuss a question: What is the difference between queries based on primary key index and auxiliary index ?
- If the statement is select * from T where ID=500, which is the primary key query method, you only need to search the B tree of ID;
- If the statement It is select * from T where k=5, which is the ordinary index query method. You need to search the k index tree first, and get the ID value of 500. then search once in the ID index tree . This process is called Returning to the table.
In other words, queries based on auxiliary indexes need to scan one more index tree. Therefore, we should try to use primary key queries in our applications.
Unless the data we want to query happens to exist on our index tree, at this time we call it covering index-that is, the index column contains our All data to be queried.
At the same time, secondary indexes are divided into the following types (just skip it briefly, and we will learn more about it later):
-
Unique Key (Unique Key): The unique index is also a constraint. The attribute column of the unique index cannot have duplicate data, but the data is allowed to be NULL. A table allows the creation of multiple unique indexes. Most of the time, the purpose of establishing a unique index is for the uniqueness of the data in the attribute column, not for query efficiency.
-
Ordinary Index (Index): The only function of an ordinary index is to quickly query data. A table allows the creation of multiple ordinary indexes, and allows data duplication and NULL.
-
Prefix index (Prefix): Prefix index is only applicable to string type data. The prefix index creates an index on the first few characters of the text. Compared with the ordinary index, the data created is smaller because only the first few characters are fetched.
-
Full Text Index (Full Text): Full text index is mainly used to retrieve keyword information in large text data. It is a technology currently used by search engine databases. Before Mysql5.6, only the MYISAM engine supported full-text indexing. After 5.6, InnoDB also supported full-text indexing
Extension--Index pushdown
The so-called pushdown, as the name suggests, is actually Postpone our table return operation, MySQL will not let us easily return the table, because it is very wasteful. What does that mean? Consider the following example.
We have established a composite index (name, status, address), which is also stored according to this field, similar to the picture:
Compound index tree (only stores the index column and The primary key is used to return the table)
name |
##status
|
address
|
id(primary key)
|
| Xiaomi 1
|
0
|
1
|
1
|
##Xiaomi 2 | 1 | 1 | 2 |
我们执行这样一条语句:
SELECT name FROM tb_seller WHERE name like '小米%' and status ='1' ;
复制代码
Copy after login
- 首先我们在复合索引树上,找到了第一个以小米开头的name -- 小米1
- 此时我们不着急回表(回到主键索引树搜索的过程,我们称为回表),而是先在复合索引树判断status是否=1,此时status=0,我们直接就不回表了,直接继续找下一个以小米开头的name
- 找到第二个-- 小米2,判断status=1,则根据id=2去主键索引树上找,得到所有的数据
这种先在自身索引树上判断是否满足其他的where条件,不满足则直接pass掉,不进行回表的操作,就叫做索引下推。
最左前缀原则
所谓最左前缀,可以想象成一个爬楼梯的过程,假设我们有一个复合索引:name,status,address,那这个楼梯由低到高依次顺序是:name,status,address,最左前缀,要求我们不能出现跳跃楼梯的情况,否则会导致我们的索引失效:
- 按楼梯从低到高,无出现跳跃的情况--此时符合最左前缀原则,索引不会失效

- 出现跳跃的情况
- 直接第一层name都不走,当然都失效
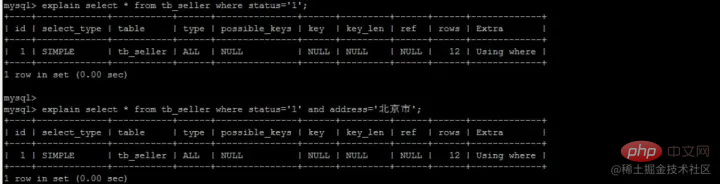
- 走了第一层,但是后续直接第三层,只有出现跳跃情况前的不会失效(此处就只有name成功)

- 同时,这个顺序并不是由我们where中的排列顺序决定,比如: where name='小米科技' and status='1' and address='北京市' where status='1' and name='小米科技' and address='北京市'
这两个尽管where中字段的顺序不一样,第二个看起来越级了,但实际上效果是一样的
其实是因为我们MySQL有一个Optimizer(查询优化器),查询优化器会将SQL进行优化,选择最优的查询计划来执行。
- 关于这个查询优化器,后续文章我们也会谈谈MySQL的逻辑架构与存储引擎
索引设计原则
针对表
- 查询频次高,且数据量多的表
针对字段
- 最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
- 最好用唯一索引,区分度越高,使用索引的效率越高
- 不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
比如:
我们创建了三个单列索引,name,status,address
当我们where中根据status和address两个字段来查询时,数据库只会选择最优的一个索引,不会所有单列索引都使用。
最优的索引:具体是指所查询表中,辨识度最高(所占比例最少)的索引列,比如此处address中有一个辨识度很高的 '西安市'数据;
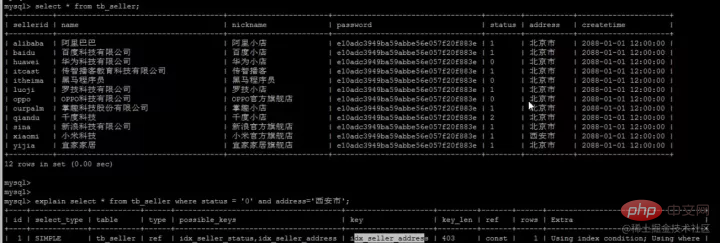
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
- 利用最左前缀,比如有N个字段,我们不一定需要创建N个索引,可以用复合索引
也就是说,我们尽量创建复合索引,而不是单列索引
创建复合索引:
CREATE INDEX idx_name_email_status ON tb_seller(name,email,status);
就相当于
对name 创建索引 ;
对name , email 创建了索引 ;
对name , email, status 创建了索引 ;
复制代码
Copy after login
举个栗子
假设我们有这么一个表,id为主键,没有创建索引:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB
复制代码
Copy after login
如果要在此处建立复合索引,我们要遵循什么原则呢?
通过调整顺序,可以少维护一个索引
- 比如我们的业务需求里边,有如下两种查询方式: 根据name查询 根据name和age查询
如果我们建立索引(age,name),由于最左前缀原则,我们这个索引能实现的是根据age,根据age和name查询,并不能单纯根据name查询(因为跳跃了),为了实现我们的需求,我们还得再建立一个name索引;
而如果我们通过调整顺序,改成(name,age),就能实现我们的需求了,无需再维护一个name索引,这就是通过调整顺序,可以少维护一个索引。
考虑空间->短索引
- 比如我们的业务需求里边,有以下两种查询方式: 根据name查询 根据age查询 根据name和age查询
我们有两种方案:
- 建立联合索引(name,age),建立单列索引:age索引。
- 建立联合索引(age,name),建立单列索引:name索引。
这两种方案都能实现我们的需求,这个时候我们就要考虑空间了,name字段是比age字段大的,显然方案1所耗费的空间是更小的,所以我们更倾向于方案1。
何时建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
何时达咩索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
-
数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为O(logn)退化了)
索引相关语法
创建索引
默认会为主键创建索引--primary
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
复制代码
Copy after login
查找索引
结尾加上\G,可以变成竖屏显示
select index from tbl_name\G;
复制代码
Copy after login
删除索引
drop INDEX index_name on tbl_name ;
复制代码
Copy after login
变更索引
1). alter table tb_name add primary key(column_list);
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
2). alter table tb_name add unique index_name(column_list);
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
3). alter table tb_name add index index_name(column_list);
添加普通索引, 索引值可以出现多次。
4). alter table tb_name add fulltext index_name(column_list);
该语句指定了索引为FULLTEXT, 用于全文索引
复制代码
Copy after login
查看索引使用情况
show status like 'Handler_read%'; -- 查看当前会话索引使用情况
show global status like 'Handler_read%'; -- 查看全局索引使用情况
复制代码
Copy after login
Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低越好)。
Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(这个值越高越好)。
Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。
Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
总结
- 索引简单来说就是一个排好序的数据结构,可以方便我们检索数据,而不需要盲目的进行全表扫描。
- 索引底层有很多种实现结构,这篇主要只是讲解了BTREE索引,如果对树这一数据结构还不太熟悉的小伙伴,可以关注我后续数据结构专栏,会整理关于普通树,二叉树,二叉排序树的文章。
- 索引分类:
- 主键索引
- 辅助索引
这里我们还扩展了索引下推,是一个十分重要的知识点,需要仔细回味。
- 索引的相关设计原则,索引虽好,但也不可贪杯,不能为了用索引而建索引。
- 索引的相关语法,很容易上手的。
- 查看索引的使用情况。
推荐学习:mysql视频教程





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



