


This article brings you relevant knowledge about python, which mainly introduces issues related to multi-threaded crawler development and common search algorithms. Let’s take a look at it together. I hope it will be helpful to everyone. help.

Recommended learning: python video tutorial
After mastering requests and regular expressions, you can start to actually crawl some simple URLs.
However, the crawler at this time has only one process and one thread, so it is called a single-threaded crawler. Single-threaded crawlers only visit one page at a time and cannot fully utilize the computer's network bandwidth. A page is only a few hundred KB at most, so when a crawler crawls a page, the extra network speed and the time between initiating the request and getting the source code are wasted. If the crawler can access 10 pages at the same time, it is equivalent to increasing the crawling speed by 10 times. In order to achieve this goal, you need to use multi-threading technology.
The Python language has a global interpreter lock (Global Interpreter Lock, GIL). This causes Python's multi-threading to be pseudo-multi-threading, that is, it is essentially a thread, but this thread only does each thing for a few milliseconds. After a few milliseconds, it saves the scene and changes to other things. After a few milliseconds, it does other things again. After one round, return to the first thing, resume the scene, work for a few milliseconds, and continue to change... A single thread on a micro scale is like doing several things at the same time on a macro scale. This mechanism has little impact on I/O (Input/Output, input/output) intensive operations, but on CPU calculation-intensive operations, since only one core of the CPU can be used, it will have a significant impact on performance. Big impact. Therefore, if you are involved in computationally intensive programs, you need to use multiple processes. Python's multi-processes are not affected by the GIL. Crawlers are I/O-intensive programs, so using multi-threading can greatly improve crawling efficiency.
Multiprocessing itself is Python's multiprocess library, used to handle operations related to multiprocesses. However, since memory and stack resources cannot be shared directly between processes, and the cost of starting a new process is much greater than that of threads, using multi-threads to crawl has more advantages than using multiple processes.
There is a dummy module under multiprocessing, which allows Python threads to use various methods of multiprocessing.
There is a Pool class under dummy, which is used to implement the thread pool.
This thread pool has a map() method, which allows all threads in the thread pool to execute a function "at the same time".
For example:
After learning the for loop
for i in range(10): print(i*i)
Of course this way of writing can get results, but the code is calculated one by one, which is not very efficient. . If you use multi-threading technology to allow the code to calculate the squares of many numbers at the same time, you need to use multiprocessing.dummy to achieve it:
Example of multi-threading usage:
from multiprocessing.dummy import Pooldef cal_pow(num):
return num*num
pool=Pool(3)num=[x for x in range(10)]result=pool.map(cal_pow,num)print('{}'.format(result))In the above code , first defines a function to calculate the square, and then initializes a thread pool with 3 threads. These three threads are responsible for calculating the square of 10 numbers. Whoever finishes calculating the number on hand first will take the next number and continue calculating until all the numbers are calculated.
In this example, The map() method of the thread pool receives two parameters. The first parameter is the function name, and the second parameter is a list. Note: The first parameter is only the name of the function and cannot contain parentheses . The second parameter is an iterable object. Each element in this iterable object will be received as a parameter by the function clac_power2(). In addition to lists, tuples, sets, or dictionaries can be used as the second parameter of map().
Because crawlers are I/O-intensive operations, especially when requesting web page source code, if you use a single thread to develop, it will waste a lot of time. Waiting for the web page to return, so applying multi-threading technology to the crawler can greatly improve the operating efficiency of the crawler. As an example. It takes 50 minutes to wash clothes in the washing machine, 15 minutes to boil water in the kettle, and 1 hour to memorize vocabulary. If you wait for the washing machine to wash the clothes first, then boil the water after the clothes are washed, and then recite the vocabulary after the water is boiled, it will take a total of 125 minutes.
But if you put it another way, looking at it as a whole, 3 things can run at the same time. Suppose you suddenly have two other people, one of whom is responsible for putting the clothes in the washing machine and waiting for the washing machine to finish. , another person is responsible for boiling water and waiting for the water to boil, and you only need to memorize the words. When the water boils, the clone responsible for boiling the water disappears first. When the washing machine finishes washing the clothes, the clone responsible for washing the clothes disappears. Finally, you memorize the words yourself. It only takes 60 minutes to complete 3 things at the same time.
Of course, everyone will definitely find that the above example is not the actual situation in life. In reality, no one is separated. What happens in real life is that when people memorize words, they concentrate on memorizing them; after the water is boiled, the kettle will make a sound to remind you; when the clothes are washed, the washing machine will make a "didi" sound. So just take the corresponding actions when the reminder comes. There is no need to check every minute. The above two differences are actually the differences between multi-threading and event-driven asynchronous models. This section talks about multi-threaded operations, and we will talk about the crawler framework using asynchronous operations later. Now you just need to remember that when the number of actions that need to be operated is not large, there is no difference in the performance of the two methods, but once the number of actions increases significantly, the efficiency improvement of multi-threading will decrease, and it will even be worse than single-threading. . And by that time, only asynchronous operations are the solution to the problem.
The following two pieces of code are used to compare the performance differences between single-threaded crawlers and multi-threaded crawlers in crawling the bd homepage: 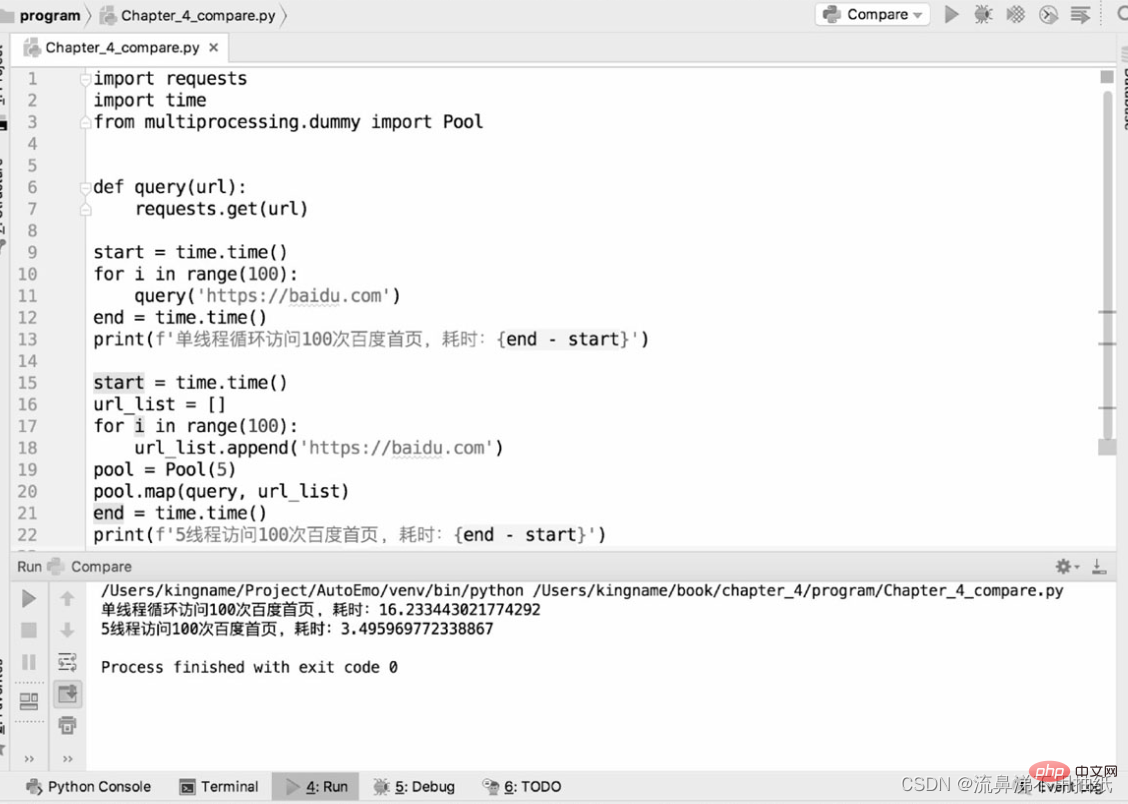
As can be seen from the running results, one thread takes about 16.2s, 5 The thread takes about 3.5s, which is about one-fifth of the time of a single thread. You can also see the effect of 5 threads "running simultaneously" from the time perspective. But it doesn't mean that the bigger the thread pool is, the better. It can also be seen from the above results that the running time of five threads is actually a little more than one-fifth of the running time of one thread. The extra point is actually the time of thread switching. This also reflects from the side that Python's multi-threading is still serial at a micro level. Therefore, if the thread pool is set too large, the overhead caused by thread switching may offset the performance improvement brought by multi-threading. The size of the thread pool needs to be determined according to the actual situation, and there is no exact data. Readers can set different sizes for testing and comparison in specific application scenarios to find the most suitable data.
The course classification of an online education website needs to be crawled course information. Starting from the home page, the courses are divided into several major categories, such as Python, Node.js and Golang according to language. There are many courses under each major category, such as crawlers, Django and machine learning under Python. Each course is divided into many class hours.
In the case of depth-first search, the crawling route is as shown in the figure (serial number from small to large)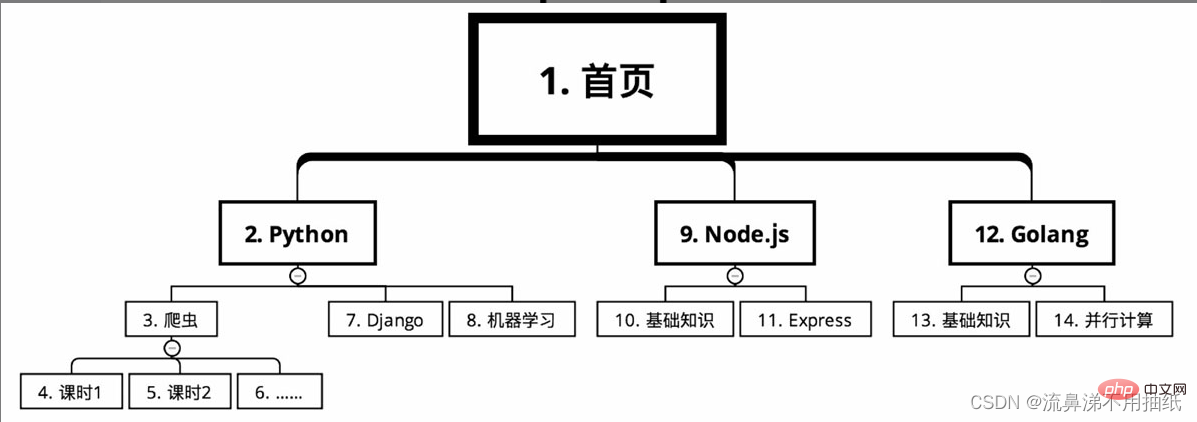
Sequence The following 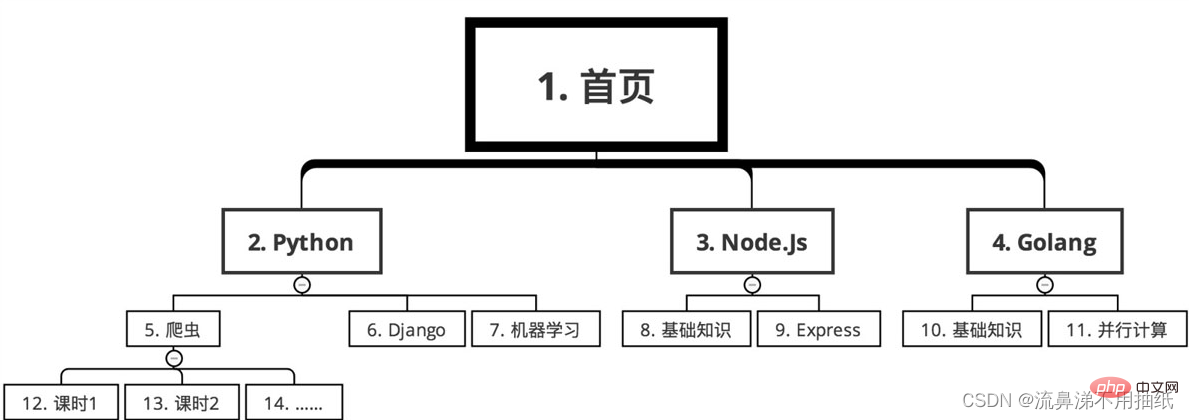
For example, you want to crawl all the restaurant information in a website nationwide and the order information of each restaurant. Assuming that the depth-first algorithm is used, then first crawl to restaurant A from a certain link, and then immediately crawl the order information of restaurant A. Since there are hundreds of thousands of restaurants across the country, it may take 12 hours to climb them all. The problem caused by this is that the order volume of restaurant A may reach 8 o'clock in the morning, while the order volume of restaurant B may reach 8 o'clock in the evening. Their order volume differs by 12 hours. For popular restaurants, 12 hours may result in an income gap of millions. In this way, when doing data analysis, the 12-hour time difference will make it difficult to compare the sales performance of restaurants A and B. Relative to order volume, restaurant volume changes are much smaller. Therefore, if you use breadth-first search, first crawl all restaurants from 0:00 in the middle of the night to 12:00 noon the next day, and then focus on crawling the order volume of each restaurant from 14:00 to 20:00 the next day. In this way, it only took 6 hours to complete the order crawling task, narrowing the difference in order volume caused by the time difference. At the same time, since the shop's crawling every few days has little impact, the number of requests has also been reduced, making it more difficult for the crawler to be discovered by the website.
For another example, to analyze real-time public opinion, you need to crawl Baidu Tieba. A popular forum may have tens of thousands of pages of posts, assuming the earliest posts date back to 2010. If breadth-first search is used, first obtain the titles and URLs of all posts in this Tieba, and then enter each post based on these URLs to obtain information on each floor. However, since it is real-time public opinion, posts from 7 years ago are of little significance for current analysis. What is more important are new posts, so new content should be captured first. Compared with past content, real-time content is the most important. Therefore, for crawling Tieba content, depth-first search should be used. When you see a post, go in quickly and crawl the information of each floor. After crawling one post, you can crawl to the next post. Of course, these two search algorithms are not either/or and need to be chosen flexibly according to the actual situation. In many cases, they can also be used at the same time.
Recommended learning: python video tutorial
The above is the detailed content of Python detailed analysis of multi-threaded crawlers and common search algorithms. For more information, please follow other related articles on the PHP Chinese website!































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



