


This article brings you relevant knowledge aboutmysql, which mainly introduces the related issues of mysql transactions. Transactions are an important feature that distinguishes MySQL from NoSQL and ensures relational database data. The key technology of consistency, I hope it will be helpful to everyone.

Recommended learning:mysql learning video tutorial
Transactions are what distinguish MySQL from NoSQL The important feature is the key technology to ensure the data consistency of relational database. A transaction can be regarded as the basic execution unit of database operations, which may include one or more SQL statements. When these statements are executed, either all of them are executed or none of them are executed.
The execution of a transaction mainly includes two operations, commit and rollback.
Submit: commit, writing the transaction execution results to the database.
Rollback: rollback, roll back all executed statements and return the data before modification.
MySQL transactions include four characteristics, known as the four ACID kings.
Atomicity: Statements are either fully executed or not executed at all. This is the core feature of a transaction. The transaction itself is defined by atomicity; the implementation is mainly based on the undo log. .
Durability (Durability): Ensure that data will not be lost due to downtime and other reasons after transaction submission; the implementation is mainly based on redo log.
Isolation (Isolation): Ensure that transaction execution is as possible as possible Not affected by other transactions; InnoDB's default isolation level is RR. The implementation of RR is mainly based on the lock mechanism, hidden columns of data, undo log and next-key lock mechanism.
Consistency: Transaction The ultimate goal pursued, the realization of consistency requires guarantees at both the database level and the application level.
Atomicity of transactions Just like an atomic operation, it means that the transaction cannot be further divided. Either all the operations are done or none of the operations are done; if an SQL statement in the transaction fails to execute, the executed statement must also be rolled back, and the database returns to the state before the transaction. .Only 0 and 1, no other values.
The atomicity of the transaction indicates that the transaction is a whole. When the transaction cannot be executed successfully, all statements that have been executed in the transaction need to be rolled back, causing the database to return To the state where the transaction has not been started initially.
The atomicity of the transaction is achieved through the undo log. When the transaction needs to be rolled back, the InnoDB engine will call the undo log to undo the SQL statement. Data rollback.
Transaction durability means that after the transaction is committed, the database changes should be permanent, not temporary. . This means that after the transaction is committed, any other operations or even system downtime will not affect the execution results of the original transaction.
The durability of the transaction is through the InnoDB storage engine Redo log is implemented. See below for specific implementation ideas.
Atomicity and durability are properties of a single transaction itself, while isolation is Refers to the relationship that should be maintained between transactions. Isolation requires that the effects of different transactions do not interfere with each other, and the operations of one transaction are isolated from other transactions.
Since a transaction may not only contain one SQL statement, so it is very likely that other transactions will start executing during the execution of the transaction. Therefore, the concurrency of multiple transactions requires that the operations between transactions be isolated from each other. This is somewhat similar to the concept of data synchronization between multiple threads.
Lock mechanism
The isolation between transactions is achieved through the lock mechanism. When a transaction needs to modify a certain row of data in the database, it needs to first Lock the data; other transactions will not run operations on the locked data, and can only wait for the current transaction to commit or rollback to release the lock.
The locking mechanism is not an unfamiliar concept. In many scenarios Different implementations of locks are used to protect and synchronize data. In MySQL, locks can also be divided into different types according to different division standards.
Divided according to granularity: row lock, table lock, page lock
Divided according to usage: shared lock, exclusive lock
Divided according to idea: pessimistic lock , Optimistic locking
There are many knowledge points about the locking mechanism. Due to lack of space, I will discuss them all. Here is a brief introduction to locks divided according to granularity.
Granularity: refers to the level of refinement or comprehensiveness of the data stored in the data unit of the data warehouse. The higher the degree of refinement, the smaller the granularity level; conversely, the lower the degree of refinement, the larger the granularity level.
MySQL can be divided into row locks, table locks and page locks according to the granularity of locks.
Row lock: The lock with the smallest granularity, indicating that only the row of the current operation is locked;
Table lock: The lock with the largest granularity, indicating that the current The operation locks the entire table;
Page lock: A lock with a granularity between row-level locks and table-level locks, which means locking the page.
Granular division of database
These three types of locks lock data at different levels. Due to the different granularities, they bring The advantages and disadvantages are also different.
Table lock will lock the entire table when operating data, so the concurrency performance is poor;
Row lock only locks the data that needs to be operated, and the concurrency performance is good. However, since locking itself consumes resources (obtaining locks, checking locks, releasing locks, etc. all consume resources), using table locks can save a lot of resources when there is a lot of locked data.
Different storage engines in MySQL can support different locks. MyIsam only supports table locks, while InnoDB supports both table locks and row locks. For performance reasons, row locks are used in most cases.
Concurrent reading and writing issues
In a concurrent situation, simultaneous reading and writing of MySQL may cause three types of problems, dirty reads, non-repeatability and phantom reads.
(1) Dirty reading: The current transaction reads uncommitted data from other transactions, which is dirty data.
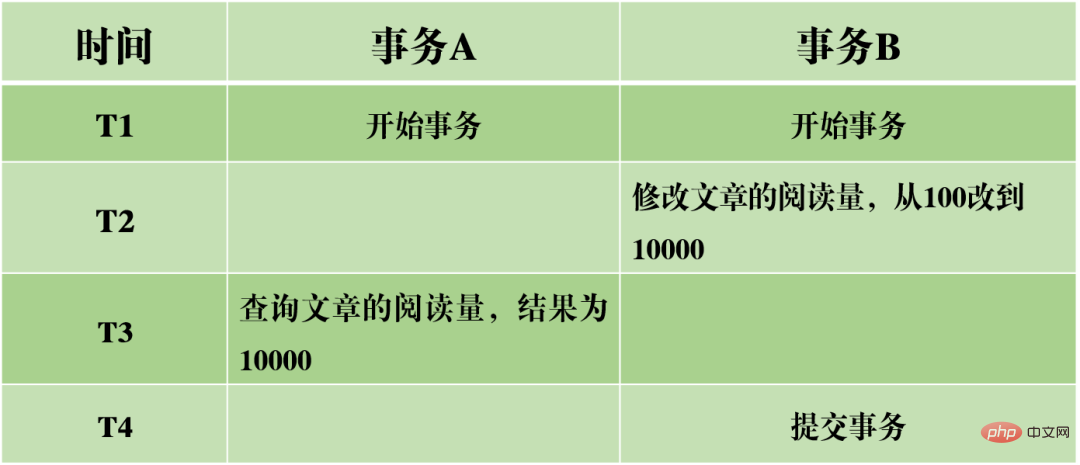
Take the above picture as an example. When transaction A reads the reading volume of the article, it reads the data submitted by transaction B. If transaction B is not successfully submitted in the end, causing the transaction to be rolled back, then the reading amount is not actually modified successfully, but transaction A reads the modified value, which is obviously unreasonable.
(2) Non-repeatable read: The same data is read twice in transaction A, but the results of the two reads are different. The difference between dirty read and non-repeatable read is that the former reads uncommitted data by other transactions, while the latter reads data that has been submitted by other transactions.
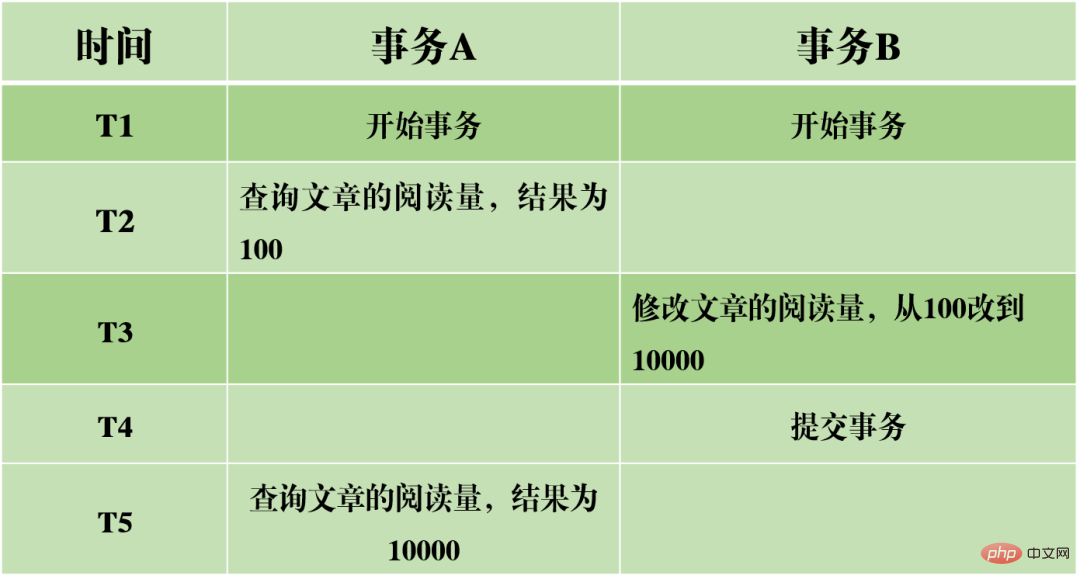
#The above picture is an example. When transaction A reads the data of article readings one after another, the results are different. It means that during the execution of transaction A, the value of the reading volume was modified by other transactions. This makes the data query results no longer reliable and also unrealistic.
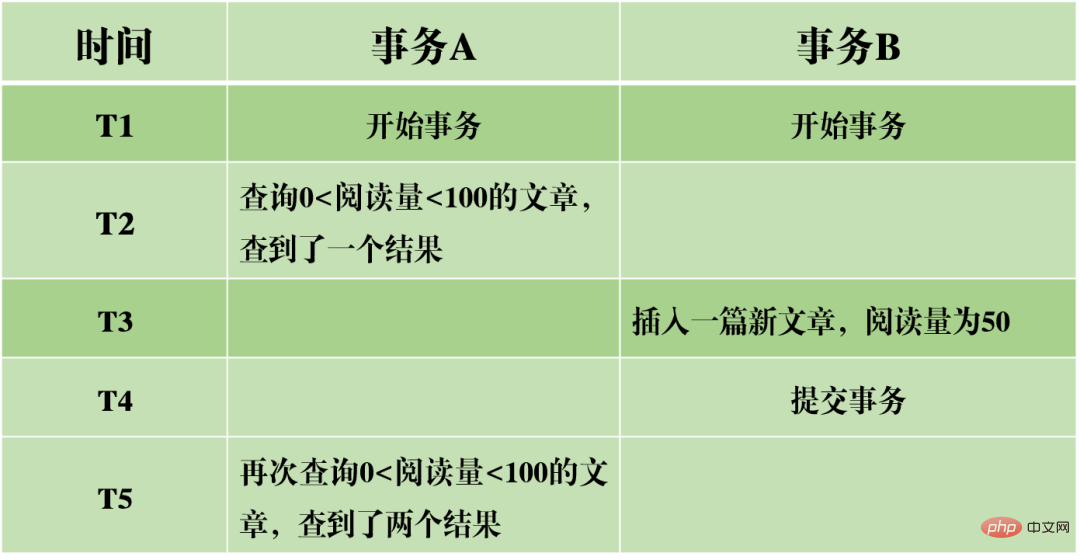
(3) Phantom reading: In transaction A, the database is queried twice according to a certain condition. The number of rows in the two query results is different. This phenomenon is called phantom reading. The difference between non-repeatable reading and phantom reading can be easily understood as: the former means that the data has changed, and the latter means that the number of rows of data has changed.
Isolation Level
Based on the above three problems, four isolation levels have been generated, indicating different degrees of isolation properties of the database.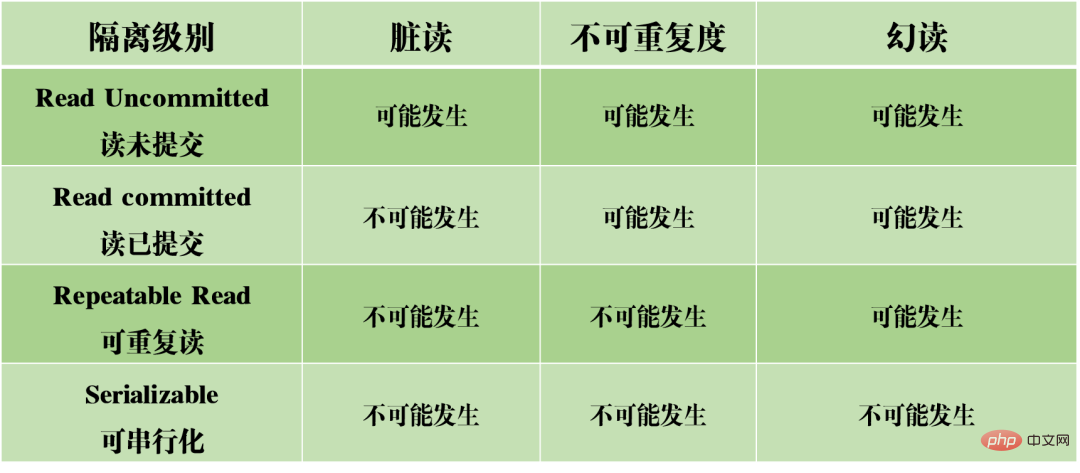
MVCC
Another big piece that is hard to chew. MVCC is used to implement the third isolation level above, which can read RR repeatedly.MVCC: Multi-Version Concurrency Control, a multi-version concurrency control protocol.The characteristic of MVCC is that at the same time, different transactions can read different versions of data, thus solving the problems of dirty reads and non-repeatable reads. MVCC actually achieves the coexistence of multiple versions of data through hidden columns of data and rollback logs (undo log). The advantage of this is that when using MVCC to read data, there is no need to lock, thus avoiding conflicts of simultaneous reading and writing. When implementing MVCC, several additional hidden columns will be saved in each row of data, such as the version number and deletion time when the current row was created and the rollback pointer to the undo log. The version number here is not the actual time value, but the system version number. Every time a new transaction is started, the system version number is automatically incremented. The system version number at the beginning of the transaction will be used as the version number of the transaction, which is used to compare with the version number of each row of records in the query.
Each transaction has its own version number, so that when data operations are performed within the transaction, the purpose of data version control is achieved through comparison of version numbers.
In addition, the isolation level RR implemented by InnoDB can avoid the phenomenon of phantom reading, which is achieved through the next-key lock mechanism.
Next-key lock is actually a type of row lock, but it not only locks the current row record itself, but also locks a range. For example, in the above example of phantom reading, when you start to query articles with 0
Gap lock: Block the gap in the index record
Although InnoDB uses next-key lock to avoid phantom read problems, it is not truly serializable isolation. Let’s look at another example.
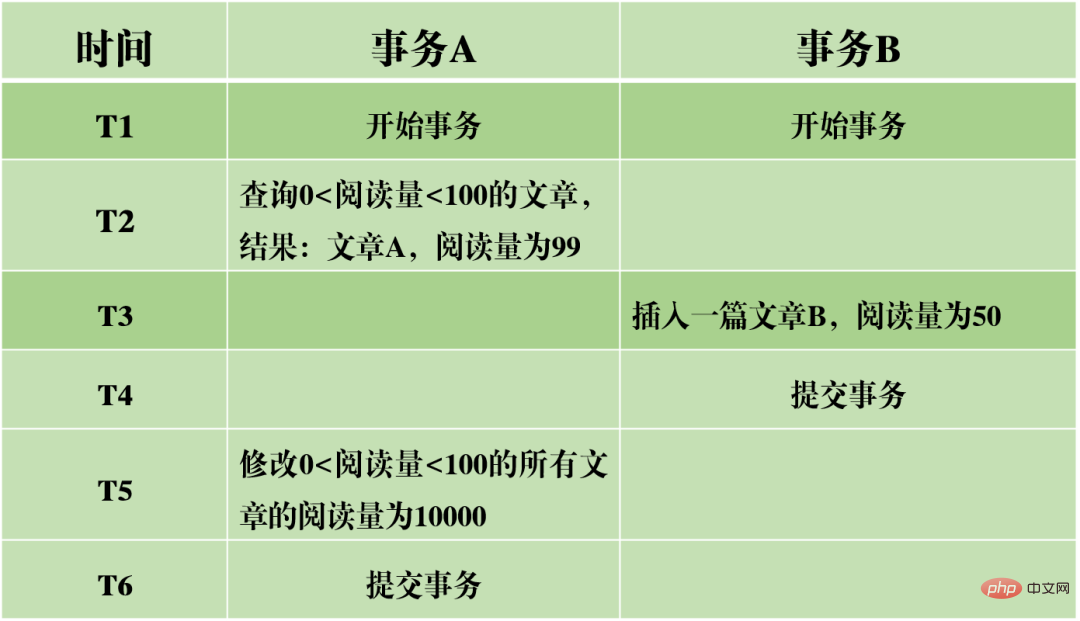
First ask a question:
At T6 time, after transaction A commits the transaction, guess the reading volume of article A and article B For how much?
The answer is that the reading volume of article AB has been modified to 10,000. This means that the submission of transaction B actually affects the execution of transaction A, indicating that the two transactions are not completely isolated. Although it can avoid the phenomenon of phantom reading, it does not reach the level of serializability.
This also shows that avoiding dirty reads, non-repeatable reads and phantom reads is a necessary but not sufficient condition to achieve a serializable isolation level. Serializability can avoid dirty reads, non-repeatable reads, and phantom reads, but avoiding dirty reads, non-repeatable reads, and phantom reads does not necessarily achieve serializability.
Consistency
Consistency means that after the transaction is executed, the integrity constraints of the database are not destroyed, and the data state is legal before and after the transaction is executed.
Consistency is the ultimate goal pursued by transactions. Atomicity, durability, and isolation actually exist to ensure the consistency of the database state.
I won’t say much more. You taste carefully.
After understanding the basic structure of MySQL, you can generally have a clearer understanding of the execution process of MySQL. Next I will introduce the logging system to you.
The MySQL log system is an important component of the database and is used to record updates and modifications to the database. If the database fails, the original data of the database can be restored through different log records. Therefore, in fact, the log system directly determines the robustness and robustness of MySQL operation.
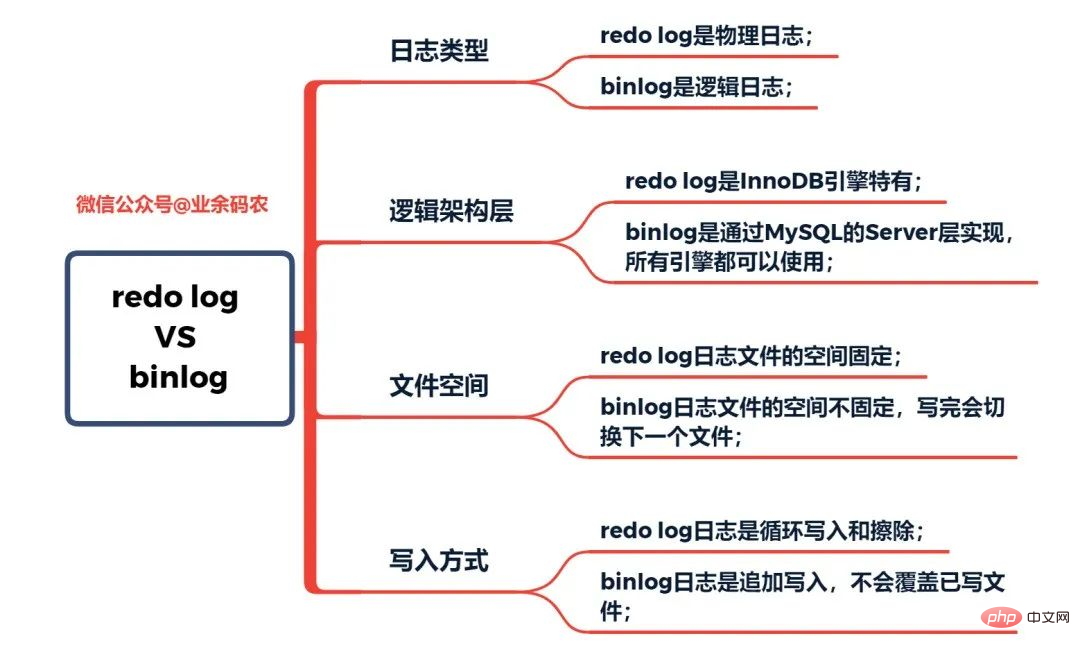
MySQL has many types of logs, such as binary logs (binlog), error logs, query logs, slow query logs, etc. In addition, the InnoDB storage engine also provides two types of logs: redo log (redo log) and undo log (rollback log). Here we will focus on the InnoDB engine and analyze the three types of redo logs, rollback logs and binary logs.
Redo log (redo log)
The redo log (redo log) is the log of the InnoDB engine layer. It is used to record the changes in data caused by transaction operations. is a physical modification of the data page.
The function of redoing the diary is actually easy to understand. Let me use an analogy. Modification of data in the database is like a paper you wrote. What if the paper is lost one day? To prevent this unfortunate occurrence, when writing a paper, we can keep a small notebook to record every modification, and record when and what kind of modifications were made to a certain page. This is the redo log.
The InnoDB engine updates data by first writing the update record to the redo log, and then updating the contents of the log to the disk when the system is idle or according to the set update strategy. . This is the so-called write-ahead technology (Write Ahead logging). This technology can greatly reduce the frequency of IO operations and improve the efficiency of data refresh.
Dirty data flush
It is worth noting that the size of the redo log is fixed. In order to continuously write update records, in redo Two flag positions are set in the log, checkpoint and write_pos, which respectively indicate the position where erasure is recorded and the position where writing is recorded. The data writing diagram of the redo log can be seen in the figure below.
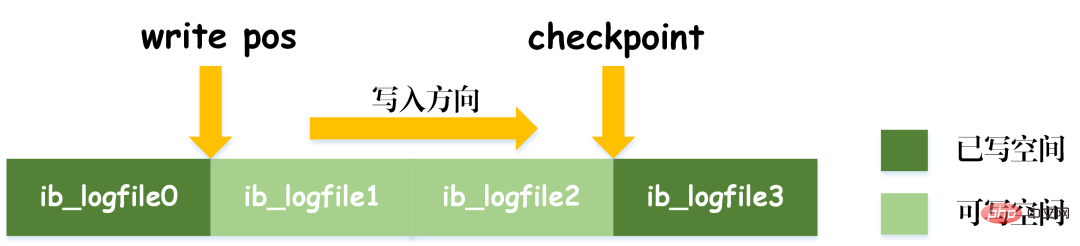
When the write_pos mark reaches the end of the log, it will jump from the end to the head of the log for re-circulation writing. Therefore, the logical structure of redo log is not linear, but can be regarded as a circular motion. The space between write_pos and checkpoint can be used to write new data. Writing and erasing are carried out backwards and forward in a cycle.
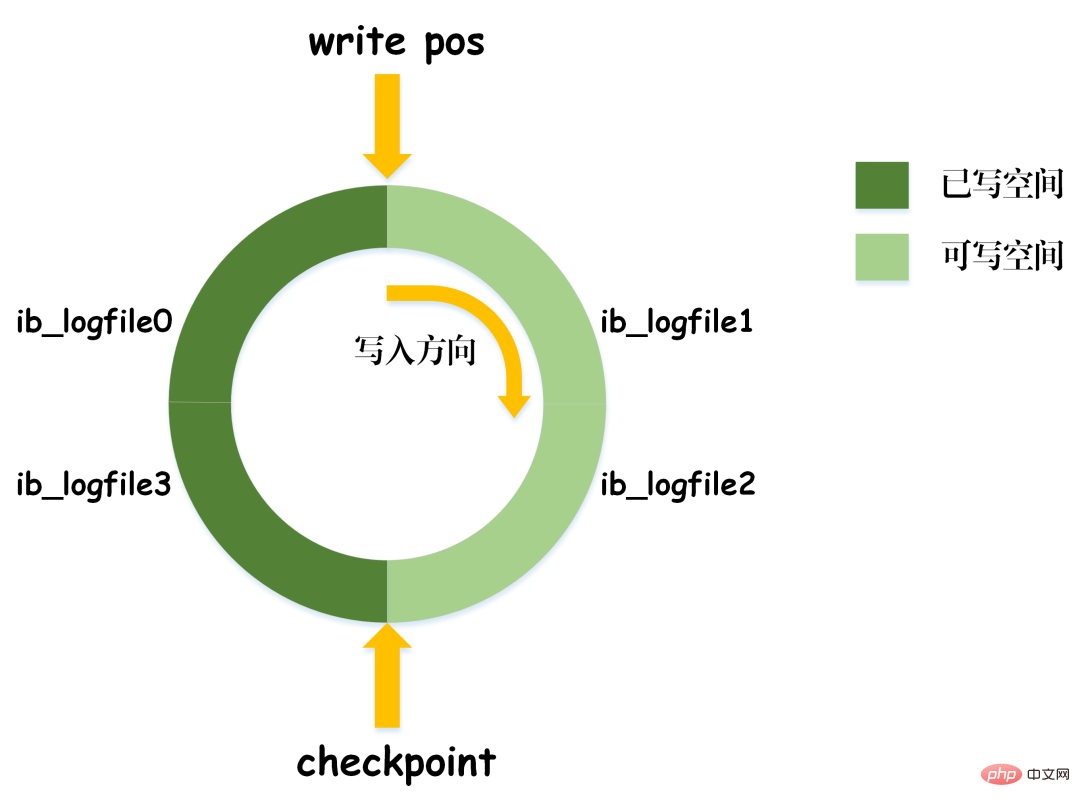
When write_pos catches up with checkpoint, it means that the redo log is full. At this time, you cannot continue to execute new database update statements. You need to stop and delete some records first, and execute checkpoint rules to free up writable space.
Checkpoint rules: After checkpoint is triggered, flush both dirty data pages and dirty log pages in the buffer to disk.
Dirty data: refers to the data in the memory that has not been flushed to the disk.
The most important concept in redo log is the buffer pool, which is an area allocated in memory and contains the mapping of some data pages in the disk as a buffer for accessing the database.
When requesting to read data, it will first determine whether there is a hit in the buffer pool. If there is a miss, it will be retrieved on the disk and put into the buffer pool;
When a request is made to write data, it will be written to the buffer pool first, and the modified data in the buffer pool will be periodically refreshed to the disk. This process is also called brushing.
Therefore, when the data is modified, in addition to modifying the data in the buffer pool, the operation will also be recorded in the redo log; when the transaction is submitted, the data will be flushed based on the redo log records. plate. If MySQL goes down, the data in the redo log can be read when restarting and the database can be restored, thereby ensuring the durability of transactions and enabling the database to gain crash-safe capabilities.
Dirty log flushing
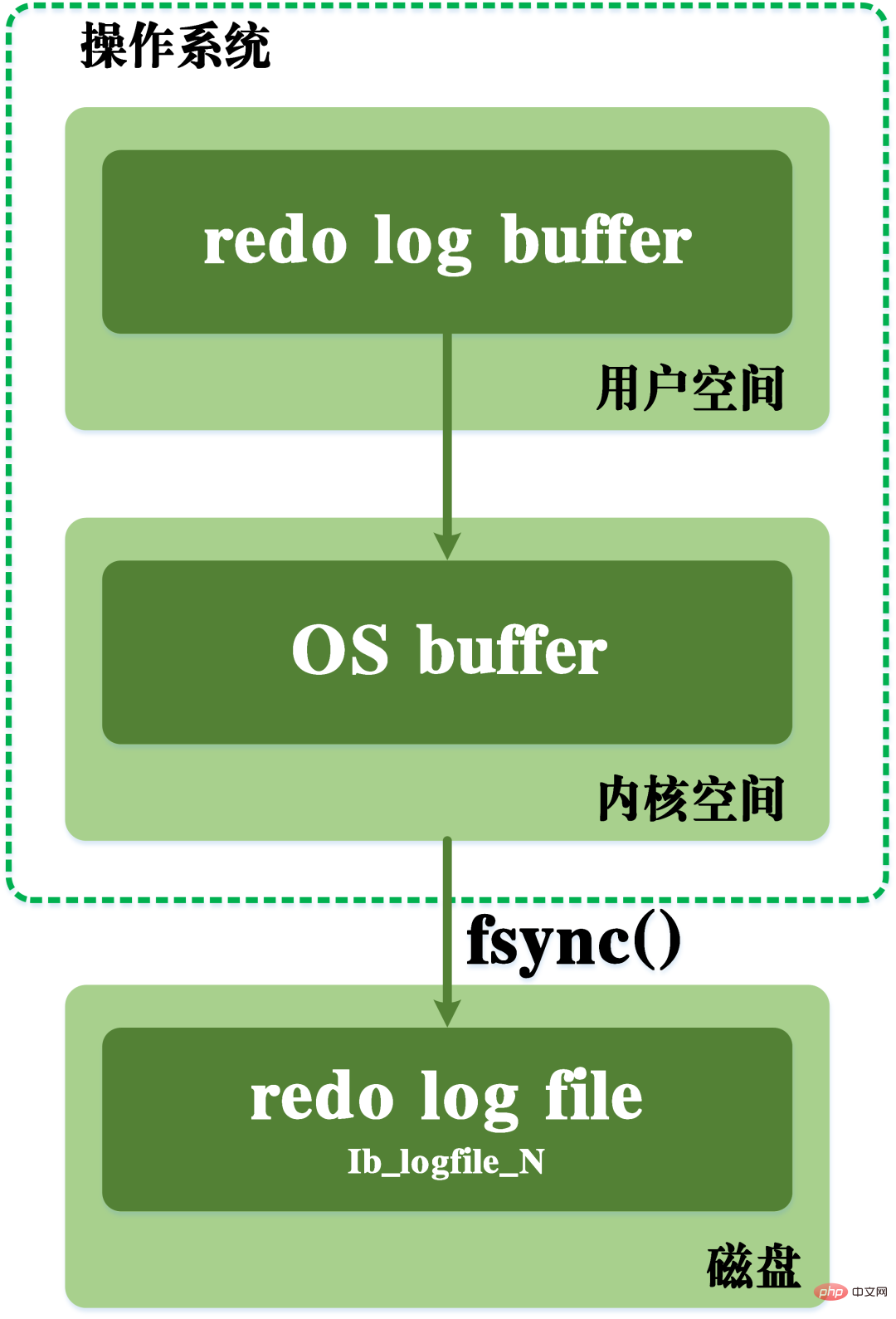
In addition to the above mentioned flushing of dirty data, in fact, when the redo log is recorded, in order to ensure the persistence of the log file , also need to go through the process of writing log records from memory to disk. The redo log log can be divided into two parts. One is the cache log redo log buff that exists in volatile memory, and the other is the redo log log file redo log file saved on the disk.
In order to ensure that each record can be written to the log on the disk, the fsync operation of the operating system is called every time the log in the redo log buffer is written to the redo log file.
fsync function: included in the UNIX system header file #include
, used to synchronize all modified file data in the memory to the storage device. During the writing process, it also needs to go through the os buffer of the operating system kernel space. The writing process of redo log can be seen in the figure below.
redo log flushing process
Binary log (binlog)
Binary log binlog is the service layer The log is also called archive log. Binlog mainly records changes in the database, including all update operations of the database. All operations involving data changes must be recorded in the binary log. Therefore, binlog can easily copy and back up data, so it is often used for synchronization of master-slave libraries.
The content stored in the binlog here seems to be very similar to the redo log, but it is not. The redo log is a physical log, which records the actual modifications to a certain data; while the binlog is a logical log, which records the original logic of the SQL statement, such as "give the a field of the row with ID=2 plus 1 ". The content in the binlog log is binary. Depending on the log format parameters, it may be based on SQL statements, the data itself, or a mixture of the two. Generally commonly used records are SQL statements.
My personal understanding of the concepts of physics and logic here is:
The physical log can be regarded as the change information on the data page in the actual database, and only the results are valued. It doesn't matter "which way" led to this result;
Logical logs can be regarded as changes in data caused by a certain method or operation method, and store logical operations. .
At the same time, redo log is based on crash recovery to ensure data recovery after MySQL crashes; while binlog is based on point-in-time recovery to ensure that the server can recover data based on time points, or Make a backup of your data.
In fact, MySQL did not have a redo log at the beginning. Because at first MySQL did not have an InnoDB engine, the built-in engine was MyISAM. Binlog is a service layer log, so it can be used by all engines. However, binlog logs alone can only provide archiving functions and cannot provide crash-safe capabilities. Therefore, the InnoDB engine uses a technology learned from Oracle, that is, redo log, to achieve crash-safe capabilities. Here, the characteristics of redo log and binlog are compared respectively:
Comparison of the characteristics of redo log and binlog
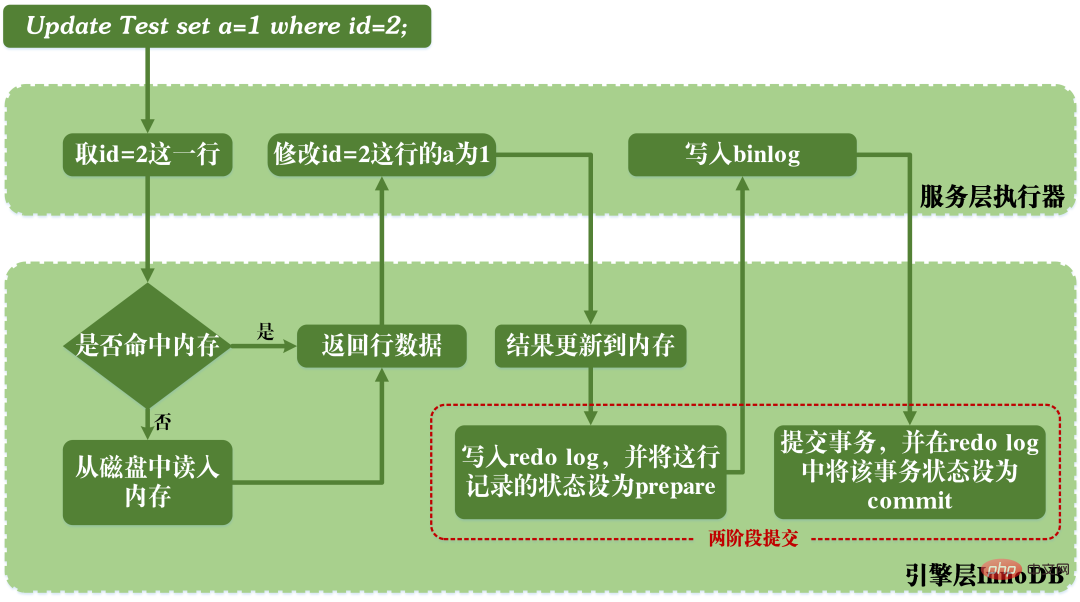
When MySQL executes the update statement, It will involve reading and writing redo logs and binlog logs. The execution process of an update statement is as follows:
Execution process of MySQL update statement
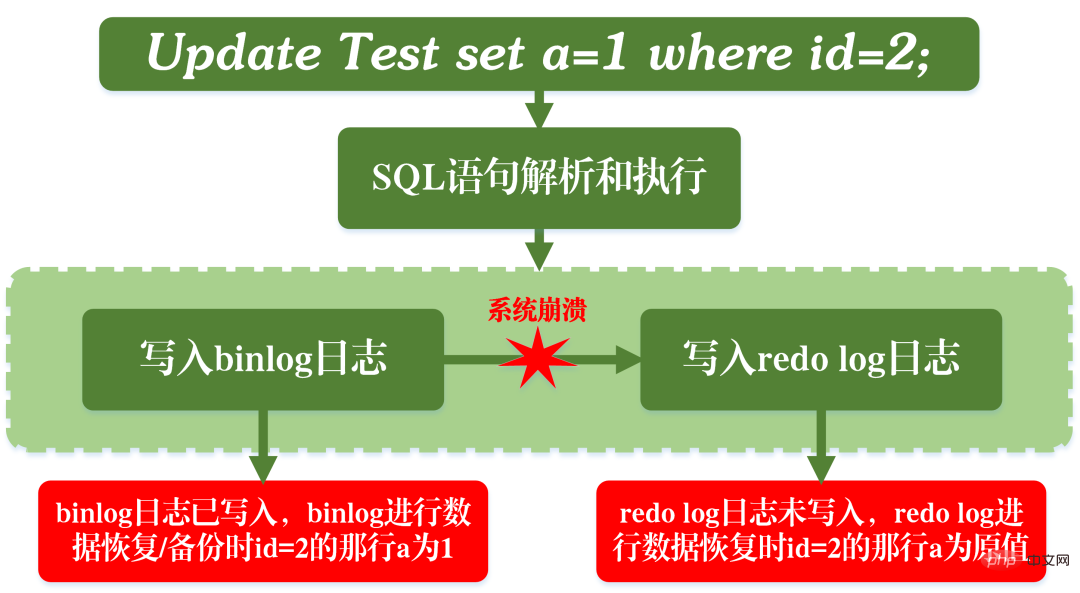
As can be seen from the above figure, when MySQL executes the update statement, it parses and executes the statement in the service layer. The engine layer extracts and stores data; at the same time, the service layer writes binlog and writes redo log in InnoDB.
Not only that, there are two stages of submission when writing redo log. One is the writing of the prepare state before the binlog is written, and the second is the writing of the commit state after the binlog is written.
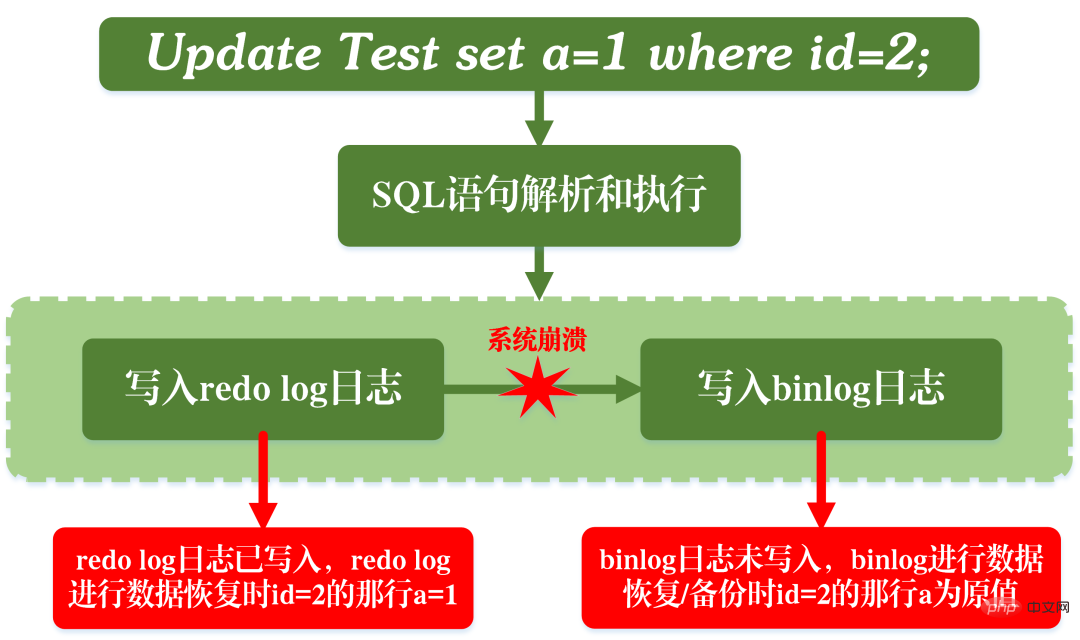
The reason for arranging such a two-stage submission naturally has its reason. Now we can assume that instead of using two-stage submission, we adopt "single-stage" submission, that is, either write redo log first and then write binlog; or write binlog first and then write redo log. Submitting in these two ways will cause the state of the original database to be inconsistent with the state of the restored database.
Write redo log first, then write binlog:
After writing redo log, the data has crash-safe capability at this time, so the system crashes and the data It will be restored to the state before the transaction started. However, if the system crashes when the redo log is completed and before the binlog is written, the system crashes. At this time, binlog does not save the above update statement, resulting in the above update statement being missing when binlog is used to back up or restore the database. As a result, the data in the row id=2 is not updated.
The problem of writing redo log first and then binlog
Write binlog first and then redo log:
After writing the binlog, all statements are saved, so the data in the row id=2 in the database copied or restored through the binlog will be updated to a=1. However, if the system crashes before the redo log is written, the transaction recorded in the redo log will be invalid, causing the data in the row id=2 in the actual database not to be updated.
The problem of writing binlog first and then redo log
It can be seen that the two-stage submission is to avoid the above problems, making binlog and redo log The information stored in is consistent.
Rollback log (undo log)
The rollback log is also a log provided by the InnoDB engine. As the name suggests, the function of the rollback log is to roll back the data. When a transaction modifies the database, the InnoDB engine will not only record the redo log, but also generate the corresponding undo log; if the transaction execution fails or rollback is called, causing the transaction to be rolled back, the information in the undo log can be used to restore the data. Scroll to the way it looked before the modification.
But undo log is different from redo log. It is a logical log. It records information related to the execution of SQL statements. When a rollback occurs, the InnoDB engine will do the opposite of the previous work based on the records in the undo log. For example, for each data insertion operation (insert), a data deletion operation (delete) will be performed during rollback; for each data deletion operation (delete), a data insertion operation (insert) will be performed during rollback; for each data update Operation (update), when rolling back, a reverse data update operation (update) will be performed to change the data back. Undo log has two functions, one is to provide rollback, and the other is to implement MVCC.
3.Master-slave replication
The concept of master-slave replication is very simple. It is to copy an identical database from the original database. The original database is called the master database. , the replicated database is called the slave database. The slave database will synchronize data with the master database to maintain data consistency between the two.
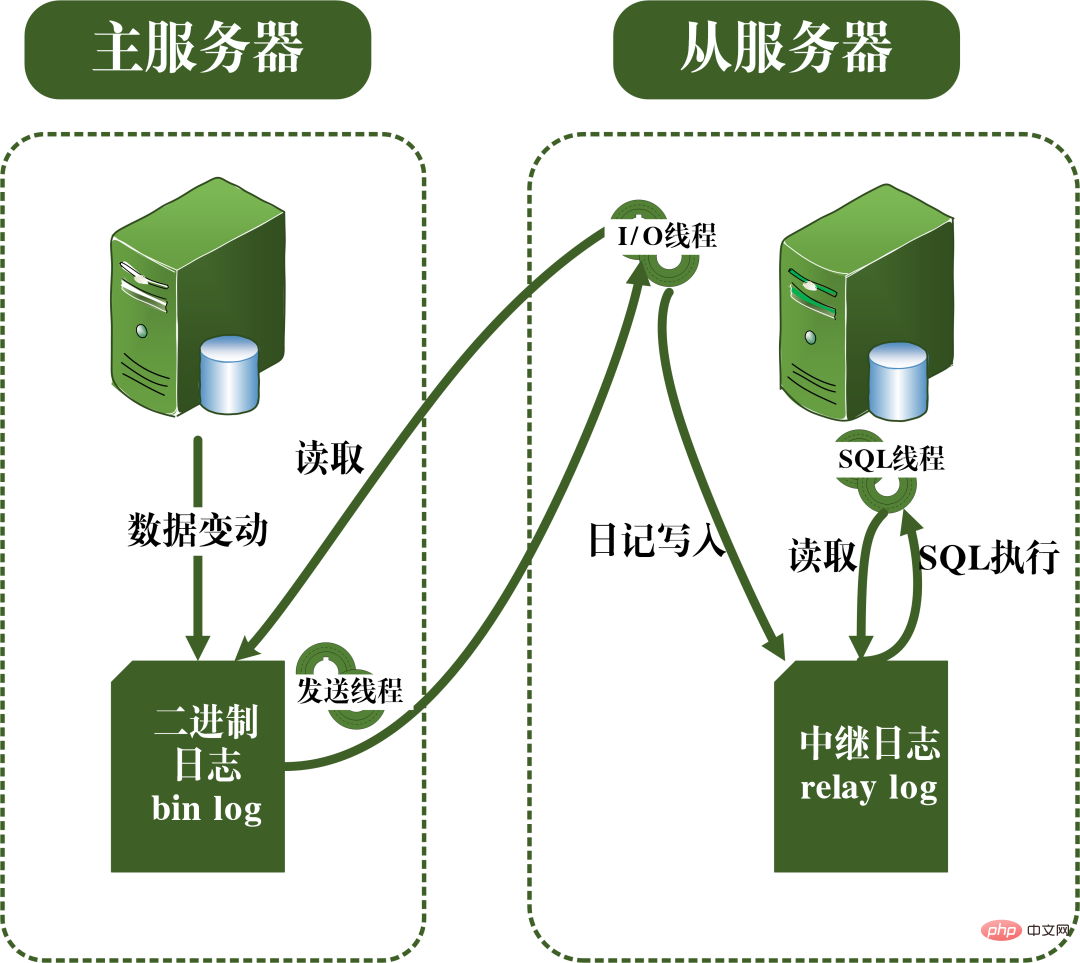
The principle of master-slave replication is actually implemented through the bin log. The bin log log stores all SQL statements in the database. By copying the SQL statements in the bin log log and then executing the statements, synchronization between the slave database and the master database can be achieved.
The master-slave replication process can be seen in the figure below. The master-slave replication process is mainly carried out by three threads. A sending thread runs in the master server and is used to send binlog logs to the slave server. There are two additional I/O threads and SQL threads running on the slave server. The I/O thread is used to read the binlog log content sent by the main server and copy it to the local relay log. The SQL thread is used to read the SQL statements about data updates in the relay log and execute them to achieve data consistency between the master and slave libraries.
Master-slave replication principle
The reason why master-slave replication needs to be implemented is actually determined by the actual application scenario. The benefits that master-slave replication can bring are:
1. Off-site backup of data is achieved through replication. When the master database fails, the slave database can be switched to avoid data loss.
2. The architecture can be expanded. When the business volume becomes larger and larger and the I/O access frequency is too high, multi-database storage can be used to reduce the frequency of disk I/O access and improve the I/O of a single machine. O performance.
3. It can realize the separation of reading and writing, so that the database can support greater concurrency.
4. Implement server load balancing by dividing the load of customer queries between the master server and the slave server.
Summary
The MySQL database should be regarded as one of the technologies that programmers must master. Whether it is during the project process or during the interview, MySQL is a very important basic knowledge. However, there are really too many things for MySQL. When I was writing this article, I consulted a lot of information and found that the more I couldn't understand, the more I couldn't understand. It really goes with that saying:
The more you know, the more you don’t know.
This article focuses on analyzing the basic principles of MySQL's basic transactions and logging system from a theoretical perspective. I try to avoid using actual code to describe it when describing it. Even this article with nearly 10,000 words and nearly 20 hand-drawn illustrations cannot fully analyze the breadth and depth of MySQL.
But I believe that for beginners, these theories can give you an overall perception of MySQL and give you a clearer understanding of the question "what is a relational database"; and For those who are proficient in MySQL, perhaps this article can awaken your long-lost underlying theoretical foundation, and it will also be helpful for your subsequent interviews.
There is no absolute right or wrong in technology. Please forgive me if there are any mistakes in the article, and welcome to discuss with me. Independent thinking is always more effective than passive acceptance.
Recommended learning:mysql video tutorial
The above is the detailed content of Let's analyze the MySQL transaction log together. For more information, please follow other related articles on the PHP Chinese website!






























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



