



1. What are the ideas and principles of optimization
1. Optimize the queries that need optimization
2. Position the optimization objects Performance bottleneck
3. Clear optimization goals
4. Start with Explain
5. Use more profiles
6. Always use small result sets to drive large result sets
7. Use indexing as much as possible Complete the sorting in
8. Only take out the fields (Columns) you need
9. Only use the most effective filtering conditions
10. Avoid complex joins as much as possible
Free learning recommendations:mysql video tutorial
1. Optimize queries that need to be optimized
High concurrency The impact of low-cost (relatively) queries on the entire system is far greater than that of low-concurrency and high-cost queries.
2. Locate the performance bottleneck of the optimization object
When we get a query that needs to be optimized, we must first determine whether the bottleneck of the query is IO or CPU. . Is it database access that consumes more or data operations (such as grouping and sorting) that consumes more?
3. Clear optimization goals
By understanding the current overall status of the database, we can know the maximum pressure that the database can withstand, that is, we know the most pessimistic situation;
To grasp the database object information related to the query, we can know how many resources are consumed in the best and worst conditions;
To know the status of the query in the application system, we can analyze the amount of resources that the query can occupy The proportion of system resources can also know how much the efficiency of the query affects the customer experience.
4. Start with Explain
Explain can tell you what kind of execution plan this query is implemented in the database. First of all, we need to have a goal. By constantly adjusting and trying, and then using Explain to verify whether the results meet our needs, we will get the expected results.
5. Always use small result sets to drive large result sets
Many people like to use "Small tables drive large tables## when optimizing SQL #", this statement is not rigorous. Because the result set returned by the large table after being filtered by the where condition is not necessarily larger than the result set returned by the small table, if the large table is used to drive the small table at this time, the opposite performance effect will be obtained.This result is also very easy to understand. In MySQL, there is only one Join method, Nested Loop, that is, MySQL's Join is implemented through nested loops. The larger the driven result set is, the more loops are required, and the number of accesses to the driven table will naturally be more. Each time the driven table is accessed, even if the logical IO required is very small, the number of loops will increase. Naturally, the total amount cannot be very small, and each cycle inevitably consumes the CPU, so the amount of CPU calculations will also increase. Therefore, if we only use the size of the table as the basis for judging the driving table, if the result set left after filtering the small table is much larger than that of the large table, the result will be more loops in the required nested loops. On the contrary, the number of cycles required will be fewer, and the overall amount of IO and CPU operations will also be less. Moreover, even for non-Nested Loop Join algorithms, such as Hash Join in Oracle, it is still the optimal choice for a small result set to drive a large result set.
Therefore, when optimizing Join Query, the most basic principle is "small result sets drive large result sets". Through this principle, we can reduce the number of loops in nested loops and reduce the total amount of IO and the number of CPU operations. . Complete sorting in the index as much as possible
6. Only take out the fields (Columns) you need
For any query, the returned data needs to go through network packets When transmitting to the client, if more Columns are taken out, the amount of data that needs to be transmitted will naturally be larger, which is a waste in terms of network bandwidth and network transmission buffer.7. Only use the most effective filtering conditions
For example, a user table user has fields such as id and nick_name, and the indexes are id and nike_name. The following are two query statements#1 select * from user where id = 1 and nick_name = 'zs'; #2 selet * from user where id = 1
8. Avoid complex join queries
The more tables our query involves, the more resources we need to lock. In other words, the more complex the Join statement, the more resources it needs to lock and the more other threads it blocks. On the contrary, if we split a more complex query statement into multiple simpler query statements and execute them step by step, fewer resources will be locked each time and fewer other threads will be blocked.
Many people may have questions. After splitting the complex Join statement into multiple simple query statements, won’t our network interactions be more? The overall consumption in terms of network delay will be greater. Wouldn't it take longer to complete the entire query? Yes, this is possible, but it's not certain. We can analyze it again. When a complex query statement is executed, more resources need to be locked, and the probability of being blocked by others is greater. If it is a simple query, because there are fewer resources that need to be locked, The probability of being blocked will also be much smaller. Therefore, more complex connection queries may be blocked before execution and waste more time. Moreover, our database serves not only this query request, but also many, many other requests. In a high-concurrency system, it is very worthwhile to sacrifice the short response time of a single query to improve the overall processing capability. Optimization itself is an art of balance and trade-offs. Only by knowing the trade-offs and balancing the whole can the system be better.
2. Use Explain and Profiling
1. Use Explain
Various information display
| Field | Description |
|---|---|
| ID | The sequence number of the query in the execution plan |
| Select_type | Query type: DEPENDENT SUBQUERY: The first SELECT in the inner layer of the subquery, which depends on the external query result set; DEPENDENT UNION : All subsequent SELECTs starting from the second SELECT in the UNION in the subquery also depend on the external query result set; PRIMARY: The outermost query in the subquery, not the primary key query; SUBQUERY: Sub Query the first SELECT of the inner query, and the result does not depend on the external result set; UNCACHEABLE SUBQUERY: a subquery whose result set cannot be cached; UNION: all subsequent SELECTs starting from the second SELECT in the UNION statement, The first SELECT is PRIMARY UNION RESULT: The merged result in UNION |
| Table | The name of the table in the accessed database |
| TYPE | Access method: ALL: Full table scan const: Constant, only one record matches at most. Since it is a constant, it actually only needs to be read once eq_ref: There is only one matching result at most, which is usually accessed by the primary key or unique index. index: full index scan range: index range scan ref: reference query of the driven table index in the jion statement system: System table, there is only one row of data in the table |
| Possible_keys | Possibly used indexes |
| Key | Index used |
| Key_len | Index length |
| Rows | Estimated Number of records in the result set |
| Extra | Extra information |
2、Profiling使用
该工具可以获取一条Query在整个执行过程中多种资源消耗情况,如CPU,IO,IPC,SWAP等,以及发生PAGE FAULTS, CONTEXT SWITCHE等等,同时还能得到该Query执行过程中MySQL所调用的各个函数在源文件中的位置。
1、开启profiling参数 1-开启,0-关闭
#开启profiling参数 1-开启,0-关闭set profiling=1;SHOW VARIABLES LIKE '%profiling%';
2、然后执行一条Query
3、获取系统保存的profiling信息
show PROFILES;
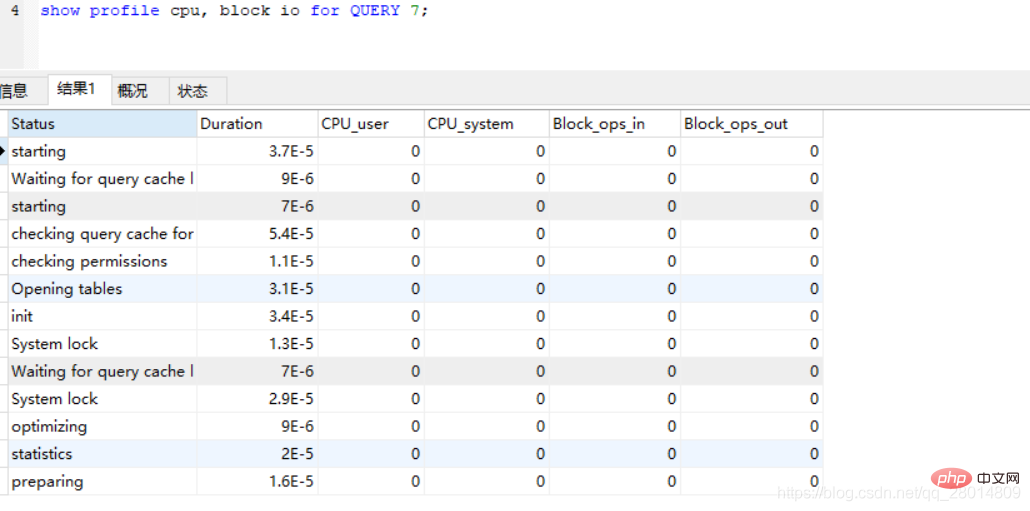
 4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
show profile cpu, block io for QUERY 7;
三、合理利用索引
1、什么是索引
简单来说,在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或者多列的值进行排序的一种存储结构。就像书的目录,可以根据目录中的页码快速找到需要的内容。
在MySQL中主要有四种类型索引,分别是:B-Tree索引,Hash索引,FullText索引,R-Tree索引,下面主要说一下我们常用的B-Tree索引,其他索引可以自行查找资料。
2、索引的数据结构
一般来说,MySQL中的B-Tree索引的物理文件大多数都是以平衡树的结构来存储的,也就是所有实际需要存储的数据都存储于树的叶子节点,二到任何一个叶子节点的最短路径的长度都是完全相同的。MySQL中的存储引擎也会稍作改造,比如Innodb存储引擎的B-Tree索引实际上使用的存储结构是B+Tree,在每个叶子节点存储了索引键相关信息之外,还存储了指向相邻的叶子节点的指针信息,这是为了加快检索多个相邻的叶子节点的效率。
在Innodb中,存在两种形式的索引,一种是聚簇形式的主键索引,另外一种形式是和其他存储引擎(如MyISAM)存放形式基本相同的普通B-Tree索引,这种索引在Innodb存储引擎中被称作二级索引。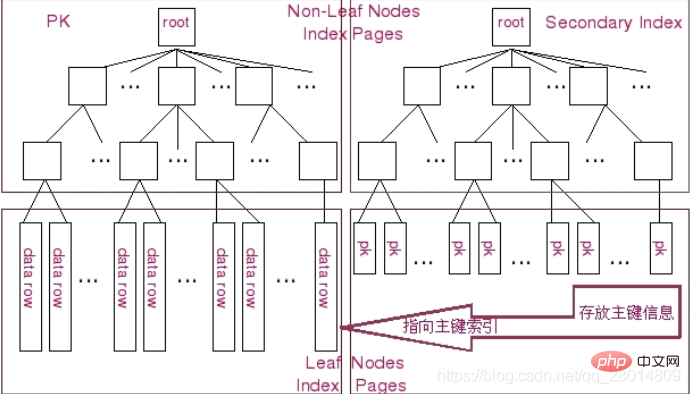
图示中左边为 Clustered 形式存放的 Primary Key,右侧则为普通的 B-Tree 索引。两种索引在根节点和 分支节点方面都还是完全一样的。而 叶子节点就出现差异了。在主键索引中,叶子结点存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据,整个数据以主键值有序的排列。而二级索引则和其他普通的 B-Tree 索引没有太大的差异,只是在叶子结点除了存放索引键的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过二级索引来访问数据的话,Innodb 首先通过二级索引的相关信息,通过相应的索引键检索到叶子节点之后,需要再通过叶子节点中存放的主键值再通过主键索引来获取相应的数据行。
MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的二级索引的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在叶子节点上面除了存放索引键信息之外,再存放能直接定位MyISAM 数据文件中相应的数据行的信息(如 Row Number),但并不会存放主键的键值信息。
3、索引的利弊
优点: 提高数据的检索速度,降低数据库的IO成本;
缺点:查询需要更新索引信息带来额外的资源消耗,索引还会占用额外的存储空间
4、如何判断是否需要建立索引
上面说了索引的利弊,我们知道索引并不是越多越好,索引也会带来副作用。那么我们该怎么判断是否需要建立索引呢?
1、 较频繁的作为查询条件的字段应该创建索引;
2、更新频繁的字段不适合建立索引;
3、唯一性太差的不适合创建索引,如状态字段;
4、不出现在where中的字段不适合创建索引;
5、单索引还是组合索引?
In general application scenarios, as long as one of the filter fields can filter more than 90% of the data in most scenarios, and other filter fields will be updated frequently, I generally prefer to create a combined index, especially This is especially true in scenarios with high concurrency. Because when concurrency is increased, even if we save a small amount of IO consumption for each query, the total amount of resources saved is still very large because the execution volume is very large.
But when we create a combined index, it does not mean that all fields in the query conditions must be placed in one index. We should let one index be used by multiple queries and minimize the number of indexes to reduce the cost of updates. and storage costs.
MySQL provides us with a function that reduces the optimization of the index itself, which is "Prefix Index". That is to say, we can only use the previous part of a field as the index key to index the field, reducing the space occupied by the index and improving the access efficiency of the index. Of course, prefix indexes are only suitable for fields where the prefixes are relatively random and have few repeats.
6. Index selection
1. For single-key indexes, try to filter the best index for the current query;
2. When selecting a combined index When selecting, the field with the best filterability in the current query should be ranked higher in the index field order;
3. When selecting a combined index, try to choose one that can include more fields in the where clause of the current query. Index;
4. Try to select the appropriate index by analyzing statistical information and adjusting the way the query is written to reduce the choice of index control through manual Hint, because this will cause high maintenance costs in the future.
7. MySQL index restrictions
1. The sum of the MyISAM storage engine index key lengths cannot exceed 1000 bytes;
2. BLOB and TEXT type fields can only Can create prefix index;
3. MySQL does not support function index;
4. When using != or , MySQL index cannot be used;
5. After filtering fields using function operations, MySQL index Unable to use;
6. When the near field types in the jion statement are inconsistent, the MySQL index cannot be used;
7. If you use like to match before (such as: '�a'), the MySQL index cannot be used;
8. When using non-equivalent queries, MySQL cannot use HASH index;
9. When the character type is a number, you must use ='1'. You cannot use = 1 directly;
10. Do not use or. Use in instead of union all;
8. Join principle and optimization
Join principle: In MySQL, there is only one join algorithm. It is the famous nested loop. In fact, it uses the result set of the driving table as the basic data of the loop, and then uses the data in the result set as filter conditions to query the data in the next table one by one, and then merges the results. If there are still recent participants, the previous recent result set will be used as the basic data for the cycle, and the cycle will be traversed again, and so on.
Optimization:
1. Reduce the total number of loops in the Join statement as much as possible (remember the small result set driving the large result set mentioned earlier);
2. Prioritize optimization Inner loop;
3. Ensure that the Join condition field on the driven table in the Join statement has been indexed;
4. When there is no guarantee that the Join condition field of the driven table is indexed and memory resources are sufficient, do not Stingy Join buffer settings (join buffer can only be used in All, index, and range);
9. ORDER BY optimization
In MySQL, There are only two types of ORDER BY implementations:
1. Obtain ordered data directly through ordered indexes, so that the ordered data required by the client can be obtained without any sorting operation;
2 , Sort the data returned in the storage engine through the MySQL sorting algorithm and then return the sorted data to the client.
Using index sorting is the best method, but if there is no index Lin Yong, MySQL mainly implements two algorithms:
1. Take out the fields used for sorting that meet the filtering conditions And the row pointer information that can directly locate the row data, perform the actual sorting operation in the Sort Buffer, and then use the sorted data to return to the table according to the row pointer information to obtain the data of other fields requested by the client, and then return it to Client;
2. According to the filter conditions, retrieve the data of the sorted fields and all other fields requested by the client at once, store the fields that do not need to be sorted in a memory area, and then sort the fields in the Sort Buffer The field and row pointer information are sorted, and finally the sorted row pointer is used to match and merge the result set with the row pointer information stored in the memory area together with other fields, and then returned to the client in order.
Compared with the first algorithm, the second algorithm mainly reduces the secondary access of data. After sorting, there is no need to go back to the table to retrieve data, saving IO operations. Of course, the second algorithm will consume more memory, which is a typical optimization method that trades space for time.
# ##For multi-table Join sorting, the result set of the previous Join is first stored in the temporary table through a temporary table, and then the data of the temporary table is fetched into the Sort Buffer for operation.For non-index sorting, try to choose the second algorithm for sorting. The methods are:
1. Increase the max_length_for_sort_data parameter setting:
MySQL determines which algorithm to use through the parameter max_length_for_sort_data Determined, when the maximum length of the field we return is less than this parameter, MySQL will choose the second algorithm, and vice versa. Therefore, if there is sufficient memory, increasing this parameter value can allow MySQL to choose the second algorithm;
2. Reduce unnecessary return fields
The same principle as above, if there are fewer fields, it will Try to be smaller than the max_length_for_sort_data parameter;
3. Increase the sort_buffer_size parameter setting:
Increasing sort_buffer_size is not to allow MySQL to choose an improved version of the sorting algorithm, but to allow MySQL to minimize the number of steps in the sorting process. Segment the data that needs to be sorted, because this will cause MySQL to have to use temporary tables to perform exchange sorting.
4. Finally
Tuning is actually a very difficult thing, and tuning is not limited to the above query tuning. Such as table design optimization, database parameter tuning, application tuning (reduce loop operations on the database, batch addition; database connection pool; cache;) and so on. Of course, there are many tuning techniques that can only be truly appreciated in actual practice. Only by constantly trying to improve yourself based on theory and facts can you become a true tuning master.
Related free learning recommendations:mysql database(Video)
The above is the detailed content of Detailed explanation of MySQL query optimization. For more information, please follow other related articles on the PHP Chinese website!































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



