


Recommended (free):SQL tutorial
Gap lock plus row lock, it is easy to judge whether An error occurred when a lock wait problem occurred.
Because gap locks are only effective under the repeatable read isolation level, this article defaults to repeatable read.
Lock rules
Data preparation
Table name: t
New data: (0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25)
The following examples are basically illustrated with pictures, so I recommend You can read it against the manuscript. Some examples may "destroy the three views." It is also recommended that you practice it yourself after reading the article.
Case
Equal value query gap lock
Equal value query gap lock
There is no id=7 in table t, so according to principle 1, the locking unit is next-key lock, so the locking range of session A is (5,10]
At the same time, according to optimization 2, equivalent query (id=7), but id=10 is not satisfied, the next-key lock degenerates into a gap lock, so the final lock range (5,10)
So, if session B inserts the record with id=8 into this gap, it will be locked, but session C can modify the line with id=10.
Non-unique index equivalent lock
Lock only added to non-unique index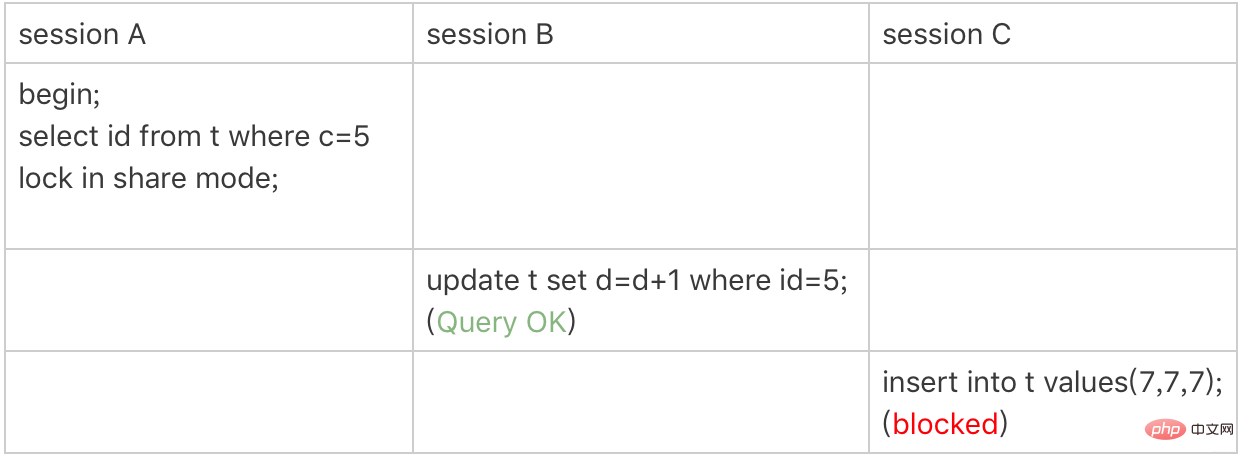
session A wants to add a read lock to the row c=5 of index c
According to principle 1, the locking unit is next-key lock, so add next-key lock to (0,5]
c isnormal Index, so only the record c=5 is accessed.cannot stop immediately. It needs totraverse to the rightand give up only when c=10 is found. According to principle 2, access must be locked, so (5,10] needs to be added with next-key lock
and it also conforms to optimization 2: equivalence judgment, traverse to the right, the last value does not meet the equivalence condition of c=5, so it is degraded Gap lock (5,10)
According to principle 2, only the accessed object will be locked. This query uses a covering index and does not need to access the primary key index, so no lock is added to the primary key index, so session B The update statement can be executed.
But if session C wants to insert (7,7,7), it will be locked by the gap lock (5,10) of session A.
In this example, lock in share mode only locks the covering index, but it is different if it is for update. When executing for update, the system will think that you want to update the data next, so it will give the rows that meet the conditions on the primary key index. Add a row lock.
This example shows that the lock is added to the index; at the same time, it gives us guidance if you want to use lock in share mode to add a read lock to the row to prevent the data from being updated. , you must bypass the optimization of the covering index and add fields that do not exist in the index to the query fields. For example, change the query statement of session A to select d from t where c=5 lock in share mode. You can verify it yourself Here's the effect.
3 Primary key index range lock
Range query.
For our table t, do the following two query statements have the same locking range?
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
You may think, id definition Being of type int, these two statements are equivalent, right? In fact, they are not completely equivalent.
Logically, these two query statements are definitely equivalent, but their locking rules are different. Now, let's let session A execute the second query statement to see the locking effect.
Figure 3 Locks for range queries on the primary key index
Now we will use the locking rules mentioned above to analyze what locks will be added to session A?
When starting execution, we need to find the first row with id=10, so it should be next-key lock(5,10]. According to optimization 1, the equivalent condition on the primary key id degenerates into a row Lock, only the row lock for the row with id=10 is added.
The range search continues to search later, and stops when the row with id=15 is found, so next-key lock(10,15] needs to be added.
So, the lock scope of session A at this time is the primary key index, row lock id=10 and next-key lock(10,15]. In this way, you can understand the results of session B and session C. .
You need to pay attention to one thing here. When session A locates the row with id=10 for the first time, it is judged as an equivalent query. When scanning to the right to id=15, the range is used. Query and judge.
Let’s look at range query locking again. You can compare it with Case 3
Non-unique index range lock
| session_1 | session_2 | session_3 |
|---|---|---|
| select * from t where c>=10 and c<11 for update; |
||
##insert into t values(8,8 ,8);(blocked) |
||
| ##update t set d =d 1 where c=15;(blocked) |
c is anon-unique indexnext-key lock of c.Unique index range lock bug
The first four cases use two principles and two optimizations, and then look at the locking rule bug case.
to the index id. Because id is the only key, the loop is judged to the line
id=20, and since this is a range scan, the # on the id ##(15,20] next-key lockSo if session2 wants to update id=20, this line will be blocked.If session3 wants to insert id=16, it will also Blocked.Logically speaking, it is not necessary to lock the row id=20, because the unique index scans to id=15 to determine that there is no need to continue traversing. However, this is still done in the implementation, which may be a bug.
Example of "equal value" on non-unique index
To better illustrate the concept of "gap".
Since the non-unique index contains the primary key value, so there cannot be two "identical" rows.
But now although there are two c=10, their primary key value id is different, so there is a gap between the two c=10 records .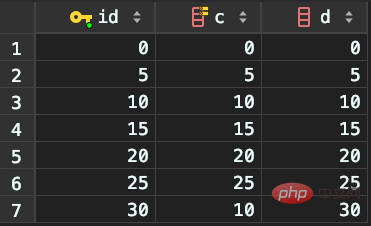
6
delete locking logic is similar to
, which also conforms to the initial rules.
session_1
| session_3 | ||
|---|---|---|
| where id=20;(blocking) |
||
insert into t values(16,16,16);(blocking) |
session1 is a range query |
| begin; | delete * from t||
|---|---|---|
##insert into t | values(13,13,13);(blocking)
||
When traversing session1, first access the first c=10: |
According to principle 1, add (c=5,id=5) to (c=10,id=10) next-key lock |
session_2
The delete statement of session1 adds limit 2. You know that there are actually only two records with c=10 in table t. Therefore, whether or not limit 2 is added, the effect of deletion is the same, but the effect of locking is different. It can be seen that the insert statement of session B passed, which is different from the result of Case 6.
This is because the delete statement in Case 7 explicitly adds a limit of limit 2, so after traversing the line (c=10, id=30), there are already two statements that meet the condition, and the loop It's over.
Therefore, the locking range on index c becomes the front-open and back-closed range from (c=5, id=5) to (c=10, id=30), as shown in the figure below :
Locking effect with limit 2
You can see that the gap after (c=10,id=30) is not within the locking range , so the insert statement to insert c=12 can be executed successfully.
The guiding significance of this example to our practice is to try to add a limit when deleting data. This not only controls the number of deleted data, making the operation safer, but also reduces the scope of locking.
A deadlock example
In the previous example, when we analyzed it, we analyzed it according to the logic of next-key lock, because this analysis compares convenient. Finally, let's look at another case to illustrate: next-key lock is actually the result of the sum of gap lock and row lock.
You must be wondering, wasn’t this concept mentioned at the beginning? Don't worry, let's take a look at the following example first:
Operation sequence of case 8
session A After starting the transaction, execute the query statement and add lock in share mode, and add lock in share mode to the index Next-key lock(5,10] and gap lock(10,15) are added to c; the update statement of
session B also needs to add next-key lock(5,10] to index c. Enter lock waiting;
Then session A wants to insert the row (8,8,8) again, which is locked by the gap lock of session B. Due to a deadlock, InnoDB rolls back session B.
You may ask, hasn’t the application for next-key lock of session B not been successful yet?
In fact, this is the case, session B’s “add next-key lock(5,10]” operation , is actually divided into two steps. First, add the gap lock of (5,10), and the lock is successful; then add the row lock of c=10, and then it is locked.
In other words, When we analyze the locking rules, we can use next-key lock to analyze. But you must know that during specific execution, it must be divided into two stages: gap lock and row lock.
Summary
All cases are verified under repeatable read. Repeatable read follows the two-phase lock protocol. All locked resources are released when the transaction is committed or rolled back.
In the last case, you can clearly know that next-key lock is actually implemented by gap lock plus row lock. If you switch to read-committed isolation level (read-committed), it will be easier to understand. During the process, the gap lock part is removed, that is, only the row lock part is left.
There is another optimization under the read commit isolation level, that is: the row lock added during the statement execution, after the statement execution is completed , it is necessary to directly release the row lock on the "row that does not meet the conditions" without waiting for the transaction to be committed.
Under the read-commit isolation level, the lock range is smaller and the lock time is shorter, so many businesses Read commit is also used by default.
When the business needs to use repeatable read, it solves the phantom read problem and maximizes the system's ability to process transactions in parallel.
Gap lock plus row lock, It is easy to make mistakes in judging whether lock waiting will occur.
Because gap locks are only effective under the repeatable read isolation level, this article defaults to repeatable read.
More For related knowledge, please visitSQLfree column~~
| begin; | delete * from twhere c=10 limit 2 |
|---|---|
| values(13,13,13);(blocking) |
|
The above is the detailed content of shock! There are so many locks in one SQL statement.... For more information, please follow other related articles on the PHP Chinese website!






























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



