



Free learning recommendation:python video tutorial
python crawling micro Boresou is stored in Mysql
Final effect
Not much nonsense, just go to the picture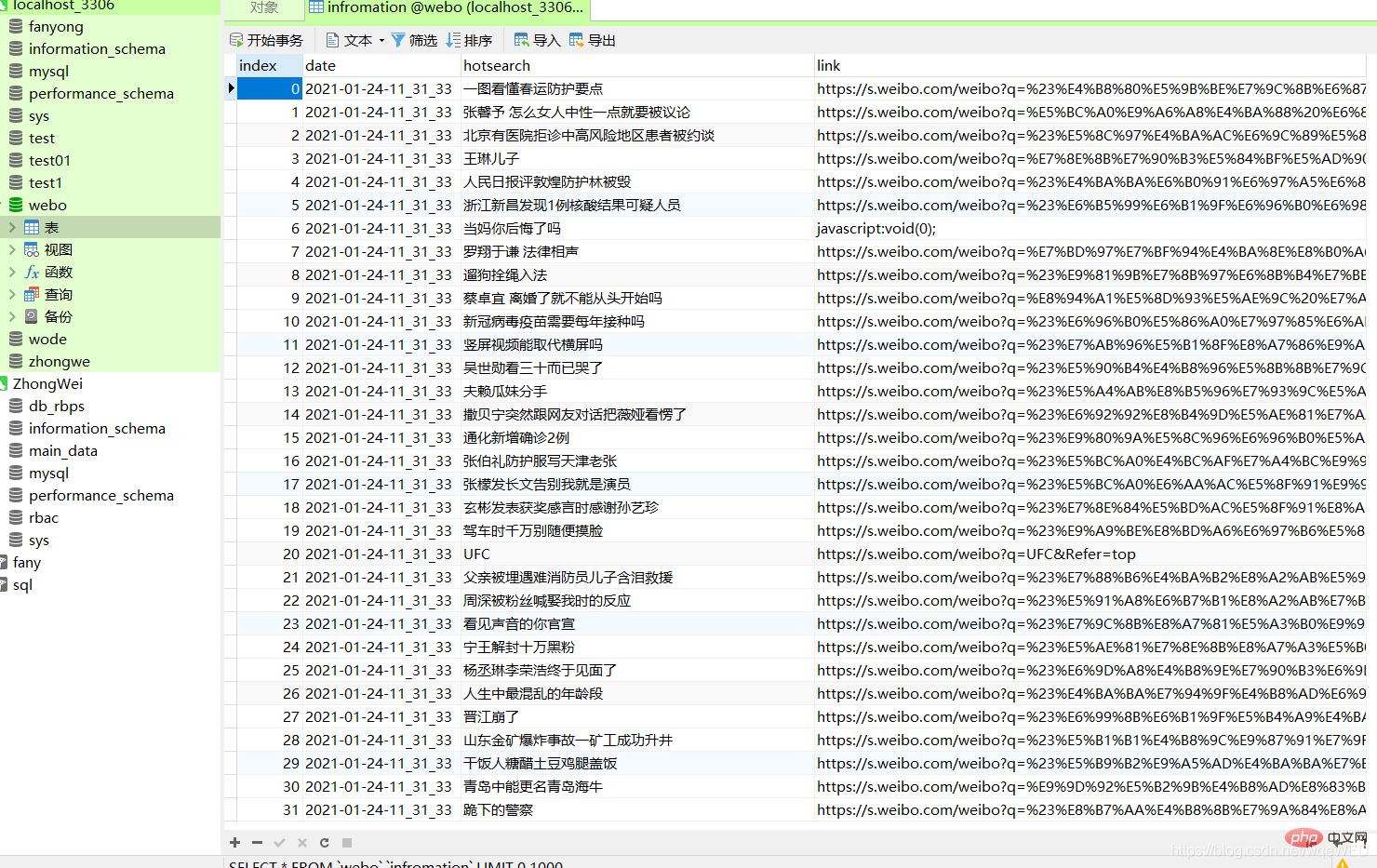
Here you can clearly see that the database contains date, content, and website link
Let’s analyze how to implement it
Library used
import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd
Target analysis
This is a hotly searched link on Weibo: Click me to go to the target webpage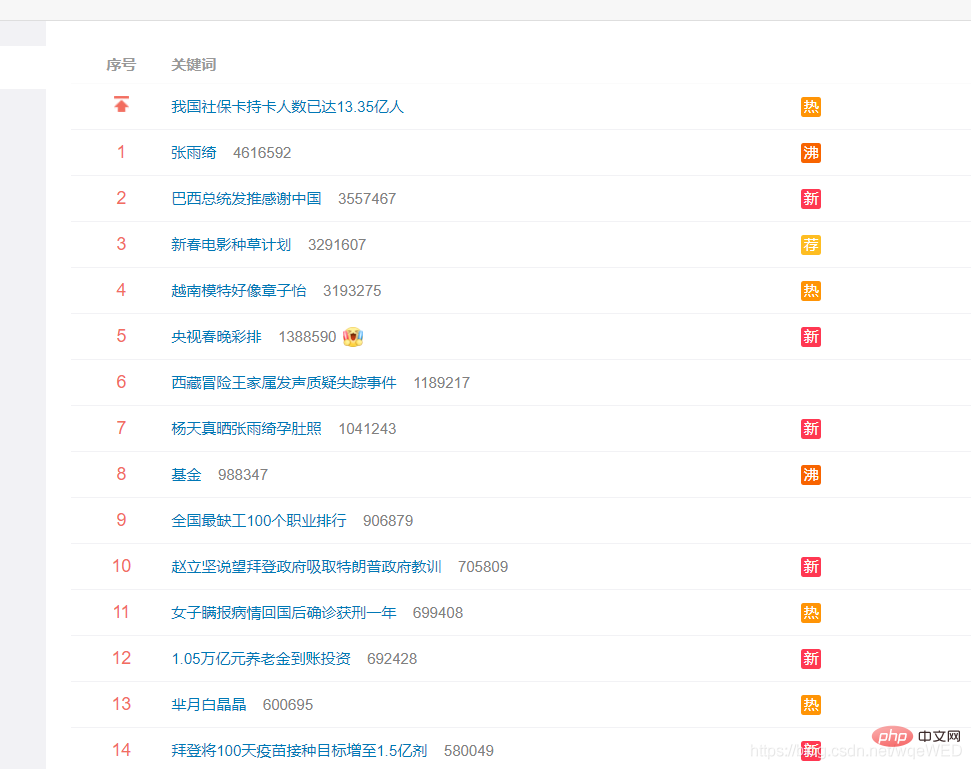
First we use selenium to request the target web page
Then we use xpath to locate the web page elements and traverse to obtain all the data
Then use pandas to generate a Dataframe object and store it directly in the database
1: Get data
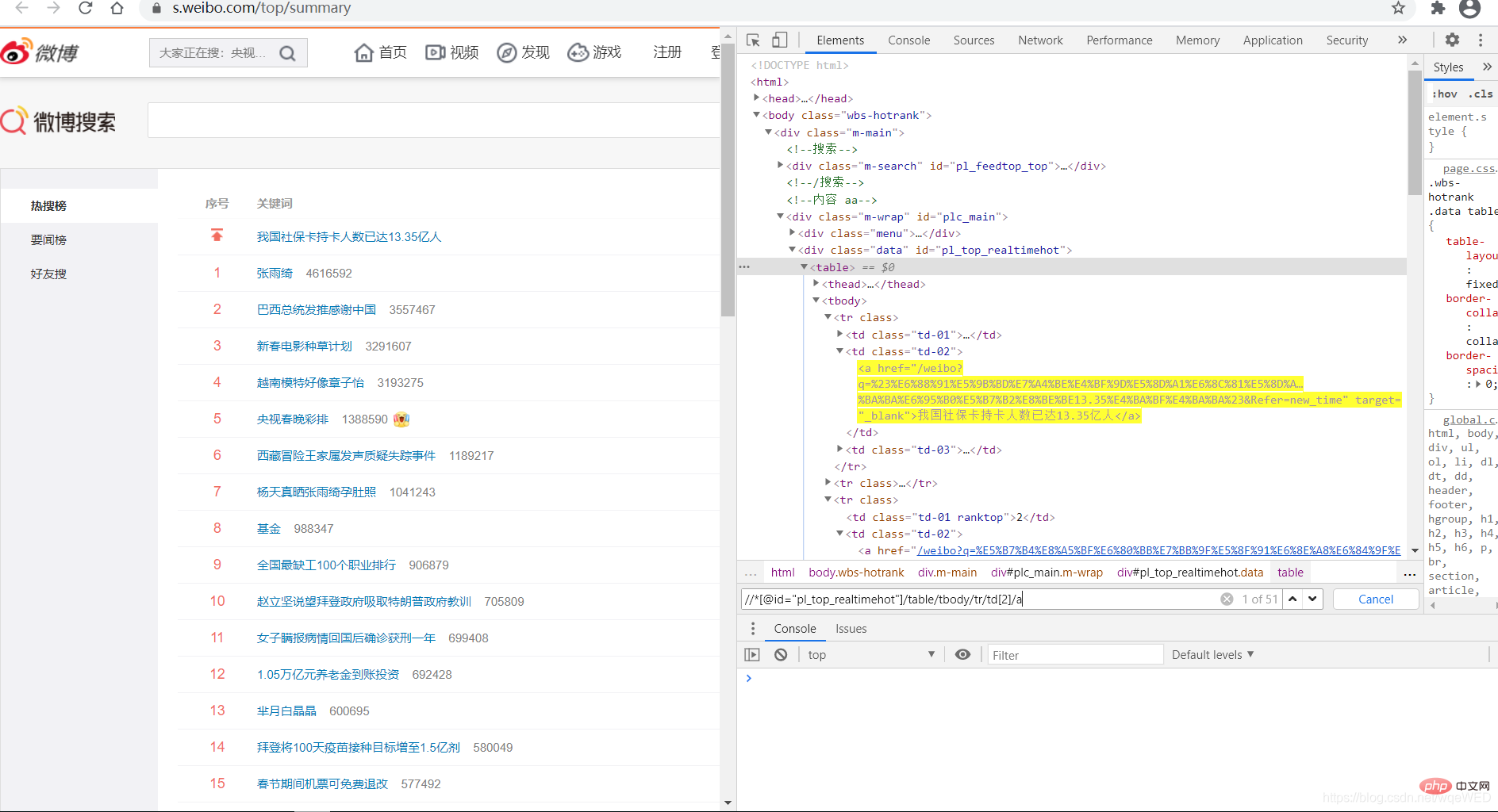
We see that 51 pieces of data can be obtained using xpath. These are the hot searches, from which we can get the links and Title content
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据 context = [i.text for i in c] # 得到标题内容 links = [i.get_attribute('href') for i in c] # 得到link
Then we use the zip function to merge date, context, and links
The zip function combines several lists into one list, and merges the data in the list into one tuple by index. , this can produce pandas objects.
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
The date can be obtained using the time module
2: Link to the database
This is very easy
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8") pdf.to_sql(name='infromation', con=enging, if_exists="append")
Total Code
from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd def get_data(): url = r"https://s.weibo.com/top/summary" # 微博的地址 option = ChromeOptions() option.add_argument('--headless') option.add_argument("--no-sandbox") browser = Chrome(options=option) browser.get(url) all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') context = [i.text for i in all] links = [i.get_attribute('href') for i in all] date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime()) dates = [] for i in range(len(context)): dates.append(date) # print(len(dates),len(context),dates,context) dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link']) # pdf.to_sql(name=in, con=enging, if_exists="append") return pdf def w_mysql(pdf): try: enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8") pdf.to_sql(name='infromation', con=enging, if_exists="append") except: print('出错了') if __name__ == '__main__': xx = get_data() w_mysql(xx)
I hope it can help you a little, and let’s make progress and grow together together!
I wish you all a Happy New Year! ! !
Related free learning recommendations:python tutorial(Video)
The above is the detailed content of Python realizes crawling Weibo hot searches and storing them in Mysql. For more information, please follow other related articles on the PHP Chinese website!































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



