


python tutorialcolumn today summarizes several ways to use Python to operate PDF.

01
Preface
Hello everyone, the case about Python operating PDF has been written before I have experienced a?PDF Batch Merge. The original intention of this case is just to provide you with a convenient script, and there is not much explanation of the principle. It involves a very practical module for PDF processing,PyPDF2. This article will analyze this module carefully, mainly involving
02
Basic operation
PyPDF2 The code to import the module is usually:
from PyPDF2 import PdfFileReader, PdfFileWriter复制代码
Two methods are imported here:
Next, we will further understand the wonders of these two tools through several cases. The sample file used is the pdf of 5 invoices
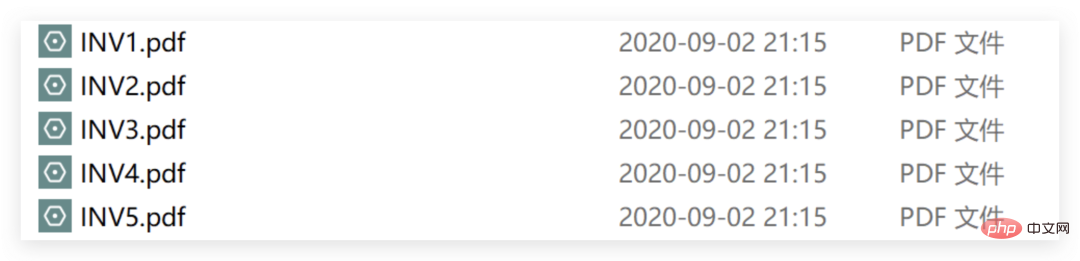
Each invoice PDF consists of two pages:
03
MERGE
One job is tomerge 5 invoice pdfs into 10 pages. How should the reader and writer cooperate here?
The logic is as follows:
There is another important knowledge point here: the reader can only hand over the read content to the writer page by page.
Therefore, steps 1 and 2 in the logic are actuallynot independent steps, but after the reader reads a pdf, it cycles through all pages of the pdf Once, page by page is handed over to the writer. Finally, wait until all reading work is completed before outputting.
Looking at the code can make the idea clearer:
from PyPDF2 import PdfFileReader, PdfFileWriter path = r'C:\Users\xxxxxx' pdf_writer = PdfFileWriter() for i in range(1, 6): pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i)) for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) with open(path + r'\合并PDF\merge.pdf', 'wb') as out: pdf_writer.write(out)复制代码
Since all the content needs to be handed over to the same writer and finally output together, the initialization of the writer must be within the loop body External.
If it is inside the loop body, it will becomeEvery time a pdf is accessed, a new writer is generated, so that each reader is handed over to the writer The content will berepeatedly overwritten, and our merging requirements cannot be achieved!
The code at the beginning of the loop body:
for i in range(1, 6): pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))复制代码
The purpose is to read a new one each time it loops The pdf file is handed over to the reader for subsequent operations. In fact, this way of writing is not very recommended. Since the naming of each PDF happens to be very regular, you can directly specify the numbers for looping. A better way is to use theglobmodule:
import glob for file in glob.glob(path + '/*.pdf'): pdf_reader = PdfFileReader(path)复制代码
pdf_reader.getNumPages():in the code can get the number of pages in the reader, combined withrangecan traverse all pages of the reader.
pdf_writer.addPage(pdf_reader.getPage(page))can hand over the current page to the writer.
Finally, usewithto create a new pdf and output it through thepdf_writer.write(out)method of the writer.
04
Split
If you understand the cooperation of readers and writers in the merge operation, then splitting is easy to understand Okay, here we take splittingINV1.pdfinto two separate pdf documents as an example. Let’s also walk through the logic first:
Through this code logic, we also It can be understood that the initialization and output positions of the writer must be within the loop body of each page of the PDF reading loop, not outside the loop
The code is very simple:
from PyPDF2 import PdfFileReader, PdfFileWriter path = r'C:\Users\xxx' pdf_reader = PdfFileReader(path + '\INV1.pdf') for page in range(pdf_reader.getNumPages()): # 遍历到每一页挨个生成写入器 pdf_writer = PdfFileWriter() pdf_writer.addPage(pdf_reader.getPage(page)) # 写入器被添加一页后立即输出产生pdf with open(path + '\INV1-{}.pdf'.format(page + 1), 'wb') as out: pdf_writer.write(out)复制代码
05
Watermark
This time the work is to add the following image as a watermark toINV1.pdf
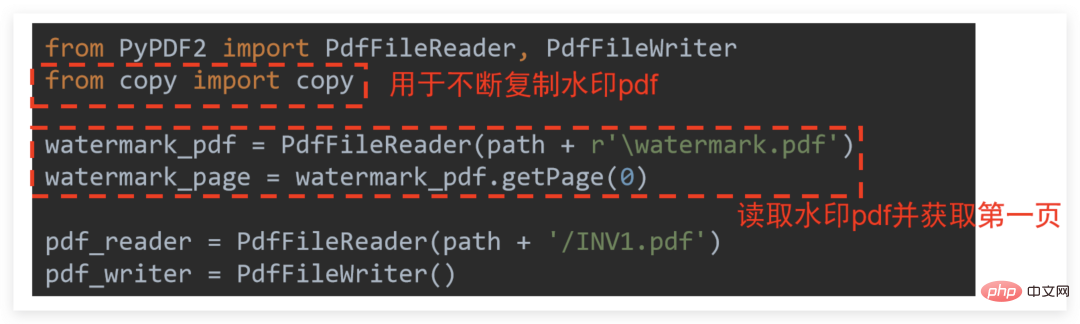
The first step is preparation.Insert the picture that needs to be used as a watermark into Word, adjust the appropriate position and save it as a PDF file. Then you can code. You need to use thecopymodule additionally. See the figure below for a detailed explanation:
is to combine the reader and writer Initialize and read the watermarked PDF page first for later use. The core code is a little difficult to understand:
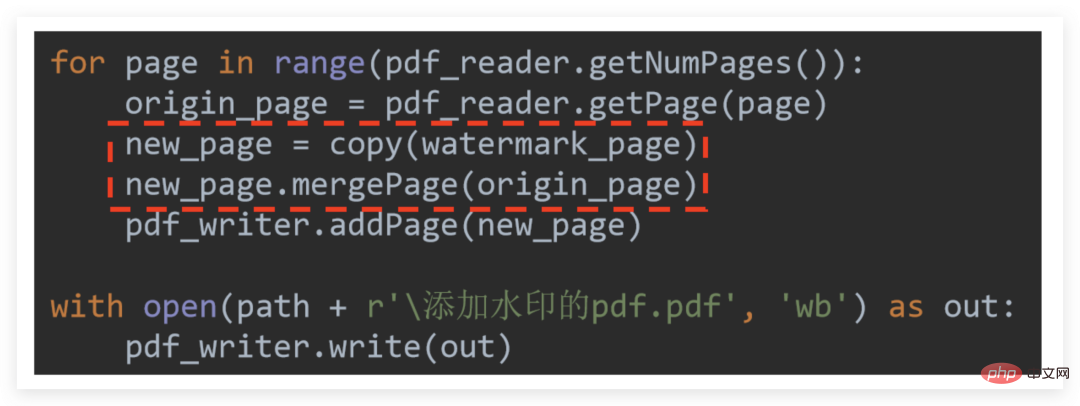
Adding watermarks is essentiallymerging the watermarked PDF page with each page that needs to be watermarked
Because the PDF that needs to be watermarked There may be many pages, but the watermarked PDF only has one page, so if the watermarked PDFs are merged directly, it can beabstractly understood as after adding the first page, the watermarked PDF page will be gone.
Therefore,cannot be merged directly, but the watermarked PDF page must be continuouslycopyout into a new page for later usenew_page, and then use it.mergePageThe method completes the merge with each page, and hands the merged page to the writer for final unified output!
About the use of.mergePage:Appears on the page below.mergePage (Appears on the page above), the final effect is as shown below:
06
Encryption
Encryption is very simple, just remember:"Encryption is for writer encryption"
So you only need to callpdf_writer.encrypt (password)# after the relevant operation is completed.
## Take the encryption of a single PDF as an example: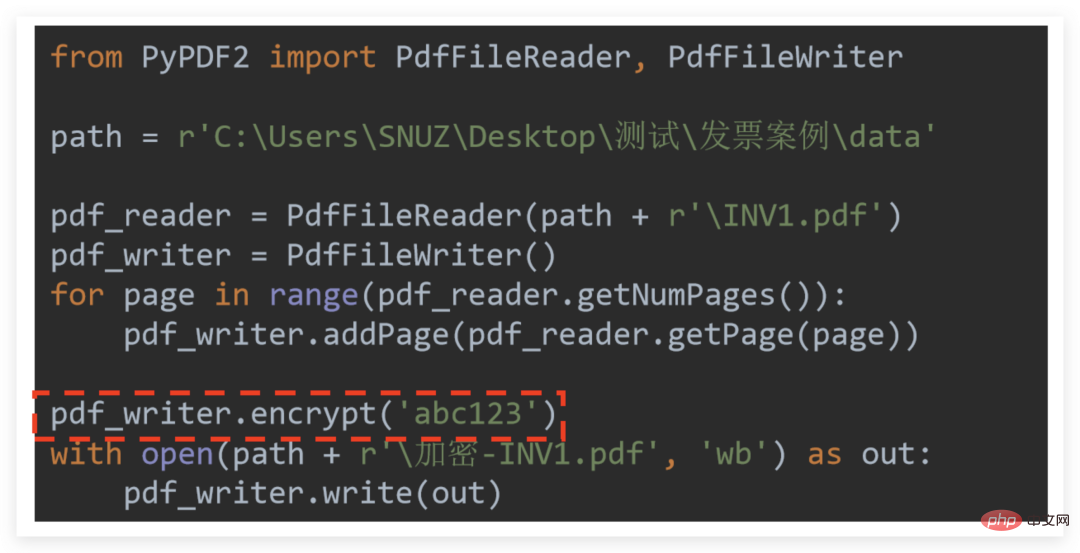
PDFMerging, splitting, encryption, and watermarking, we can also usePython combined with Excel and Word to achieve more automation requirements, these are left to the readers to develop by themselves. Python resource sharing Junyang 1075110200, which contains installation packages, PDFs, and learning videos. This is a gathering place for Python learners, both zero-based and advanced are welcome
Finally, I hope everyone can understand Python office automation One core isbatch operation-free your hands andautomate complex work!
More related free learning recommendations:python tutorial(video)
The above is the detailed content of Summarize several methods of operating PDF with Python. For more information, please follow other related articles on the PHP Chinese website!




























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



