



80% of the world's crawlers are developed based on Python. Learning crawler skills can provide important data sources for subsequent big data analysis, mining, machine learning, etc.
Python crawler needs to install related libraries:
Libraries involved in python crawler:
Request library, parsing library, storage library, tool library
1. Request library: urllib/re/requests
(1) urllib/re is the library that comes with python by default and can be verified by the following command:
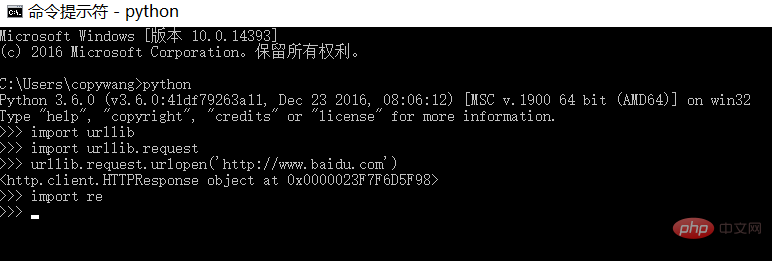
No error message is output, indicating that the environment is normal
(2) requests installation
2.1 Open CMD and enter
pip3 install requests
2.2 Wait for installation and verify

(3) Selenium installation (drives the browser for website access behavior)
3.1 Open CMD and enter
pip3 install selenium
3.2 Install chromedriver
Website: https://npm.taobao.org/
Decompress the downloaded compressed package and put the exe into D:\Python3.6.0\Scripts\
This path only needs to be in the PATH variable
3.3 After the installation is completed, verify

Press Enter and the chrome browser interface will pop up
3.4 Install other browsers
Interfaceless browser phantomjs
Download URL: http://phantomjs.org/
After downloading, unzip and put the entire directory Go to D:\Python3.6.0\Scripts\ and add the path to the bin directory to the PATH variable
Verification:
Open CMD
phantomjs console.log('phantomjs') CTRL+C python from selenium import webdriver driver = webdriver.PhantomJS() dirver.get('http://www.baidu.com') driver.page_source
2. Parsing library:
2.1 lxml (XPATH)
Open CMD
pip3 install lxml
or download from https://pypi.python.org, for example, lxml-4.1.1-cp36- cp36m-win_amd64.whl (md5), first download the whl file
pip3 install 文件名.whl
2.2 beautifulsoup
Open CMD, you need to install lxml
pip3 install beautifulsoup4
Verification
python from bs4 import BeautifulSoup soup = BeautifulSoup('<html></html>','lxml')
2.3 pyquery (similar to jquery syntax)
Open CMD
pip3 install pyquery
Verify the installation results
python from pyquery import PyQuery as pq doc = pq('<html>hi</html>') result = doc('html').text() result

3. Repository
3.1 pymysql (operating MySQL, relational database)
Installation:
pip3 install pymysql
Test after installation:
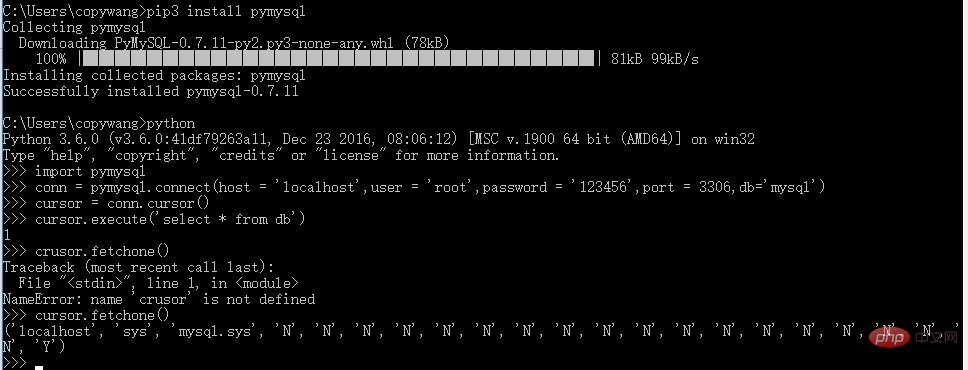
3.2 pymongo (operating MongoDB, key-value)
Installation
pip3 install pymongo
Verification
python
import pymongo
client = pymongo.MongoClient('localhost')
db = client['testdb']
db['table'].insert({'name':'bob'})
db['table'].find_one({'name':'bob'}) 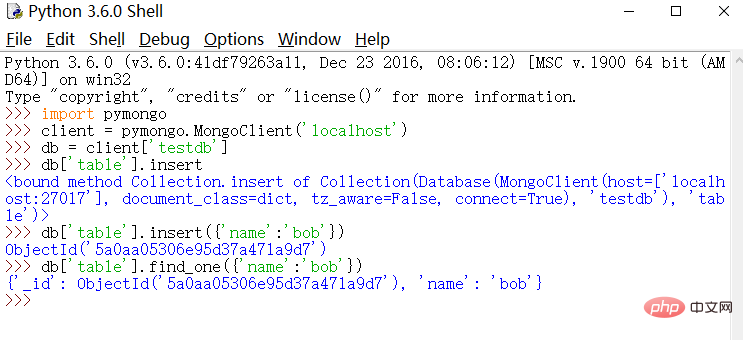
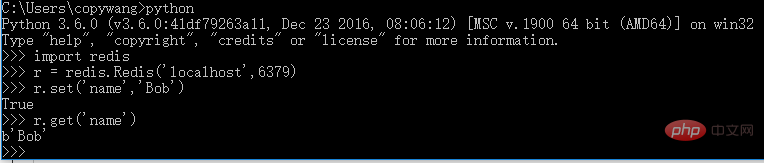
3.3 redis (distributed crawler, maintain crawling queue)
Installation:
pip3 install redis
Verification:
4. Tool library
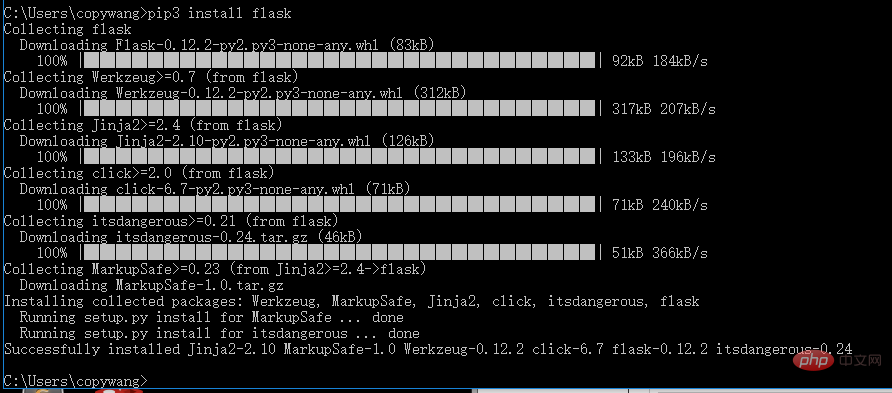
4.1 flask (WEB library)
pip3 install flask
4.2 Django (distributed crawler maintenance system)
pip3 install django
4.3 jupyter (notepad running on the web page, supports markdown, and can run code on the web page)
pip3 install jupyter
Verification:
After opening CMD
jupyter notebook
, you can directly run the code on the web page Create notepad, code blocks and Markdown blocks, support printing
[Related recommendations]
1. Python crawler library and related tools
2. Python crawler introductory tutorial
The above is the detailed content of What needs to be installed for python crawler. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



