


In 1946, the world’s first electronic computer was born at the University of Pennsylvania in the United States. Its name is: ENICAC. This computer is relatively heavy and its calculation speed is not fast, but it represents the arrival of the computer age and has fundamental significance in the future development of the Internet.
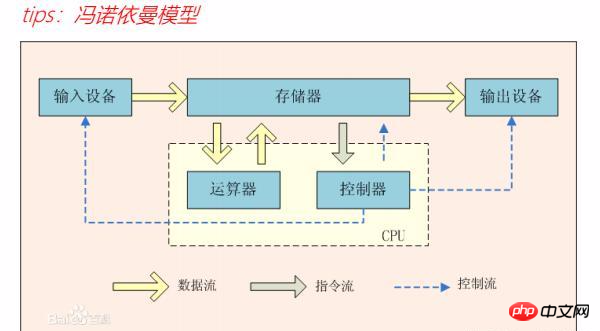
The computer is composed of five parts, namely: input device, output device, memory. The memory contains arithmetic units and controllers. There is a von Neumann model that is a very vivid object computer. The composition has been described, but the computer also has data flow, instruction flow, and control flow to perform calculations and operate normally. As shown in the picture:
After ENIAC, electronic computers entered the era of mainframes dominated by IBM. In 1946, the first IBM mainframe The machine SYSTEM/360 was born, which allowed IBM to dominate the entire mainframe computer industry in the 1950s and 1960s. In the era of mainframes, computer architecture developed in two directions: CISC (computer language instruction set executed by microprocessors) and CPU Architectures range from inexpensive personal PCs to expensive RISC (reduced instruction set computer) small UNIX servers.
The emergence of mainframes, with their computing power and processing power, high stability and security, has led to the development of the computing field for a long time. However, centralized computer systems have brought some problems, and they are increasingly unable to meet the needs of users. For example:
1. Large-scale hosts are very expensive, and ordinary small businesses cannot afford them.
2. Mainframes are more complex and the cost of training talents is relatively high.
3. A single point problem, such as a mainframe failure, will cause the entire system to be down and unable to operate, causing huge losses to the enterprise.
4. With the advancement of technology, the performance of personal PCs is getting higher and higher, and the cost is getting lower and lower.
Alibaba launched a drive to eliminate “IOE” in 2009
IOE refers to IBM's minicomputers, Oracle's databases and EMC's high-end storage devices. The movement away from IOE in 2009 continued until Alipay's last IBM minicomputer was offline in 2003.
Why go to IOE
Alibaba used Oracle for its database in the past, and used minicomputers and high-end storage devices to provide high-performance data processing and storage services. As the company's business volume increases and the number of users continues to increase, the traditional centralized architecture Oracle database encounters bottlenecks in expansion. Compared with traditional Oracle and DB2, they are mainly centralized. The shortcoming is the lack of scalability. Centralized expansion mainly uses upward expansion rather than horizontal expansion. This will happen sooner or later after a long time. System bottleneck.
Cluster
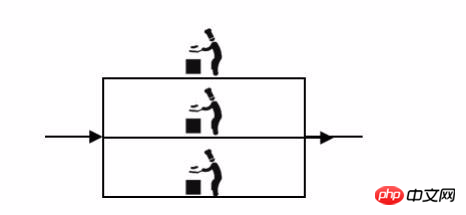
The small restaurant turned out to be a chef, cutting and washing vegetables, preparing ingredients and cooking. Later, when there were more customers, one chef in the kitchen was too busy, so another chef was hired. Both chefs were able to cook the same dishes. The relationship between the two chefs was a cluster.
## Distributed
In order to allow the chef to concentrate on cooking and make the dishes perfect, I also hired a side dish chef to be responsible for cutting vegetables, preparing vegetables, and preparing ingredients. The relationship between the chef and the side dish chef is distributed. Even one side dish chef is too busy. I hired a side dish chef to prepare these two side dishes. The relationship between teachers and teachers is a cluster. Therefore, there may be clusters in a distributed architecture, but clusters do not mean distributed.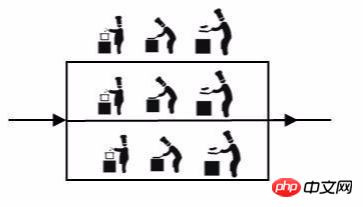
Node
Node refers to an individual program that can independently complete a set of logic according to a distributed protocol. In a specific project, a node represents a process on the operating system.Copy mechanism
Replica refers to providing redundancy for data or services in a distributed system.
Data copy refers to persisting the same data on different nodes. When data on a certain node is lost, the data can be read from the copy. Data copies are the only means of resulting data loss in distributed systems.
Service replicas represent multiple nodes providing the same service, and a high-availability solution for the service is achieved through the master-slave relationship.
Middleware
Middleware is in addition to the services provided by the operating system and does not belong to the application. It is between the application and system layers for developers. A type of software that conveniently handles communication, input, and output, allowing users to care about that part of their application.
A mature large-scale website system architecture is not designed perfectly from the beginning, nor does it have high performance, high availability, security and other features from the beginning. , but as the number of users increases, the expansion of business functions gradually improves and evolves. In this development process, development models, technical architecture, etc. will undergo great changes.
If the system has the following functions:
User module: user registration and management
Product module: Product Display and management
Transaction module: Create transactions and payment settlement
At the beginning of the system, both the application and the database are placed on one server.

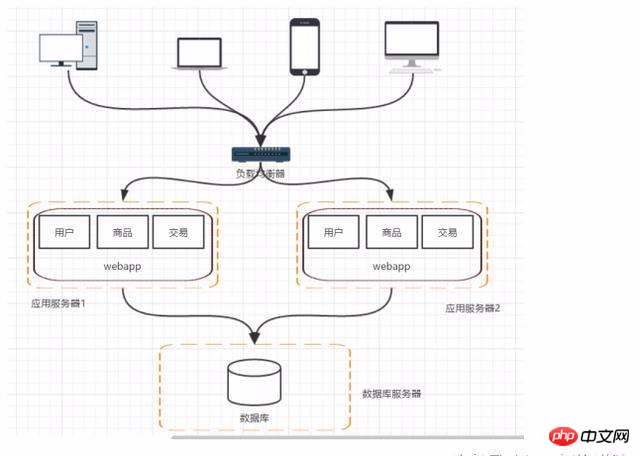
As the number of users of the website increases, the traffic increases, separate application server and database server The deployment of machines can increase system performance, improve access efficiency, and improve the load capacity and disaster recovery capabilities of a single machine.
As the number of visits and traffic increases, assuming that the database does not encounter bottlenecks, the application server cluster will be used to offload requests to improve Program performance. Existing problems: Who will forward the user's request and how to manage the session.
If read and write are separated, then future requests and query requests can go from Reading data in the library and writing data can be sent to the main library, but it will bring several problems:
1. Data synchronization between the master and slave databases: You can use the master-slave that comes with mysql Method to achieve master-slave replication
2. Selection of corresponding data source: Use third-party database middleware, for example: mycat
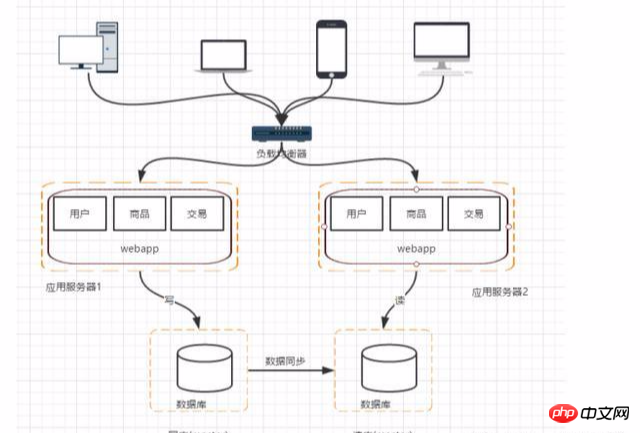
When the database is used to read the database, the performance of fuzzy queries is often not very good, especially for large Internet companies that want to search for modules The core is that you can use search engines. Although it can greatly improve the query speed, it will also cause some problems such as index construction.
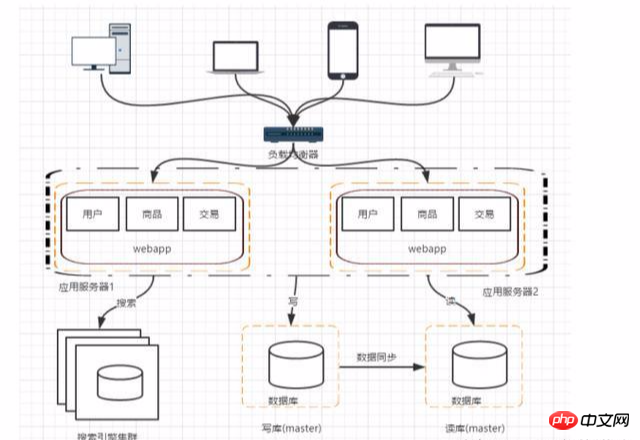
For some hot data, redis and memcache can be used as application layer cache; in addition In some scenarios, mongodb can be used to replace relational databases for storage.
Phase 7: Horizontal/vertical splitting of the database
Vertical splitting: Split different business data in the database into different in the database.
Horizontal split: Split the data in the same table into two or more databases. The reason for horizontal split is that some businesses with large amounts of data have reached the bottleneck of a single database. ,At this time, you can split the table into multiple databases.

With the development of business, there are more and more businesses, and the pressure on applications is increasing. The scale of the project is also getting larger and larger. At this time, you can consider splitting the application and splitting our users, products, and transactions into subsystems according to the domain model.
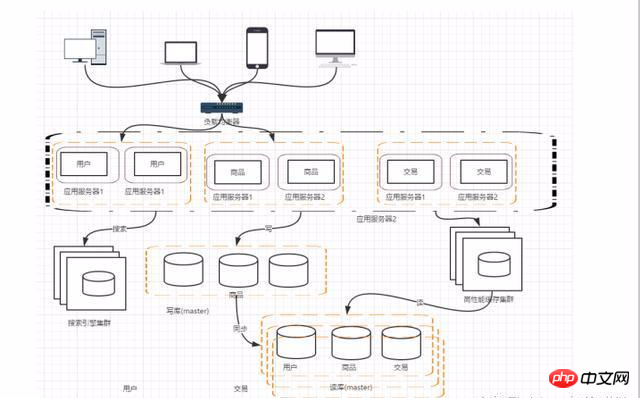
After such splitting, there may be some identical codes, such as user operations and product transaction queries, all of which will cause each system to have user queries and access related operation. These same codes and modules must be abstracted. This facilitates maintenance and management.
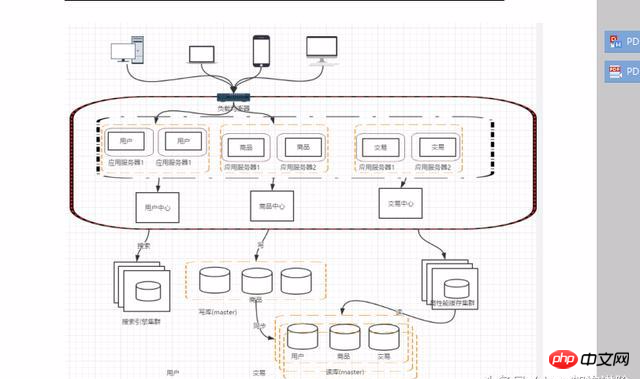
After the service is split, communication between services can be through RPC technology, the more typical ones are: webservice, hession, http, RMI, etc.
The above is the detailed content of A brief discussion on the evolution process of Java application distributed architecture. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



