


The following editor will bring you an article on the basic usage of Python character encoding and functions. The editor thinks it’s pretty good, so I’ll share it with you now and give it as a reference. Let’s follow the editor and take a look.
1. Decoding and encoding problems with characters in Python2
If you are currently using Python2 Everyone should know that there are character encoding problems. Let’s take the simplest example: Python2 cannot print Chinese directly on the command line. Of course, it will not report an error. At most, it will be a bunch of garbled characters that you cannot understand. If we want to display Chinese directly, we can declare the character encoding format in the header of the Python2 file. As shown below
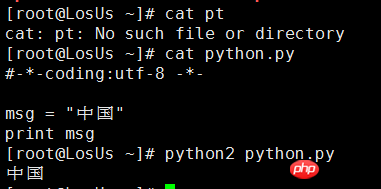
Here#-*-coding:utf-8 -*- is used to declare what encoding the following code is used to interpret;
1.1. Decoding and encoding in Python2:
In the world of encoding and decoding, we need to find a text that everyone knows. It can also be understood this way. I am a Chinese and now I am communicating with a Japanese. I definitely cannot understand what he is saying, and he cannot understand either, but is there no other way? Maybe we need an international language - English. This way people from different countries can communicate (although I know are you ok 0-0). The same is true in encoding. Neither gbk nor utf-8 knows what the other party's format means. So if you want to use gbk to understand the encoding of utf-8, you have to decode utf-8 into Unicode, and Unicode knows gkb. Here you need to encode Unicode into gbk.
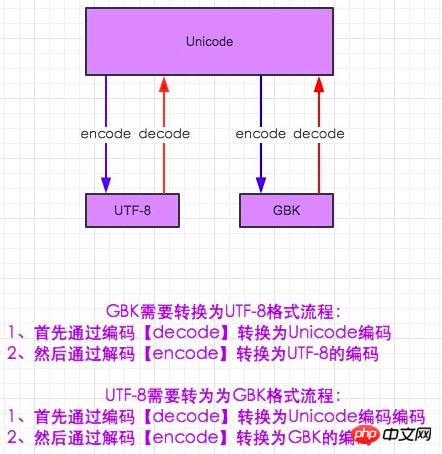
#-*- coding:utf-8 -*- msg = "中国" print msg #解码在编码的过程,encoding是申明用申明这段代码是什么编码 gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk') print gbk_str #其实两种输出的结果是一样的
In Python2, gbk is used by default to interpret the code in the IDE, so it is impossible to directly enter Chinese on the Python command line, so we use #-*-coding :utf-8 -*- to declare the header, what language do we need to use to explain the following code. Careful people must have discovered a problem. The statement header only uses utf-8 to explain the following words. It stands to reason that although no error is reported in the command line, it should be garbled. Why is Chinese output directly here? After all, the DOS command The default support in the line is the character code in gbk format? Another concept is involved here. When Python enters the memory interpreter, Unicode is used by default. After the file is loaded into the memory, it is automatically decoded into Unicode. Since Unicode is a foreign code, it can naturally be translated from utf-8 encoding or into gbk encoding. Gu can now display Chinese.
PS: Here we come to a conclusion: The decoding action is necessary in python2, but the encoding is not necessary because the memory is Unicode
1.2, Python3 The problem with character encoding:
Well, what else can be said about this? Python3 uses utf-8 to interpret code by default. That is, the beginning of the line comes with #-*-coding:utf-8 -*- (GBM), so there is no decoding problem. But I will mention it here (in fact, I am afraid that I will forget it in the future, hehe), if we encode the utf-8 character encoding format into gbk. Things in bytes format will be output here.
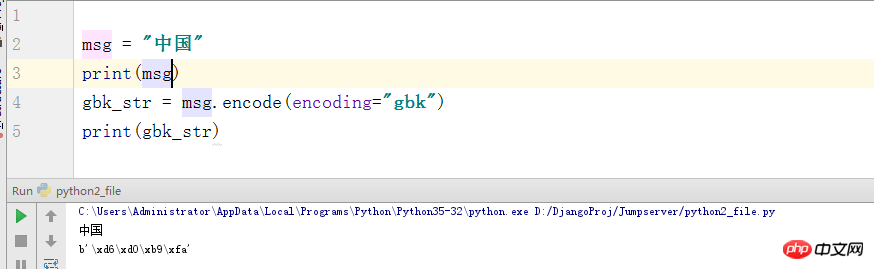
#What exactly are bytes? Let me talk about it briefly here. In fact, it is the corresponding position of this character in the ASCII code. If you don’t believe it, let’s take a look at a screenshot of the code:
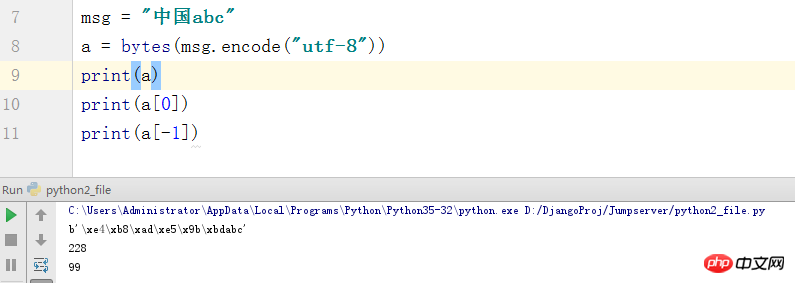
In this picture we see that China has been spread into a bunch of incomprehensible bird writing. But English is still displayed. But through the interception of the list, we can see that the output of the last c is 99. In fact, the output here is the position corresponding to c in ASCII, and 3 bytes is a Chinese character, so we see 6 paragraphs of bird text. Here we No need to explain too much.
PS: One thing everyone has to remember is: Str in Python2 is the bytes format in Python3, and str in Python2 is actually Unicode
2. Python3 supplements file operations
2.1. File operations with "+":
I will talk about three here , but in fact these things are of little use, but this is just a knowledge point
r+: Readable, you can append
w+: Clear the source file, and then write new content
a+: To append, you can read
f = open('lyrics','r+',encoding='utf-8') #这里的lyrics是文件名字
f.read() #我先读取
f.write("Leon Have Dream") #在后面追加
f.close()r+: If you f.read() first and then f.write(), it will append at the end of the file. If you f.write( directly ) directly replaces the content at the beginning of the file with the content in ();
f = open('lyricsback','w+',encoding='utf-8')
f.read()
f.write("Leon Have Dream")
f.read()
f.close()w+: In fact, it means clearing the content and rewriting the content in write(), and f.read() will not report an error. I personally recommend that you perform this operation when you are about to leave your job
f = open('lyricsback','a+',encoding='utf-8')
f.read()
f.write("Leon Have A Draem")
f.read()
f.close()a+: In fact, it is very similar to r+ at the end. Append content in, readable content
PS:这里的补充一下,为什么在使用r+的时候先执行f.read()再执行f.write()就会在文件的结尾追加和直接使用f.write()直接就替换文件最前边的内容呢?这是因为Python在读文件的时候自己维护这一个“指针”,如果我们使用f.read()就相当于读完了这个文件,这时候指针也就会在最后面了。下面我在补充“f”这个对象的几个用法来证明Python文件指针。
f = open('lyricsback','r+' ,encoding='utf-8')
print(f.tell()) #this number is 0
f.seek(12) # 将指针向后面移动几个字节,一个汉字是三个字节
print(f.tell()) # this is seek number
f.write("Love Girl") #这里就从seek到地方替换
print(f.tell()) # tell()用法就是文件的指针位置
f.close()2.2、加b的方式对文件进行操作
rb:将文件以二进制的方式从硬盘中读取出来,这里得记住在open()函数中不要加encoding= 这个参数因为二进制不存在编码上的问题
wb:将文件以二进制的方式写入内容,不过在f.write()中加上encode="utf-8",意思就是申明编码的格式,并且会清楚原来文件内容
ab:只能以二进制方式追加。
三、函数
什么是函数?函数可以简单理解一段命令的集合。为什么需要用函数?这里有一个非常简单的原因,比如说你需要对一段代码反复进行操作,这里你当然可以一直复制再粘贴,但是这样灵活性和日后的维护成本将会变大。
#比方说现在需要写一个报警(调用接口)的程序,这里就用监控做比喻 if cpu > 80%: 连接邮箱服务器 发送消息 关闭连接 if memery > 80%: 连接邮箱服务器 发送消息 关闭连接 if disk > 80% 连接邮箱服务器 发送消息 关闭连接 #通过写这样的一个程序我们发现我们一直在重复调用发送邮箱的这一套接口。这样我们是否能想出一个办法解决这样的重复操作呢?请看下一个版本 发送邮件(): l连接邮箱服务器 发送连接 关闭连接 if cpu > 80% 发送邮件() if memery > 80%: 发送邮件() ....... # 这样以此类推,我们只需要挑用发送邮件的这个接口就可以节省代码的发送邮件了
通过上面的代码我们发现,我们只需要将报警的这一套流程放到一个公共的地方,等下面触发报警的条件的时候调用报警的函数,这样我们就可以省去当每次触发报警的时候我们自己在写报警的步骤了。但是函数是怎么定义呢?又有什么语法和定义呢?请看下面的一段代码,其中代码输出的是“Leon Have A Dream”
def leon(): #leon是函数名字
print("Leon Have A Dream")
leon() #调用函数带参数的函数:
a = 10 b = 5 def calc(a,b): print(a ** b) c = calc(a,b) print(c)
首先上面这些代码执行完会输出两个字符,一个是10000,一个是None,为什么会这样呢?首先c是等于执行了一遍calc这个函数,所以输出10000这个数字是肯定的,但是为什么还会输出一个None呢?原来我们的“c”执行了仪表calc函数,而calc函数中没有任何的返回值,所以c == None 。
PS:函数的返回结果就是return,其中return的含义就是:把函数的执行结果返回给外面,从而让挑用函数的“对象”得到执行结果
下面我们在看与之相似的列子
a = 10 b = 5 def calc(a,b): print(a ** b) return a + b c = calc(a,b) c = calc(10,6) print(c)
首先会输出的有三个值,分别是100000,1000000,16,为什么会是这三个呢,下面用一副图来说一下

PS:
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
Python中的全局变量和局部变量

PS:函数内部是可以修改列表,字典,集合,实例(class),我们通过下面一个图来说明
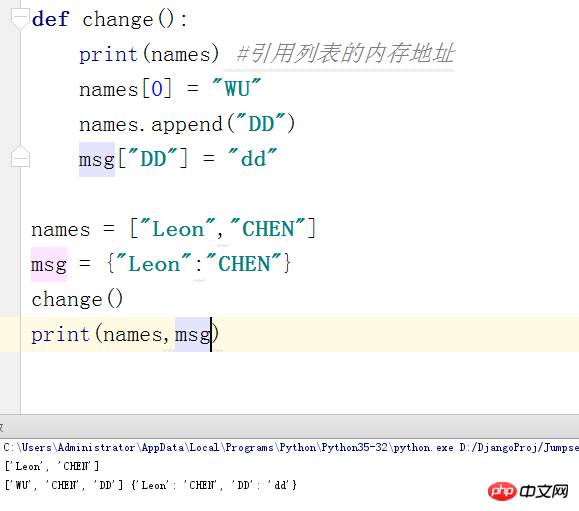
为什么列表和字典等会被添加和修改呢,原来函数内部知识引用了字典和列表的内存地址,而内存地址无法修改(可以重新开辟一块内存地址),而每个字典和列表中的每一个值都有对应的内存地址,但是记住我们函数是引用的列表或者字典本身的内存地址,所以这样打印到出来的也就会跟着改变了。
全局与局部变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
位置参数:
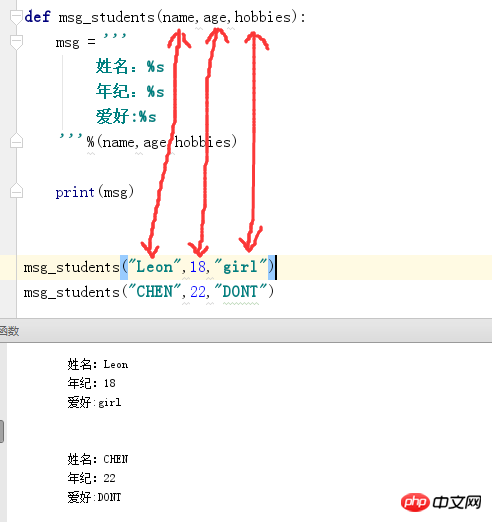
像上面这样实参和形参一一对应的上就是就是位置参数
默认参数:
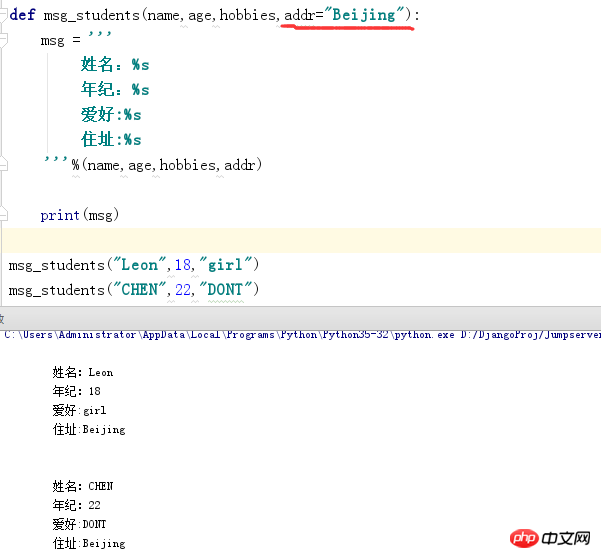
在函数将一个位置参数设置成一个默认的值的那一个变量就是默认参数,记住默认参数得在位置参数得后面
关键参数:
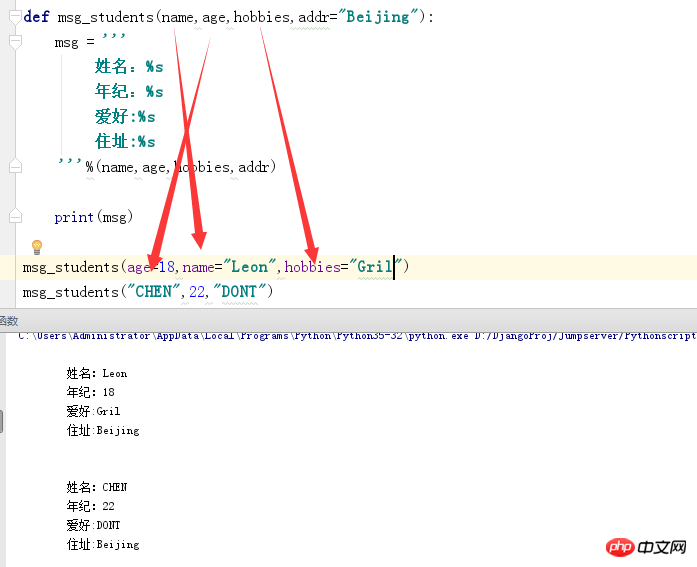
像上面这样实参和形参不一一对应,并且在调用函数的时候给参数赋值的叫做关键参数
非固定函数:
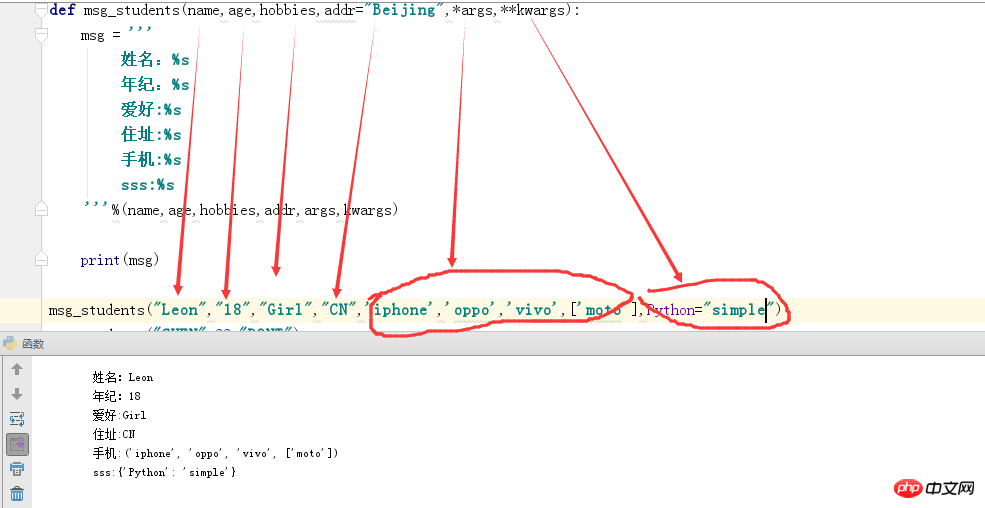
通过输出结果我们发现*args是接收多余的字符串类型的参数,而想Python="simple"(字典)类型的会传入给**kwargs,这就是非固定参数;当你不知道这个参数需要多少个参数时可以使用该函数类型
递归函数——二分查找
a = [1,2,3,4,5,7,9,10,11,12,14,15,16,17,19,21]
def calc(num,find_num):
print(num)
mid = int(len(num) / 2)
if mid == 0:
if num[mid] == find_num:
print("find it %s"%find_num)
else:
print("cannt find num")
if num[mid] == find_num:
print("find_num %s"%find_num)
elif num[mid] > find_num:
calc(num[0:mid],find_num)
elif num[mid] < find_num:
calc(num[mid+1:],find_num)
calc(a,12)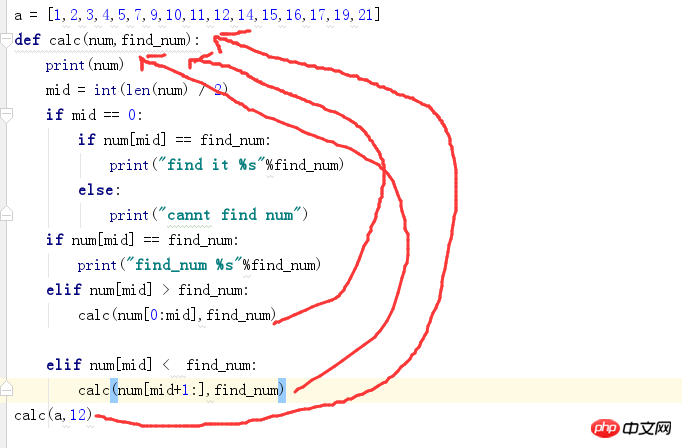
递归的特性
函数必须有明确的结束(判断)条件,也就是上图一开始的mid[0] 不能等于0,因为这样就会没有意义了
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归函数每次向下递归一次,上次的函数占用的内存地址不会被释放,而是一直会被阻塞主,等待函数全部执行完毕后释放,所以也可以说递归是相当消耗内存空间的,对此Python有递归的深度,如果超过该深度函数将会被推出(栈溢出)
匿名函数:
calc = lambda x:x+2 # x是形参,冒号后的内容是该匿名函数执行的动作 print(calc(5)) #匿名函数意识需要通过调用来执行的 calc = lambda x,y,z:x*y*z #匿名函数可以传入多个形参,各个参数之间用逗号隔开 print(calc(2,4,6)) c = map(lambda x:x*2,[2,5,4,6]) #map方法需要 传入两个参数一个是function(函数),itrables(可迭代)的数据类型 for i in c: print(i) #三元运算 for i in map(lambda x:x**2 if x >5 else x - 1,[1,2,3,5,7,8,9]): #lambda最多支持三元运算,map是直接调用匿名函数,但是如果想打印map的内容,需要循环 print(i)
高阶函数:
def calc(x,y,f): print(f(x) + f(y)) calc(10,-10,abs)
高阶函数的特性
把一个函数的内存地址传给另外一个函数,当做参数
一个函数把另外一个函数的当做返回值返回
满足上面的这个两个特性中的一个就可以称为高阶函数,这里因为偷懒,就是直接调用了Python中的内置函数
The above is the detailed content of Detailed explanation on the use of character encoding and functions in Python. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



