


This article mainly introduces the multi-page crawler based on nodejs. The editor thinks it is quite good. Now I will share it with you and give it as a reference. Let’s follow the editor to take a look.
Preface
I reviewed the front-end time againnode.js, so I took advantage of the situation and made a crawler. Deepen your understanding of node.
The three modules mainly used are request, cheerio, and async
request
is used to request addresses and fast DownloadPictureStream.
cheerio
A fast, flexible and implemented core implementation ofjQueryspecially customized for the server.
Easy to parse html code.
async
Asynchronous call to prevent blocking.
Core idea
Use request to send a request. Get the html code and get theimg tagand a tag.
Make arecursivecall through the obtained a expression. Continuously obtain the img address and a address, and continue to recurse
Get the img address through request(photo).pipe(fs.createWriteStream(dir + “/” + filename)); for fast downloading .
function requestall(url) { request({ uri: url, headers: setting.header }, function (error, response, body) { if (error) { console.log(error); } else { console.log(response.statusCode); if (!error && response.statusCode == 200) { var $ = cheerio.load(body); var photos = []; $('img').each(function () { // 判断地址是否存在 if ($(this).attr('src')) { var src = $(this).attr('src'); var end = src.substr(-4, 4).toLowerCase(); if (end == '.jpg' || end == '.png' || end == '.jpeg') { if (IsURL(src)) { photos.push(src); } } } }); downloadImg(photos, dir, setting.download_v); // 递归爬虫 $('a').each(function () { var murl = $(this).attr('href'); if (IsURL(murl)) { setTimeout(function () { fetchre(murl); }, timeout); timeout += setting.ajax_timeout; } else { setTimeout(function () { fetchre("http://www.ivsky.com/" + murl); }, timeout); timeout += setting.ajax_timeout; } }) } } }); }
Anti-pit
1. When the request is downloaded through the image address, bind the erroreventto prevent crawler exceptions of interruption.
2. Limit concurrency through async’smapLimit.
3. Add request header to prevent IP from being blocked.
4. Obtain some pictures andhyperlinkaddresses, which may be relative paths (to be considered whether there is a solution).
function downloadImg(photos, dir, asyncNum) { console.log("即将异步并发下载图片,当前并发数为:" + asyncNum); async.mapLimit(photos, asyncNum, function (photo, callback) { var filename = (new Date().getTime()) + photo.substr(-4, 4); if (filename) { console.log('正在下载' + photo); // 默认 // fs.createWriteStream(dir + "/" + filename) // 防止pipe错误 request(photo) .on('error', function (err) { console.log(err); }) .pipe(fs.createWriteStream(dir + "/" + filename)); console.log('下载完成'); callback(null, filename); } }, function (err, result) { if (err) { console.log(err); } else { console.log(" all right ! "); console.log(result); } }) }
Test:
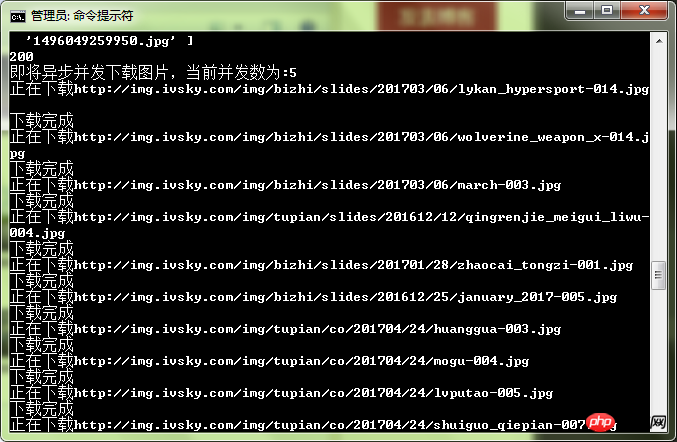
You can feel that the speed is relatively fast.
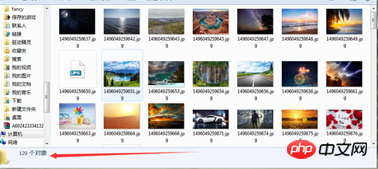
The above is the detailed content of Sample code analysis of multi-page crawler in nodejs. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



