


Effect page:
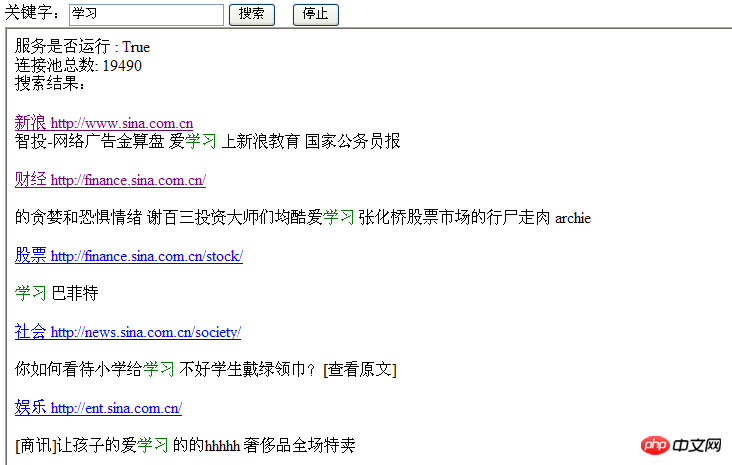
General idea:
An entrance link, for example: www.sina.com.cn, Start crawling from it and find the link (here you can parse the content of the web page, enter a keyword, judge whether the entered keyword is included, and put the link and related content of the web page into the cache), and put the crawled The connection is put into cache and executed recursively.
The work is relatively simple, so I can summarize it myself.
Start 10 threads at the same time, each thread corresponds to its own connection pool cache, put all connections containing keywords into the same cache, prepare a service page, refresh regularly, and display the current results (only It is a simulation. A real search engine must first use the word segmentation method to analyze keywords, and then combine the content of the web page to save the qualified web pages and links into the file. The next time you search, you must find the results from the file. Their The crawler crawls 24 hours a day). Let’s take a look at the specific implementation.
Entity class:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Threading;
namespace SpiderDemo.Entity
{
////爬虫线程
publicclass ClamThread
{
public Thread _thread { get; set; }
public List<Link> lnkPool { get; set; }
}
////爬到的连接
publicclass Link
{
public string Href { get; set; }
public string LinkName { get; set; }
public string Context { get; set; }
public int TheadId { get; set; }
}
}Cache class:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using SpiderDemo.Entity;
using System.Threading;
namespace SpiderDemo.SearchUtil
{
public static class CacheHelper
{
public static bool EnableSearch;
/// <summary>
/// 起始URL
/// </summary>
public const string StartUrl = "http://www.sina.com.cn";
/// <summary>
/// 爬取的最大数量,性能优化一下,如果可以及时释放资源就可以一直爬了
/// </summary>
public const int MaxNum = 300;
/// <summary>
/// 最多爬出1000个结果
/// </summary>
public const int MaxResult = 1000;
/// <summary>
/// 当前爬到的数量
/// </summary>
public static int SpideNum;
/// <summary>
/// 关键字
/// </summary>
public static string KeyWord;
/// <summary>
/// 运行时间
/// </summary>
public static int RuningTime;
/// <summary>
/// 最多运行时间
/// </summary>
public static int MaxRuningtime;
/// <summary>
/// 10个线程同时去爬
/// </summary>
public static ClamThread[] ThreadList = new ClamThread[10];
/// <summary>
/// 第一次爬到的连接,连接池
/// </summary>
public static List<Link> LnkPool = new List<Link>();
/// <summary>
/// 拿到的合法连接
/// </summary>
public static List<Link> validLnk = new List<Link>();
/// <summary>
/// 拿连接的时候 不要拿同样的
/// </summary>
public static readonly object syncObj = new object();
}
}HTTP request class:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Text;
using System.Net;
using System.IO;
using System.Threading;
namespace SpiderDemo.SearchUtil
{
public static class HttpPostUtility
{
/// <summary>
/// 暂时写成同步的吧,等后期再优化
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
public static Stream SendReq(string url)
{
try
{
if (string.IsNullOrEmpty(url)){
return null;
}
// WebProxy wp = newWebProxy("10.0.1.33:8080");
//wp.Credentials = new System.Net.NetworkCredential("*****","******", "feinno");///之前需要使用代理才能
HttpWebRequest myRequest =(HttpWebRequest)WebRequest.Create(url);
//myRequest.Proxy = wp;
HttpWebResponse myResponse =(HttpWebResponse)myRequest.GetResponse();
returnmyResponse.GetResponseStream();
}
////给一些网站发请求权限会受到限制
catch (Exception ex)
{
return null;
}
}
}
}Parsing web page class, a component is used here, HtmlAgilityPack.dll, very easy to use, download link: //m.sbmmt.com/
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Threading;
using System.Text;
using System.Xml;
using System.Xml.Linq;
using HtmlAgilityPack;
using System.IO;
using SpiderDemo.Entity;
namespace SpiderDemo.SearchUtil
{
public static class UrlAnalysisProcessor
{
public static void GetHrefs(Link url, Stream s, List<Link>lnkPool)
{
try
{
////没有HTML流,直接返回
if (s == null)
{
return;
}
////解析出连接往缓存里面放,等着前面页面来拿,目前每个线程最多缓存300个,多了就别存了,那边取的太慢了!
if (lnkPool.Count >=CacheHelper.MaxNum)
{
return;
}
////加载HTML,找到了HtmlAgilityPack,试试这个组件怎么样
HtmlAgilityPack.HtmlDocumentdoc = new HtmlDocument();
////指定了UTF8编码,理论上不会出现中文乱码了
doc.Load(s, Encoding.Default);
/////获得所有连接
IEnumerable<HtmlNode> nodeList=
doc.DocumentNode.SelectNodes("//a[@href]");////抓连接的方法,详细去看stackoverflow里面的:
//////m.sbmmt.com/
////移除脚本
foreach (var script indoc.DocumentNode.Descendants("script").ToArray())
script.Remove();
////移除样式
foreach (var style indoc.DocumentNode.Descendants("style").ToArray())
style.Remove();
string allText =doc.DocumentNode.InnerText;
int index = 0;
////如果包含关键字,为符合条件的连接
if ((index =allText.IndexOf(CacheHelper.KeyWord)) != -1)
{
////把包含关键字的上下文取出来,取40个字符吧
if (index > 20&& index < allText.Length - 20 - CacheHelper.KeyWord.Length)
{
string keyText =allText.Substring(index - 20, index) +
"<spanstyle='color:green'>" + allText.Substring(index,CacheHelper.KeyWord.Length) + "</span> " +
allText.Substring(index +CacheHelper.KeyWord.Length, 20) + "<br />";////关键字突出显示
url.Context = keyText;
}
CacheHelper.validLnk.Add(url);
//RecordUtility.AppendLog(url.LinkName + "<br />");
////爬到了一个符合条件的连接,计数器+1
CacheHelper.SpideNum++;
}
foreach (HtmlNode node innodeList)
{
if(node.Attributes["href"] == null)
{
continue;
}
else
{
Link lk = new Link()
{
Href =node.Attributes["href"].Value,
LinkName ="<a href='" + node.Attributes["href"].Value +
"'target='blank' >" + node.InnerText + " " +
node.Attributes["href"].Value + "</a>" +"<br />"
};
if(lk.Href.StartsWith("javascript"))
{
continue;
}
else if(lk.Href.StartsWith("#"))
{
continue;
}
else if(lnkPool.Contains(lk))
{
continue;
}
else
{
////添加到指定的连接池里面
lnkPool.Add(lk);
}
}
}
}
catch (Exception ex)
{
}
}
}
}Search page CODE BEHIND:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
using SpiderDemo.SearchUtil;
using System.Threading;
using System.IO;
using SpiderDemo.Entity;
namespace SpiderDemo
{
public partial class SearchPage : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
InitSetting();
}
}
private void InitSetting()
{
}
private void StartWork()
{
CacheHelper.EnableSearch = true;
CacheHelper.KeyWord = txtKeyword.Text;
////第一个请求给新浪,获得返回的HTML流
Stream htmlStream = HttpPostUtility.SendReq(CacheHelper.StartUrl);
Link startLnk = new Link()
{
Href = CacheHelper.StartUrl,
LinkName = "<a href ='" + CacheHelper.StartUrl + "' > 新浪 " +CacheHelper.StartUrl + " </a>"
};
////解析出连接
UrlAnalysisProcessor.GetHrefs(startLnk, htmlStream,CacheHelper.LnkPool);
for (int i = 0; i < CacheHelper.ThreadList.Length; i++)
{
CacheHelper.ThreadList[i] = newClamThread();
CacheHelper.ThreadList[i].lnkPool = new List<Link>();
}
////把连接平分给每个线程
for (int i = 0; i < CacheHelper.LnkPool.Count; i++)
{
int tIndex = i %CacheHelper.ThreadList.Length;
CacheHelper.ThreadList[tIndex].lnkPool.Add(CacheHelper.LnkPool[i]);
}
Action<ClamThread> clamIt = new Action<ClamThread>((clt)=>
{
Stream s =HttpPostUtility.SendReq(clt.lnkPool[0].Href);
DoIt(clt, s, clt.lnkPool[0]);
});
for (int i = 0; i < CacheHelper.ThreadList.Length; i++)
{
CacheHelper.ThreadList[i]._thread = new Thread(new ThreadStart(() =>
{
clamIt(CacheHelper.ThreadList[i]);
}));
/////每个线程开始工作的时候,休眠100ms
CacheHelper.ThreadList[i]._thread.Start();
Thread.Sleep(100);
}
}
private void DoIt(ClamThreadthread, Stream htmlStream, Link url)
{
if (!CacheHelper.EnableSearch)
{
return;
}
if (CacheHelper.SpideNum > CacheHelper.MaxResult)
{
return;
}
////解析页面,URL符合条件放入缓存,并把页面的连接抓出来放入缓存
UrlAnalysisProcessor.GetHrefs(url, htmlStream, thread.lnkPool);
////如果有连接,拿第一个发请求,没有就结束吧,反正这么耗资源的东西
if (thread.lnkPool.Count > 0)
{
Link firstLnk;
firstLnk = thread.lnkPool[0];
////拿到连接之后就在缓存中移除
thread.lnkPool.Remove(firstLnk);
firstLnk.TheadId =Thread.CurrentThread.ManagedThreadId;
Stream content =HttpPostUtility.SendReq(firstLnk.Href);
DoIt(thread, content,firstLnk);
}
else
{
//没连接了,停止吧,看其他线程的表现
thread._thread.Abort();
}
}
protected void btnSearch_Click(object sender, EventArgs e)
{
this.StartWork();
}
protected void btnShow_Click(object sender, EventArgs e)
{
}
protected void btnStop_Click(object sender, EventArgs e)
{
foreach (var t in CacheHelper.ThreadList)
{
t._thread.Abort();
t._thread.DisableComObjectEagerCleanup();
}
CacheHelper.EnableSearch =false;
//CacheHelper.ValidLnk.Clear();
CacheHelper.LnkPool.Clear();
CacheHelper.validLnk.Clear();
}
}
}Search page front-end code:
<%@ Page Language="C#"AutoEventWireup="true" CodeBehind="SearchPage.aspx.cs"Inherits="SpiderDemo.SearchPage" %>
<!DOCTYPE html PUBLIC "-//W3C//DTDXHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<htmlxmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title></title>
</head>
<body>
<form id="form1" runat="server">
<p>
关键字:<asp:TextBoxrunat="server" ID="txtKeyword" ></asp:TextBox>
<asp:Button runat="server" ID="btnSearch"Text="搜索" onclick="btnSearch_Click"/>
<asp:Button runat="server" ID="btnStop"Text="停止" onclick="btnStop_Click" />
</p>
<p>
<iframe width="800px" height="700px"src="ShowPage.aspx">
</iframe>
</p>
</form>
</body>
</html>
ShowPage.aspx(嵌在SearchPage里面,ajax请求一个handler):
<%@ Page Language="C#"AutoEventWireup="true" CodeBehind="ShowPage.aspx.cs"Inherits="SpiderDemo.ShowPage" %>
<!DOCTYPE html PUBLIC "-//W3C//DTDXHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title></title>
<script src="js/jquery-1.6.js"></script>
</head>
<body>
<form id="form1" runat="server">
<p>
</p>
<p id="pRet">
</p>
<script type="text/javascript">
$(document).ready(
function () {
var timer = setInterval(
function () {
$.ajax({
type: "POST",
url:"http://localhost:26820/StateServicePage.ashx",
data: "op=info",
success: function (msg) {
$("#pRet").html(msg);
}
});
}, 2000);
});
</script>
</form>
</body>
</html>StateServicePage.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Text;
using SpiderDemo.SearchUtil;
using SpiderDemo.Entity;
namespace SpiderDemo
{
/// <summary>
/// StateServicePage 的摘要说明
/// </summary>
public class StateServicePage : IHttpHandler
{
public void ProcessRequest(HttpContext context)
{
context.Response.ContentType = "text/plain";
if (context.Request["op"] != null &&context.Request["op"] == "info")
{
context.Response.Write(ShowState());
}
}
public string ShowState()
{
StringBuilder sbRet = new StringBuilder(100);
string ret = GetValidLnkStr();
int count = 0;
for (int i = 0; i <CacheHelper.ThreadList.Length; i++)
{
if(CacheHelper.ThreadList[i] != null && CacheHelper.ThreadList[i].lnkPool!= null)
count += CacheHelper.ThreadList[i].lnkPool.Count;
}
sbRet.AppendLine("服务是否运行 : " + CacheHelper.EnableSearch + "<br />");
sbRet.AppendLine("连接池总数: " + count + "<br />");
sbRet.AppendLine("搜索结果:<br /> " + ret);
return sbRet.ToString();
}
private string GetValidLnkStr()
{
StringBuilder sb = new StringBuilder(120);
Link[] cloneLnk = new Link[CacheHelper.validLnk.Count];
CacheHelper.validLnk.CopyTo(cloneLnk, 0);
for (int i = 0; i < cloneLnk.Length; i++)
{
sb.AppendLine("<br/>" + cloneLnk[i].LinkName + "<br />" +cloneLnk[i].Context);
}
return sb.ToString();
}
public bool IsReusable
{
get
{
return false;
}
}
}
} The above is the code details of C# web crawler and search engine research. For more related content, please pay attention to the PHP Chinese website (m.sbmmt.com)!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



