


Comprehensive Guide on Reranker for RAG

Retrieval Augmented Generation (RAG) systems are transforming information access, but their effectiveness hinges on the quality of retrieved data. This is where rerankers become crucial – acting as a quality filter for search results to ensure only the most relevant information contributes to the final output.
This article delves into the world of rerankers, examining their importance, application scenarios, potential limitations, and various types. We'll also guide you through selecting the best reranker for your RAG system and evaluating its performance.
Table of Contents:
- What is a Reranker in RAG?
- Why Use a Reranker in RAG?
- Types of Rerankers
- Selecting the Optimal Reranker
- Recent Research
- Conclusion
What is a Reranker in RAG?
A reranker is a vital component of information retrieval systems, functioning as a secondary filter. Following an initial search (using techniques like semantic or keyword search), it receives a set of documents and reorders them based on relevance to a specific query. This process refines the search results, prioritizing the most pertinent information. Rerankers achieve this balance between speed and accuracy by employing more sophisticated matching methods than the initial retrieval phase.
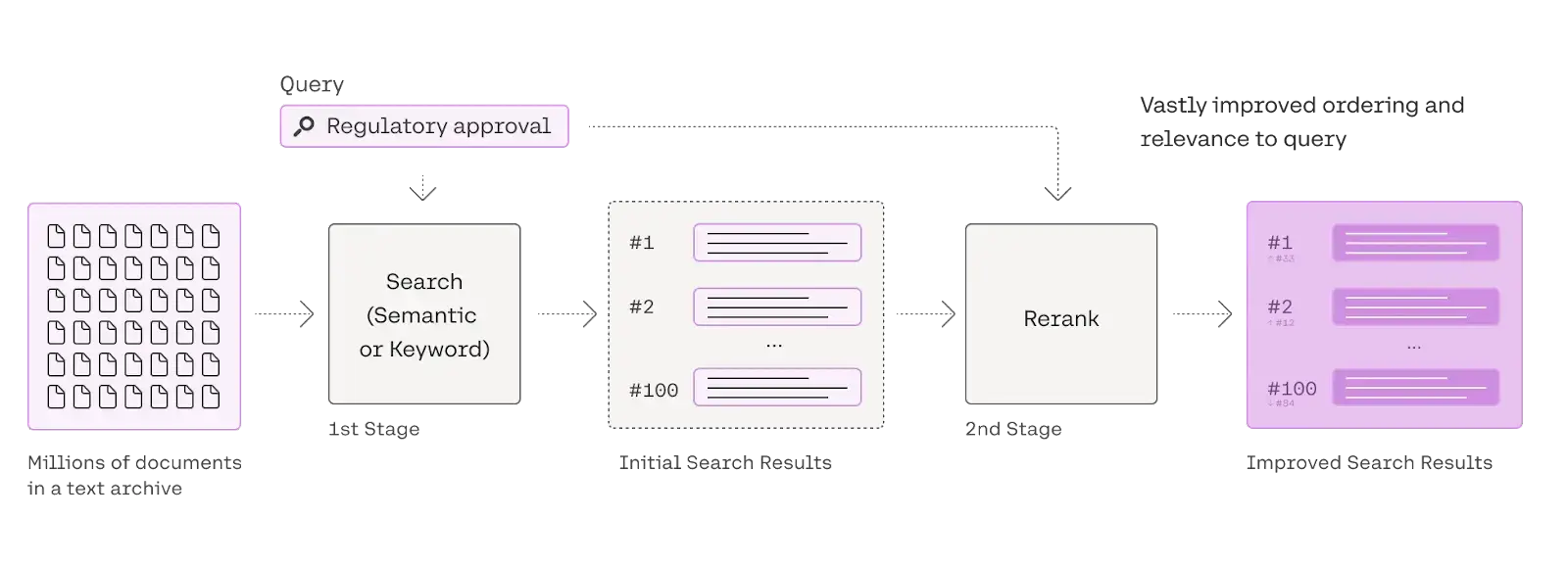
This diagram illustrates a two-step search process. Reranking, the second step, refines the initial search results (based on semantic or keyword matching) to significantly enhance the relevance and order of the final results, providing a more precise and useful response to the user's query.
Why Use a Reranker in RAG?
Consider your RAG system as a chef, and the retrieved documents as ingredients. A delicious dish (accurate answer) requires the best ingredients. However, irrelevant or inappropriate ingredients can ruin the dish. Rerankers prevent this!
Here's why you need a reranker:
- Reduced Hallucinations: Rerankers filter out irrelevant documents that can lead to inaccurate or nonsensical LLM outputs (hallucinations).
- Cost Optimization: By focusing on the most relevant documents, you minimize the LLM's processing load, saving on API calls and computing resources.
Understanding Embedding Limitations:
Relying solely on embeddings for retrieval has limitations:
- Limited Semantic Nuance: Embeddings sometimes miss subtle contextual differences.
- Dimensionality Issues: Representing complex information in low-dimensional embedding space can lead to information loss.
- Generalization Challenges: Embeddings may struggle to accurately retrieve information outside their training data.
Reranker Advantages:
Rerankers overcome these embedding limitations by:
- Bag-of-Embeddings Approach: Processing documents as smaller, contextualized units rather than single vector representations.
- Semantic Keyword Matching: Combining the power of encoder models (like BERT) with keyword-based techniques for both semantic and keyword relevance.
- Improved Generalization: Handling unseen documents and queries more effectively due to the focus on smaller, contextualized units.

This image shows a query searching a vector database, retrieving the top 25 documents. These are then passed to a reranker module, which refines the results, selecting the top 3 for the final output.
Types of Rerankers:
The field of rerankers is constantly evolving. Here are the main types:
| Approach | Examples | Access Type | Performance Level | Cost Range |
|---|---|---|---|---|
| Cross Encoder | Sentence Transformers, Flashrank | Open-source | Excellent | Moderate |
| Multi-Vector | ColBERT | Open-source | Good | Low |
| Fine-tuned LLM | RankZephyr, RankT5 | Open-source | Excellent | High |
| LLM as a Judge | GPT, Claude, Gemini | Proprietary | Top-tier | Very Expensive |
| Reranking API | Cohere, Jina | Proprietary | Excellent | Moderate |
Selecting the Optimal Reranker:
Choosing the right reranker involves considering:
- Relevance Enhancement: Measure the improvement in relevance using metrics like NDCG.
- Latency: The additional time the reranker adds to the search process.
- Contextual Understanding: The reranker's ability to handle varied context lengths.
- Generalization: The reranker's performance across different domains and datasets.
Recent Research:
Recent studies highlight the effectiveness and efficiency of cross-encoders, especially when combined with robust retrievers. Cross-encoders often outperform many LLMs in reranking, while maintaining better efficiency.
Conclusion:
Selecting the appropriate reranker is crucial for optimizing RAG systems and ensuring accurate search results. Understanding the different types of rerankers and their strengths and weaknesses is essential for building effective and efficient RAG applications. Careful selection and evaluation will lead to improved accuracy and performance.
The above is the detailed content of Comprehensive Guide on Reranker for RAG. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 Kimi K2: The Most Powerful Open-Source Agentic Model
Jul 12, 2025 am 09:16 AM
Kimi K2: The Most Powerful Open-Source Agentic Model
Jul 12, 2025 am 09:16 AM
Remember the flood of open-source Chinese models that disrupted the GenAI industry earlier this year? While DeepSeek took most of the headlines, Kimi K1.5 was one of the prominent names in the list. And the model was quite cool.
 Grok 4 vs Claude 4: Which is Better?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Which is Better?
Jul 12, 2025 am 09:37 AM
By mid-2025, the AI “arms race” is heating up, and xAI and Anthropic have both released their flagship models, Grok 4 and Claude 4. These two models are at opposite ends of the design philosophy and deployment platform, yet they
 10 Amazing Humanoid Robots Already Walking Among Us Today
Jul 16, 2025 am 11:12 AM
10 Amazing Humanoid Robots Already Walking Among Us Today
Jul 16, 2025 am 11:12 AM
But we probably won’t have to wait even 10 years to see one. In fact, what could be considered the first wave of truly useful, human-like machines is already here. Recent years have seen a number of prototypes and production models stepping out of t
 Context Engineering is the 'New' Prompt Engineering
Jul 12, 2025 am 09:33 AM
Context Engineering is the 'New' Prompt Engineering
Jul 12, 2025 am 09:33 AM
Until the previous year, prompt engineering was regarded a crucial skill for interacting with large language models (LLMs). Recently, however, LLMs have significantly advanced in their reasoning and comprehension abilities. Naturally, our expectation
 What Are The 7 Types Of AI Agents?
Jul 11, 2025 am 11:08 AM
What Are The 7 Types Of AI Agents?
Jul 11, 2025 am 11:08 AM
Picture something sophisticated, such as an AI engine ready to give detailed feedback on a new clothing collection from Milan, or automatic market analysis for a business operating worldwide, or intelligent systems managing a large vehicle fleet.The
 Concealed Command Crisis: Researchers Game AI To Get Published
Jul 13, 2025 am 11:08 AM
Concealed Command Crisis: Researchers Game AI To Get Published
Jul 13, 2025 am 11:08 AM
Scientists have uncovered a clever yet alarming method to bypass the system. July 2025 marked the discovery of an elaborate strategy where researchers inserted invisible instructions into their academic submissions — these covert directives were tail
 United Nations Considering These Four Crucial Actions To Save The World From Dire AGI And Killer AI Superintelligence
Jul 13, 2025 am 11:09 AM
United Nations Considering These Four Crucial Actions To Save The World From Dire AGI And Killer AI Superintelligence
Jul 13, 2025 am 11:09 AM
Be aware that the United Nations has had an ongoing interest in how AI is advancing and what kinds of international multilateral arrangements and collaborations ought to be taking place (see my coverage at the link here). The distinctive element of t
 Grok 4 is Here and it's Simply Brilliant! - Analytics Vidhya
Jul 12, 2025 am 09:14 AM
Grok 4 is Here and it's Simply Brilliant! - Analytics Vidhya
Jul 12, 2025 am 09:14 AM
“It’s smarter than almost all graduate students in all disciplines – Elon Musk.” Elon Musk and his Grok team are back with their latest and best model to date: Grok 4. It was only 3 months ago that this team of e
