Il semble que tout le monde ait encore des opinions différentes sur la question de savoir si RLHF et RL peuvent être classées dans la même catégorie. Le gourou de l'IA Karpathy est de nouveau là pour populariser le concept d'intelligence artificielle. Hier, il a tweeté : "L'apprentissage par renforcement basé sur le feedback humain (RLHF) n'est qu'un apprentissage par renforcement (RL)."

Le texte intégral de Karpathy est expliqué comme suit :
RLHF est la troisième méthode de formation de grands modèles de langage (LLM). Il y a trois (et dernières) étapes principales, les deux premières étapes sont la pré-formation et le réglage fin supervisé (SFT). Je pense que le RLHF est à peine un RL, il n'est pas largement reconnu. RL est puissant, mais RLHF ne l’est pas.
Regardons l'exemple d'AlphaGo, qui a été formé à l'aide d'un vrai RL. L'ordinateur jouait au jeu de Go et était entraîné sur des tours qui maximisaient la fonction de récompense (gagner la partie), surpassant finalement les meilleurs joueurs humains. AlphaGo n’a pas été formé à l’aide du RLHF, et si c’était le cas, il ne serait pas aussi efficace.
À quoi cela ressemblerait-il d'entraîner AlphaGo avec RLHF ? Tout d'abord, vous donnez aux annotateurs humains deux états du tableau Go et leur demandez lequel ils préfèrent :

Vous collecterez ensuite 100 000 comparaisons similaires et entraînerez un réseau neuronal de « modèle de récompense » (RM) pour simuler une vérification par vibration humaine de l'état de la carte. Vous l’entraînez à être d’accord avec le jugement humain moyen. Une fois que nous avons vérifié l'ambiance du modèle bonus, vous pouvez exécuter RL contre cela et apprendre à effectuer des mouvements qui apportent de bonnes vibrations. Évidemment, cela ne produit pas de résultats très intéressants en Go.
Cela s'explique principalement par deux raisons fondamentales et indépendantes :
1) L'ambiance peut être trompeuse, ce qui n'est pas la véritable récompense (gagner la partie). C’est un mauvais objectif d’agent. Pire encore, 2) vous constaterez que votre optimisation RL déraille car elle découvre rapidement que l'état du tableau est opposé au modèle de récompense. N'oubliez pas que le modèle de récompense est un réseau neuronal massif utilisant des milliards de paramètres pour simuler l'atmosphère. Certains états du conseil d'administration se situent en dehors de la plage de distribution de leurs propres données de formation et ne sont pas réellement de bons états, mais reçoivent des récompenses très élevées du modèle de récompense.
Pour la même raison, je suis parfois surpris que le travail du RLHF fonctionne pour le LLM. Le modèle de récompense que nous avons formé pour LLM effectue simplement la vérification des vibrations exactement de la même manière, en attribuant des scores élevés aux réponses de l'assistant que les évaluateurs humains semblent statistiquement apprécier. Ce n’est pas le but réel de résoudre le problème correctement, mais le but de ce que les humains pensent être bon en tant qu’agent.
Deuxièmement, vous ne pouvez même pas exécuter RLHF très longtemps car votre modèle apprend rapidement à réagir de manière à ce que le jeu le récompense. Ces prédictions auront l'air vraiment bizarres, et vous verrez votre assistant LLM commencer à répondre à de nombreuses invites avec des réponses dénuées de sens comme "Le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le le Cela vous semble ridicule, mais ensuite vous regardez les contrôles d'ambiance du modèle bonus et vous réalisez que, pour une raison quelconque, le modèle bonus les trouve superbes.
Votre LLM a trouvé un exemple contradictoire qui se situe en dehors de la plage des données de formation du modèle de récompense et se situe dans une plage indéfinie. Vous pouvez atténuer ce problème en ajoutant ces exemples spécifiques à l'ensemble de formation à plusieurs reprises, tout en trouvant d'autres exemples contradictoires la prochaine fois. Vous ne pouvez même pas exécuter RLHF pour de nombreuses étapes d'optimisation. Vous devez l'appeler après quelques centaines ou milliers d'étapes, car votre optimisation commencera à jouer sur le modèle de récompense. Ce n'est pas RL comme AlphaGo.
Cependant, le RLHF est une étape très utile dans la construction d'un assistant LLM. Je pense qu'il y a plusieurs raisons subtiles à cela, dont ma préférée est qu'avec RLHF, l'assistant LLM bénéficie de l'écart générateur-discriminateur. Autrement dit, pour de nombreux types de questions, il est beaucoup plus facile pour un annotateur humain de sélectionner la meilleure réponse parmi plusieurs réponses candidates que d'écrire la réponse idéale à partir de zéro. Un bon exemple est une invite telle que « Générer un poème avec un trombone ». Un annotateur humain moyen aurait du mal à écrire un bon poème à partir de zéro pour l'utiliser comme exemple de mise au point supervisée, mais pourrait en choisir un meilleur étant donné plusieurs réponses candidates (poèmes). Le RLHF est donc un moyen de bénéficier du manque de « facilité » de la supervision humaine.
Il existe d'autres raisons pour lesquelles le RLHF aide à soulager les hallucinations. Si le modèle de récompense est un modèle suffisamment puissant pour repérer ce que le LLM invente pendant la formation, il peut apprendre à punir ce comportement avec de faibles récompenses, en apprenant au modèle à éviter de prendre des risques pour acquérir des connaissances factuelles lorsqu'elles sont incertaines. Mais le soulagement et la gestion satisfaisante des hallucinations sont une autre affaire et ne seront pas développés ici. En conclusion, RLHF fonctionne, mais ce n'est pas RL.
Jusqu'à présent, aucun RL de qualité production pour LLM n'a été implémenté et démontré de manière convaincante à grande échelle dans le domaine ouvert. Intuitivement, cela est dû au fait qu’il est très difficile d’obtenir des récompenses réelles (c’est-à-dire gagner la partie) dans des tâches ouvertes de résolution de problèmes. Dans un environnement fermé et ludique comme Go, tout est amusant. La dynamique est limitée, le coût d'évaluation de la fonction de récompense est très faible et le jeu est impossible.
Mais comment offrir une récompense objective pour la synthèse d’un article ? Ou répondre à une question ambiguë sur une certaine installation de pip ? Ou raconter une blague ? Ou réécrire du code Java en Python ? Y parvenir n’est pas impossible en principe, mais ce n’est pas facile et nécessite une certaine réflexion créative. Celui qui résoudra ce problème de manière convaincante sera capable d'exécuter un véritable RL, permettant à AlphaGo de battre les humains au Go. Avec RL, LLM a le potentiel de véritablement battre les humains dans la résolution de problèmes de domaine ouvert.
Le point de vue de Karpathy a été repris par certains qui ont souligné davantage de différences entre RLHF et RL. Par exemple, RLHF n'effectue pas de recherche appropriée et apprend principalement à utiliser un sous-ensemble de trajectoires pré-entraînées. En revanche, lors d'une RL appropriée, les distributions d'actions discrètes sont souvent bruitées en ajoutant un terme d'entropie à la fonction de perte. Kaypathy a fait valoir qu'en principe, vous pourriez facilement ajouter des récompenses d'entropie aux objectifs du RLHF, ce qui est également souvent fait dans le RL. Mais en réalité, cela semble rare.
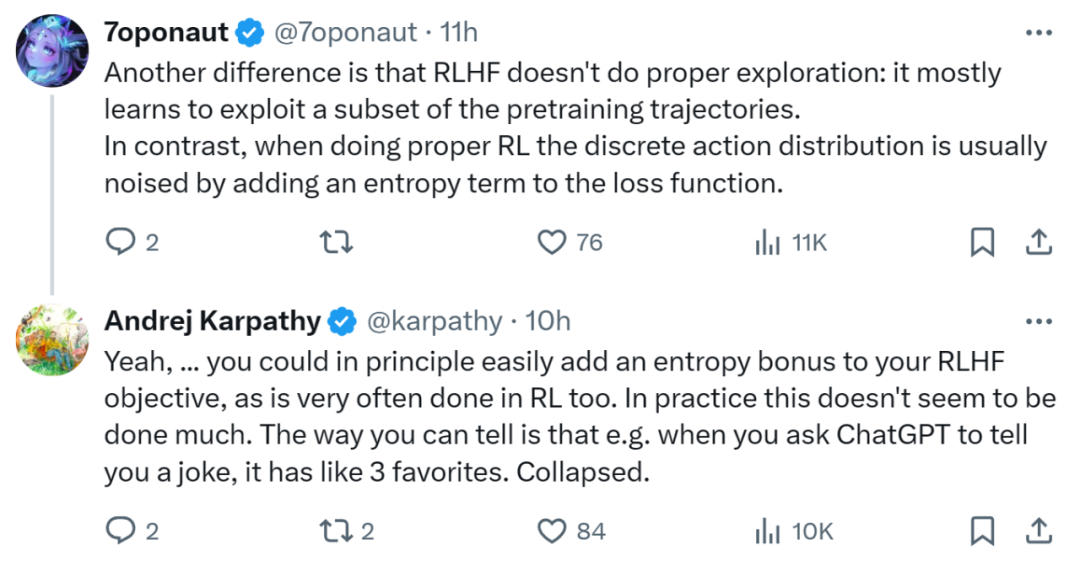
Kevin Patrick Murphy, chercheur chez Google, est également entièrement d'accord avec Karpathy.
- He believes that RLHF is more like a context "bandit" with string value operations, where prompt is the context, so it cannot be called a complete RL.
- Also formalizing the rewards for daily tasks is the hard part (he thinks it might be called alignment).
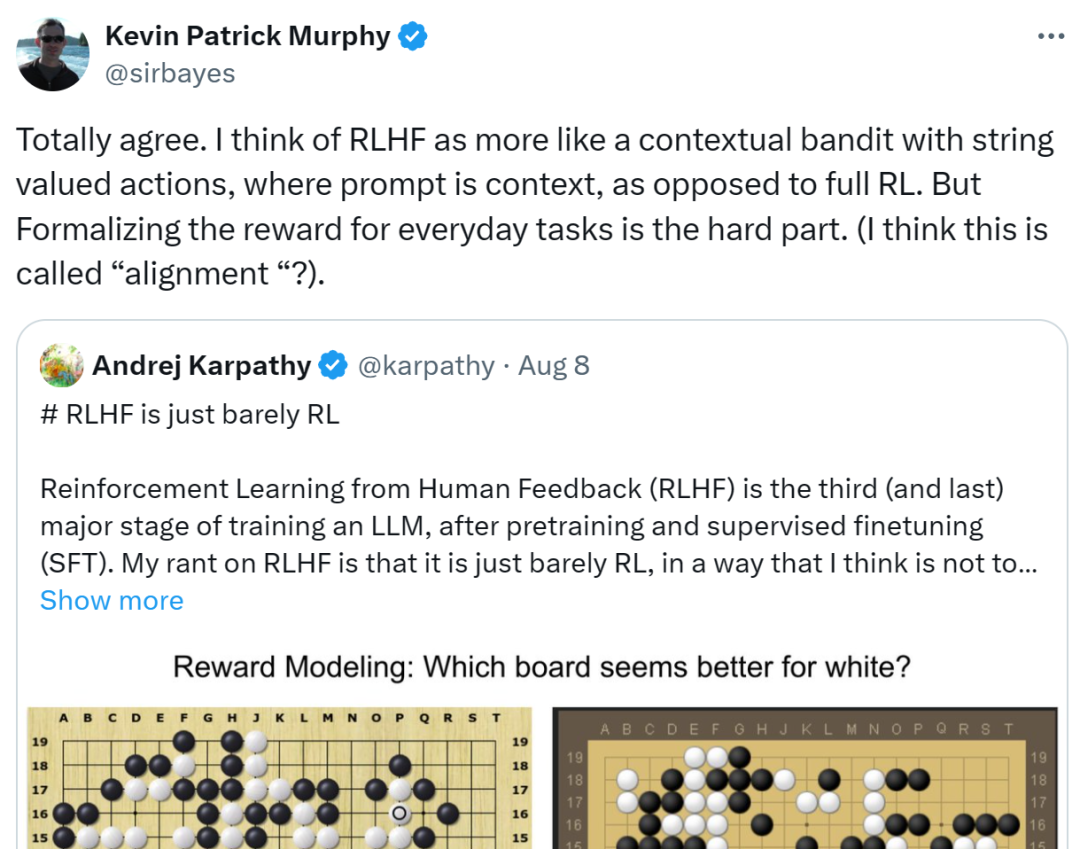
However, Natasha Jaques, another senior research scientist at Google, thinks Karpathy is wrong. She believes that whenagentinteracts with people, giving answers that humans like is the real goal.
Out-of-distribution range is not a problem unique to RLHF. Just because human feedback is more constrained than running an infinite Go simulation doesn't mean it's not a problem worth solving, it just makes it a more challenging one. She hopes this becomes a more impactful issue, after all reducing bias inLLMmakes more sense than beating humans at Go. Using derogatory terms like Karpathy saying the bonus model is a vibe check is silly. You can use the same argument against value estimates.
She feels that Karpathy's views will only serve to deter people from pursuing RLHF work, when it is currently the only viable way to mitigate the serious harm thatLLMbias and illusion can cause.
Source: https://x.com/natashajaques/status/1821631137590259979
Meta researcher Pierluca D'Oro disagrees with Karpathy's main point, but agrees that "RLHF is just barely RL" This title. He argued that RLHF, which is commonly used to fine-tune LLM, is hardly RL.
The main points are as follows:
- In reinforcement learning, it is unrealistic to pursue a "perfect reward" concept, because in most complex tasks, in addition to the importance of the goal, the execution method is equally important.
- Although in tasks with clear rules such as Go, RL performs well. But when it comes to complex behaviors, the reward mechanism of traditional RL may not be able to meet the needs.
- He advocates studying how to improve the performance of RL under imperfect reward models, and emphasizes the importance of feedback loops, robust RL mechanisms, and human-machine collaboration.

Picture source: https://x.com/proceduralia/status/1821560990091128943 Whose view do you agree with? Welcome to leave a message in the comment area.
The above is the detailed content of Karpathy's views are controversial: RLHF is not real reinforcement learning, and Google and Meta are opposed to it. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



