The AI video circle is "fighting each other".
Luma and Runway from abroad, Kuaishou Keling, Byte Dream, Zhipu Qingying from China... you just sing and I will appear. Without exception, they all target the legendary Sora.
In fact, when it comes to Sora’s global challengers, Vidu from Shengshu Technology is indispensable.
As early as three months ago, when the field of video generation at home and abroad was still "silent", Shengshu Technology suddenly exposed the promotional video of its latest large-scale video model Vidu. The effect amazed many netizens.
Just today, Vidu is officially launched. No application is required, as long as you have an email address, you can get started. (Vidu official website link: www.vidu.studio)
For example, Pikachu and Doraemon play "Cheap Kill":

The male and female protagonists of "Twilight" show their affection:

It even solves the problem of AI not being able to write:

In addition, Vidu’s generation efficiency is also amazing, achieving the fastest inference speed in the industry, and it only takes 30 seconds to generate a 4-second footage .
Next, we will provide the latest first-hand review to see how strong this "domestic Sora" is.
Hands-on test: The lens language is bold and the picture will not collapse!
This time, Vidu showed off his unique skills.
Not only continues the advantages of high dynamics, high fidelity, and high consistency demonstrated in April this year, but also adds new features such as animation style, text and special effects screen generation, and character consistency.
The main theme is: I want to have the functions that others have, and I also want to have the functions that others don’t have.
Oh no, it can actually recognize characters and numbers
At this stage, Vidu has two core functions: Wen Sheng video and Tu Sheng video.
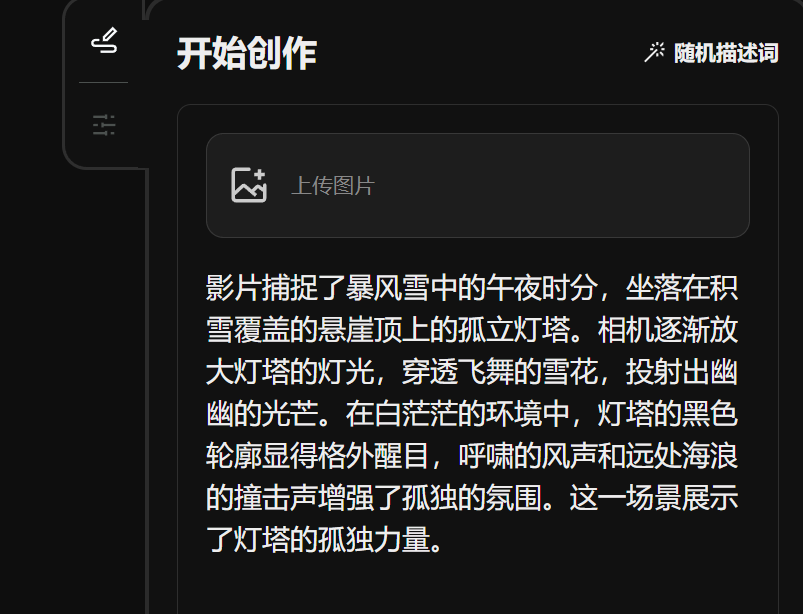
Provides two duration options of 4s and 8s, with a resolution up to 1080P. In terms of style, there are two options: realistic and animated.
Watch Tusheng’s video first.
Making history come alive again is the most popular way to play at the moment. This is the famous work "Portrait of the Painter and his Daughter" by the French painter Elisabeth Louise Verry.

We enter the prompt word: portrait of painter and daughter, mother and daughter hugging each other tightly.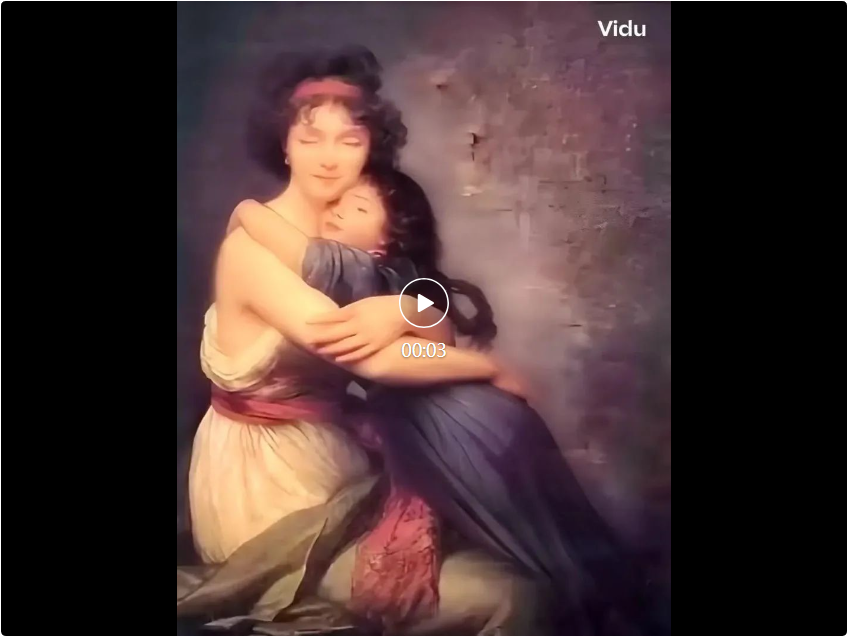
The high-definition version generated is eye-catching. The characters move widely and even their eyes change, but the effect is quite natural.
Try Leonardo da Vinci's "The Woman with the Silver Weasel" again.

Prompt word: The woman holding the silver ferret is smiling.
 In the 8-second long video, the woman and the pet move widely, especially the woman’s hand touching movements, as well as body and facial changes, but none of them affect the naturalness and smoothness of the picture.
Large and precise movements help to better express the video plot and character emotions. However, once the range of motion becomes larger, the screen is prone to collapse. Therefore, some models sacrifice amplitude to ensure smoothness, but Vidu solves this problem better.
It simulates the movement of the real physical world, which is really good. For example, recreate a scene similar to Kubrick's "2001: A Space Odyssey"!
In the 8-second long video, the woman and the pet move widely, especially the woman’s hand touching movements, as well as body and facial changes, but none of them affect the naturalness and smoothness of the picture.
Large and precise movements help to better express the video plot and character emotions. However, once the range of motion becomes larger, the screen is prone to collapse. Therefore, some models sacrifice amplitude to ensure smoothness, but Vidu solves this problem better.
It simulates the movement of the real physical world, which is really good. For example, recreate a scene similar to Kubrick's "2001: A Space Odyssey"!

 Prompt word: Under the long lens, slowly disappear.长 : reminder word: Under the long lens, floating, floating slowly at the end.
Prompt word: Under the long lens, slowly disappear.长 : reminder word: Under the long lens, floating, floating slowly at the end. In addition to Tusheng videos, there are also Vincent videos.朵 Tips: Two flowers bloom slowly in the black background, showing delicate petals and stamens.
In addition to Tusheng videos, there are also Vincent videos.朵 Tips: Two flowers bloom slowly in the black background, showing delicate petals and stamens.
Tips: This time she is alone, sitting alone on the swing deep in the cherry blossoms, wearing a pink spring shirt, swinging slightly, the amplitude is very small, like sitting on a rocking chair, with her head slightly lowered, a bit bored He slowly stretched out his feet and kicked the grass on the ground bit by bit. The cherry blossoms fell on her body and head, but she didn't brush them away with her hands. They gradually accumulated and blended with the color of her dress. From a distance, it seemed as if her whole body was made of cherry blossoms. .
Vidu has good semantic understanding and can also understand the clip requirements of multiple shots at a time in the prompt.
For example, the picture includes a close-up of a beach house and a distant view of the sea when the camera is turned to the sea. The camera switching gives the picture a distinct sense of narrative.
 Tips: In an antique seaside hut, the sun bathes the room, the camera slowly transitions to a balcony overlooking the tranquil sea, and finally the camera freezes on the floating sea, sailboats and reflective clouds .
Vidu can also accurately understand and express lens language such as first-person and time-lapse photography. Users only need to refine the prompt words to greatly improve the controllability of the video.
Tips: In an antique seaside hut, the sun bathes the room, the camera slowly transitions to a balcony overlooking the tranquil sea, and finally the camera freezes on the floating sea, sailboats and reflective clouds .
Vidu can also accurately understand and express lens language such as first-person and time-lapse photography. Users only need to refine the prompt words to greatly improve the controllability of the video.
 Vidu is a video generator that can accurately understand and generate some vocabulary, such as numbers.块 Tips: A birthday cake with a candle on it. The candle is the number "32".
Vidu is a video generator that can accurately understand and generate some vocabulary, such as numbers.块 Tips: A birthday cake with a candle on it. The candle is the number "32".
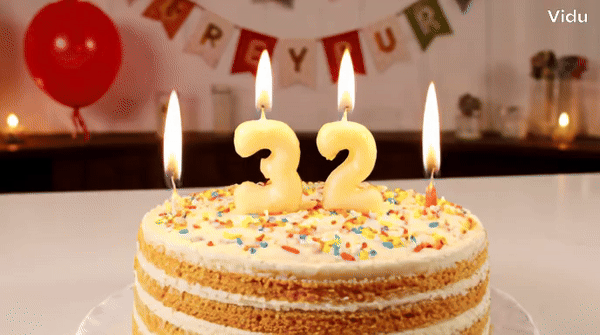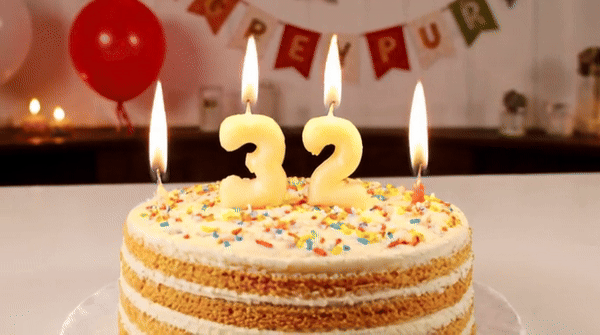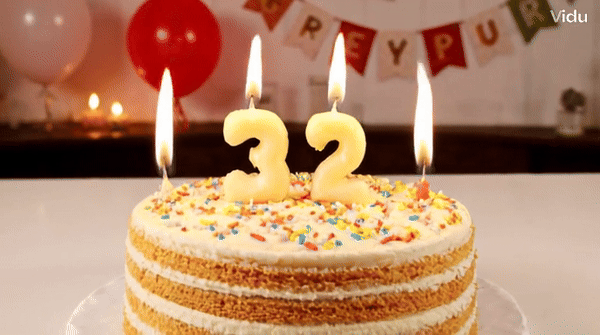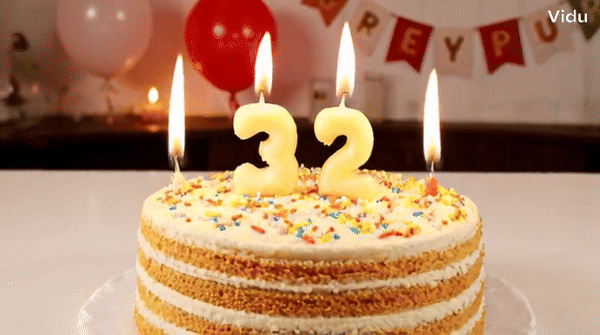
Change the words "Happy Birthday" on the cake and it will hold up.
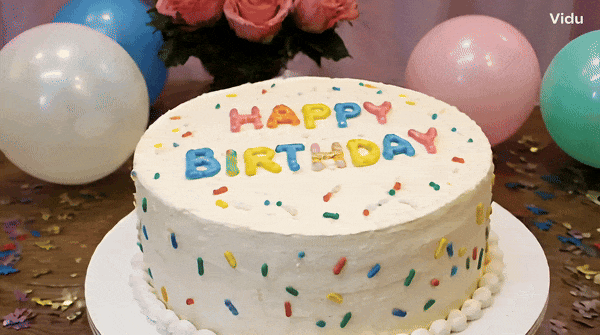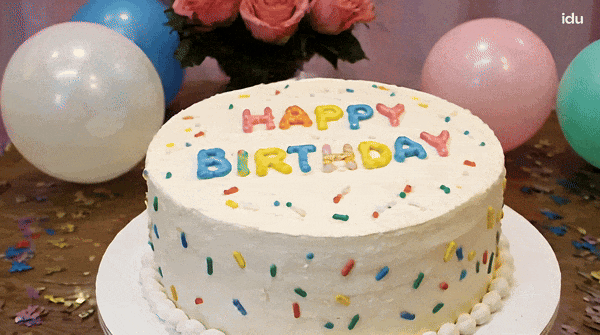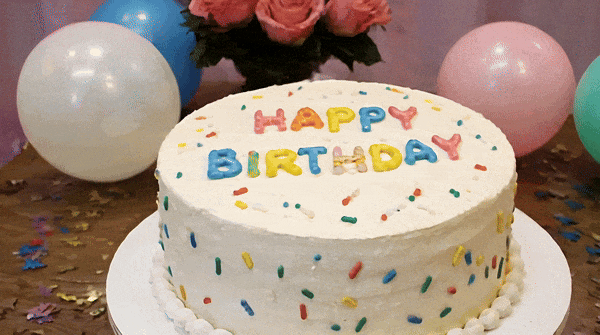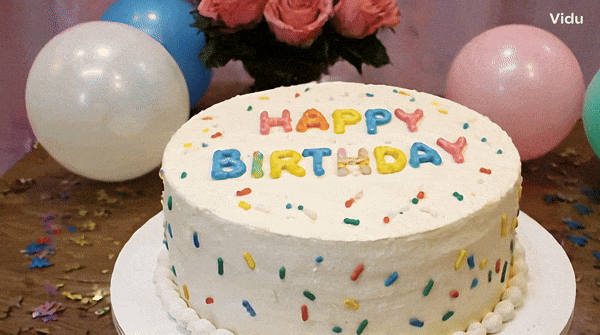
A piece of cake with "HAPPY BIRTHDAY" written on it.
Anime style is easy to use
Most of the AI video tools currently on the market are limited to realistic styles or based on realistic imagination, while Vidu not only supports realistic styles, but also supports anime styles.
We choose the animation model and directly enter the prompt word to output the animation style video.
For example, prompt word: anime style, little girl standing in the kitchen chopping vegetables.
To be honest, this style of painting has the flavor of Hayao Miyazaki. Vidu understood the prompt words, and the little girl cut vegetables smoothly, but her fingers and knives were still deformed inadvertently.
Prompt word: Anime style, a little girl wearing headphones is dancing.

Vidu has quite a lot of imagination. He set the background to a park with a fountain, which also made the video less monotonous.
 Of course, we can also upload an anime reference picture and enter the prompt word, so that the anime characters in the picture can move.
Of course, we can also upload an anime reference picture and enter the prompt word, so that the anime characters in the picture can move.
For example, we upload a static picture of Crayon Shin-chan, and then enter the prompt word: Crayon Shin-chan laughed and raised the little flower in his hand. Select "Use as starting frame" for image usage.
Jetons un coup d'œil à l'effet :
 Ensuite, téléchargez une image du mignon Pikachu et entrez le mot d'invite "Pikachu saute joyeusement". Sélectionnez « Utiliser comme image de départ » pour l'utilisation de l'image.
Ensuite, téléchargez une image du mignon Pikachu et entrez le mot d'invite "Pikachu saute joyeusement". Sélectionnez « Utiliser comme image de départ » pour l'utilisation de l'image.

Continuez à appliquer l'effet :
 Téléchargez l'image de Luffy de "One Piece" et donnez-lui le mot d'invite : Le garçon s'est soudainement mis à pleurer.
Téléchargez l'image de Luffy de "One Piece" et donnez-lui le mot d'invite : Le garçon s'est soudainement mis à pleurer.

L'effet est le suivant :
 Je dois dire que l'effet d'animation de Vidu est assez étonnant. Tout en conservant la cohérence du style, la stabilité et la fluidité de l'image sont considérablement améliorées, et il y en a. pas de déformation ni d'effondrement. Ni de scènes « maléfiques » comme le maniaque à six doigts et les jambes gauche et droite indistinctes.
Les mèmes et les émoticônes deviennent ennuyeux
Dans la section "Tusheng Video", en plus de prendre en charge le téléchargement de la première image d'image, Vidu a également introduit cette fois une nouvelle fonctionnalité - la cohérence des personnages ( Personnage à la vidéo).
La soi-disant cohérence des personnages consiste à télécharger une image de personnage, puis vous pouvez spécifier le personnage pour effectuer n'importe quelle action dans n'importe quelle scène.
Je dois dire que l'effet d'animation de Vidu est assez étonnant. Tout en conservant la cohérence du style, la stabilité et la fluidité de l'image sont considérablement améliorées, et il y en a. pas de déformation ni d'effondrement. Ni de scènes « maléfiques » comme le maniaque à six doigts et les jambes gauche et droite indistinctes.
Les mèmes et les émoticônes deviennent ennuyeux
Dans la section "Tusheng Video", en plus de prendre en charge le téléchargement de la première image d'image, Vidu a également introduit cette fois une nouvelle fonctionnalité - la cohérence des personnages ( Personnage à la vidéo).
La soi-disant cohérence des personnages consiste à télécharger une image de personnage, puis vous pouvez spécifier le personnage pour effectuer n'importe quelle action dans n'importe quelle scène.
Prenons Wu Jing comme exemple. ♥ Mots d'invite : Dans un vaisseau spatial, Wu Jing porte une combinaison spatiale et fait signe à la caméra.



Si le téléchargement de la première image d'image convient à la création d'une vidéo avec une cohérence de scène, alors avec la fonction de cohérence des rôles, les acteurs peuvent passer 72 fois de rôles de science-fiction à des drames modernes à portée de main.
De plus, grâce à la fonction de cohérence des rôles, les utilisateurs ordinaires peuvent s'amuser à créer des « mèmes » et des « émoticônes » !
Par exemple, les nord-américains "inoubliables" Justin Bieber et Selena ont renouvelé leur relation :
Dans "Wulin Gaiden", Tong Xiangyu et Bai Zhantang mangeaient des graines de melon et discutaient des potins du Tongfu Inn :
Il y a aussi la reine impératrice qui pleure de grief dans "La Légende de Zhen Huan":

Tant que votre imagination est assez grande, Vidu peut faire manger son téléphone portable au vieil homme du métro, Ao Bai et Wei Xiaobao jouant au bo, et grand-mère Rong nourrissant des pilons de poulet Ziwei.
Quelle est la chose la plus ennuyeuse pour les utilisateurs pendant le processus de génération vidéo ? Bien sûr, c'est une barre de progression rampante.
Imaginez, allongé devant l'ordinateur et attendant dix minutes une vidéo de quelques secondes, peu importe l'impatience d'une personne, il sera difficile de ne pas briser la défense.
Actuellement, les outils vidéo d'IA grand public sur le marché génèrent un clip vidéo d'environ 4 secondes, ce qui prend généralement 1 à 5 minutes, voire plus.
Par exemple, le dernier outil Gen-3 de Runway prend 1 minute pour terminer la génération vidéo 5s, Keling prend 2-3 minutes et Vidu réduit ce temps d'attente à 30 secondes, ce qui est plus rapide que le plus rapide du secteur. Gen-3 est deux fois plus rapide.

Basé sur l'architecture U-ViT entièrement auto-développée, soigneusement conçue pour un usage commercial
La couche inférieure de "Vidu" est basée sur l'architecture U-ViT entièrement auto-développée, qui a été proposée par l'équipe en septembre 2022. L'architecture DiT adoptée avant Sora est la première architecture au monde à intégrer Diffusion et Transformer.

Deux mois avant la publication de l'article DiT, l'équipe de Zhu Jun de l'Université Tsinghua a soumis un article intitulé "Tous valent des mots : une épine dorsale ViT pour les modèles de diffusion". Cet article propose une architecture de réseau U-ViT qui utilise Transformer pour remplacer l'U-Net basé sur CNN. C'est la base technique la plus importante de "Vidu".
Comme elle n'implique pas de traitement en plusieurs étapes tel que l'insertion et l'épissage d'images intermédiaires, la conversion du texte en vidéo est directe et continue. Le travail de "Vidu" semble plus ponctuel et la vidéo est générée en continu du début à la fin. fin, sans aucune trace d'insertion de cadre. En plus des innovations dans l'architecture sous-jacente, « Vidu » réutilise également l'expérience et les capacités d'ingénierie accumulées par Shengshu Technology dans le passé.
Shengshu Technology a dit un jour que de l'unification des tâches graphiques à l'intégration des capacités vidéo, « Vidu » peut être considéré comme un modèle visuel universel pouvant prendre en charge la génération de contenu vidéo plus diversifié et plus long. Ils ont également révélé que « Vidu » continue d’accélérer les améliorations itératives. Face à l’avenir, l’architecture de modèle flexible de « Vidu » sera également compatible avec un plus large éventail de capacités multimodales.
Shengshu Technology a été créée en mars 2023. Les principaux membres sont issus de l'Institut de recherche en intelligence artificielle de l'Université Tsinghua et s'engagent à développer de manière indépendante le premier grand modèle général multimodal contrôlable au monde. Depuis sa création en 2023, l'équipe a été reconnue par de nombreuses institutions industrielles bien connues telles que Ant Group, Qiming Venture Partners, BV Baidu Ventures, Byte Jinqiu Fund, etc., et a réalisé un financement de centaines de millions de yuans. Il est rapporté que Shenshu Technology est actuellement l'équipe entrepreneuriale la plus valorisée dans le secteur des grands modèles multimodaux en Chine.
Le scientifique en chef de l'entreprise est Zhu Jun, directeur adjoint de l'Institut de recherche sur l'intelligence artificielle de Tsinghua.
PDG Tang Jiayua étudié au département d'informatique de l'Université de Tsinghua et est membre du groupe THUNLP ; doctorant au Département d'informatique de l'Université Tsinghua et professeur Zhu Jun. Membre de l'équipe de recherche, il s'intéresse depuis longtemps à la recherche dans le domaine des modèles de diffusion. Il a dirigé la réalisation d'U-ViT et d'UniDiffuser.
En janvier de cette année, PixWeaver, une plate-forme de conception créative visuelle appartenant à Shengshu Technology, a lancé une fonction de génération de vidéos courtes, prenant en charge un contenu vidéo court hautement esthétique de 4 secondes. Après le lancement de Sora en février, Shengshu Technology a créé une équipe de recherche interne pour accélérer les progrès de la recherche et du développement dans le sens vidéo original. En moins d'un mois, elle a réalisé une génération vidéo de 8 secondes en interne, puis a franchi la barre des 16. -deuxième génération vidéo en avril, réalisant des percées dans tous les aspects de la qualité et de la durée de la génération.
Si la sortie du modèle en avril a démontré le leadership de Vidu en matière de capacités de génération vidéo, le produit officiellement lancé démontre cette fois la mise en page soignée de Vidu en matière de commercialisation. Shengshu Technology adopte actuellement un modèle bidirectionnel de couche modèle et de couche application.
D'une part, créez un grand modèle polyvalent de bas niveau qui couvre des fonctionnalités multimodales telles que le texte, les images, les vidéos et les modèles 3D, et fournissez des capacités de service de modèle pour la face B.
D'autre part, les applications verticales sont créées pour des scénarios tels que la génération d'images et la génération de vidéos, et sont facturées sous forme d'abonnements. La direction des applications est principalement destinée aux scénarios de création de contenu tels que la production de jeux et le cinéma et la télévision. post-production.
Lien de référence :
Lien du site officiel de Vidu : www.vidu.studio
The above is the detailed content of Another 'domestic version of Sora' is launched globally! Tsinghua Zhu Jun's entrepreneurial team, video generation only takes 30 seconds. For more information, please follow other related articles on the PHP Chinese website!



 iscsiadm common commands
iscsiadm common commands How to activate computer windows
How to activate computer windows Solution to insufficient cloud storage space
Solution to insufficient cloud storage space Recommended computer hardware testing software rankings
Recommended computer hardware testing software rankings How to solve the problem that js code cannot run after formatting
How to solve the problem that js code cannot run after formatting Introduction to the usage of MySQL ELT function
Introduction to the usage of MySQL ELT function How to solve unavailable
How to solve unavailable Can I retrieve a deleted Douyin short video?
Can I retrieve a deleted Douyin short video?




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



