
Subverting past large model evaluation standards, the latest, most comprehensive and authoritative evaluation data set MR-Ben is here!
This is a highly representative work proposed again by the Hong Kong Chinese Jiajiaya team after the release of Mini-Gemini, a powerful visual language model called GPT-4 + DALL-E-3, in April this year. Under the "supervision" of MR-Ben, the large model must not only be able to answer questions like a student, but also be able to mark papers like a teacher, leaving no trace of its true reasoning ability.
MR-Ben has carefully evaluated many domestic and foreign first-line open source and closed source models, such as GPT4-Turbo, Cluade3.5-Sonnet, Mistral-Large, Zhipu-GLM4, Moonshot-v1, Yi-Large, Qwen2-70B , Deepseek-V2, etc., and conducted detailed analysis.
Which seemingly beautiful large models will be "removed", and which model has the strongest surface? At present, all the code and data of this work are open source, let’s take a look!
Project Page: https://randolph-zeng.github.io/Mr-Ben.github.io/
Arxiv Page: https://arxiv.org/abs/2406.13975
Github Repo: https://github.com /dvlab-research/Mr-Ben
MR-Ben breaks the "high score and low energy" of large models in seconds
After the field of artificial intelligence entered the GPT moment, academia and industry worked together, and new models were released every month or even every week .
Large models emerge in endlessly. What standards are used to measure the specific capabilities of large models? The current mainstream direction is to use human standardized tests - multiple choice questions and fill-in-the-blank questions to conduct large model evaluations. There are many benefits of using this test method, which can be divided into the following points in simple terms:
• Standardized tests are easy to quantify and evaluate. The standards are clear, and what is right is right and what is wrong is wrong.
• The indicators are intuitive, and it is easy to compare and understand the scores obtained in the domestic college entrance examination or the American college entrance examination SAT.
• Quantitative results are naturally topical (for example, GPT4’s ability to easily pass the U.S. Bar Certification Examination is extremely eye-catching).
But if you delve into the training method of large models, you will find that this step-by-step thinking chain method to generate the final answer is not "reliable".
The question appears precisely in the step-by-step answer process!
The pre-training model has already seen trillions of word elements during pre-training. It is difficult to say whether the model being evaluated has already seen the corresponding data and can answer the questions correctly by "memorizing the questions". In the step-by-step answer, we don’t know whether the model selects the correct option based on correct understanding and reasoning, because the evaluation method mainly relies on checking the final answer.
Although the academic community continues to upgrade and transform data sets such as GSM8K and MMLU, such as introducing a multi-language version of the MGSM data set on GSM8K and introducing more difficult questions based on MMLU, there is still no way to get rid of the problem of selecting or filling in the blanks. Unruly.
Moreover, these data sets have all faced serious saturation problems. The values of large language models on these indicators have peaked and they have gradually lost their distinction.
To this end, the Jiajiaya team teamed up with many well-known universities such as MIT, Tsinghua, and Cambridge, and cooperated with domestic head annotation companies to annotate a evaluation data set MR-Ben for the reasoning process of complex problems.
MR-Ben has carried out a "grading" paradigm transformation based on the questions from the pre-training and test data sets of large models such as GSM8K, MMLU, LogiQA, MHPP and other large models. The generated new data sets are more difficult, more differentiated and more realistic. It reflects the model’s reasoning ability!
The Jiajiaya team’s work this time also made targeted improvements to address existing evaluation pain points:
Aren’t you afraid that data leakage will lead to large-scale model memorization of questions, resulting in inflated scores? There is no need to re-find the questions or deform the questions to test the robustness of the model. MR-Ben directly changes the model from the student identity of the answerer to the "grading" mode of the answer process, allowing the big model to be the teacher to test How well does it master the knowledge points!
Aren’t you worried that the model has no awareness of the problem-solving process, and may have “illusions” or misunderstandings, and get the answer wrong? MR-Ben directly recruits a group of high-level master's and doctoral annotators to carefully annotate the problem-solving process of a large number of questions. Point out in detail whether the problem-solving process is correct, the location of the error, and the reason for the error, and compare the grading results of the large model and the grading results of human experts to test the model's knowledge of the knowledge points.
Specifically, the Jiajiaya team organized the mainstream evaluation data sets on the market such as GSM8K, MMLU, LogiQA, MHPP and other data sets, and divided them into multiple categories such as mathematics, physics, chemistry, biology, code, logic, medicine, etc., and also distinguished Different difficulty levels. For each category and each question collected, the team carefully collected the corresponding step-by-step problem-solving process, and was trained and annotated by professional master's and doctoral annotators.
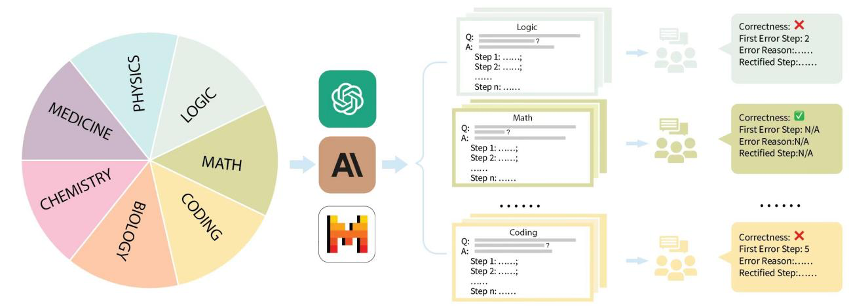
The construction process of MR-Ben dataset
What is the best performing large model?
接下來,讓我們結合MR-Ben工作中給出的具體例子,看看為什麼說逐步作答產生最終答案的方式和相關評測不靠譜。
作為被評測的「閱卷」模型,GPT4-Turbo並未發現第二步所隱藏的計算錯誤:
E.1 數學
科目:高中數學
問題:哪個最小的整數被4除餘1,被3除餘2,被5除餘2?
選項:[A] 67 [B] 43 [C] 57 [D] 37
答案:D
取樣模型:Claude2
模型解步驟:
可以看到,當給定問題、確定的解答過程,評測語言模型的方式就轉換成了讓模型對解答過程進行「閱卷」並評判正誤、指出錯誤位置及原因。其中解答過程的正誤,潛在的出錯位置可以透過與標註結果進行比對來計算。而模型出錯步驟和原因的評測,則可以交由GPT4,透過比較標註人員給出的錯誤原因解釋和模型的錯誤原因解釋,來判斷模型是否正確。
從評測方式來看,MR-Ben所提出的方法需要模型對於解題過程的每一個步驟的前提、假設、邏輯都進行細緻分析,並對推理過程進行預演來判斷當前步驟是否能導向正確答案。 fenye1. 這種「閱卷」式的評測方式從難度上遠超於僅答題的評測方式,但可有效避免模型背題所導致的分數虛高問題。而只會背題的學生很難成為合格的閱卷老師。 -
- 其次,MR-Ben透過使用了人力精細的標註流程控制,取得了大量的高品質標註,而巧妙的流程設計又使得評測方式能夠直觀地量化。
 賈佳亞團隊也針對性測試了時下最具代表性的十大大語言模型和不同版本。可以看到,閉源大語言模型裡,GPT4-Turbo的表現最佳(雖然在「閱卷」時未能發現計算錯誤),在絕大部分的科目裡,有demo(k=1)和無demo (k=0)的設定下都領先其他模型。
賈佳亞團隊也針對性測試了時下最具代表性的十大大語言模型和不同版本。可以看到,閉源大語言模型裡,GPT4-Turbo的表現最佳(雖然在「閱卷」時未能發現計算錯誤),在絕大部分的科目裡,有demo(k=1)和無demo (k=0)的設定下都領先其他模型。
🎜🎜**部分開源大語言模型在MR-Ben資料集上的評估結果
可以看到,最強的部分開源大語言模型效果已經趕上了部分商用模型,並且即使最強的閉源模型在MR- Ben資料集上表現也仍未飽和,不同模型間的區分度較大。
除此之外,MR-Ben的原論文裡還有更多有趣的解析和發現,例如:
Qwen和Deepseek發布的開源模型即使在全球梯隊裡,PK閉源模型效果也不遜色。
不同的閉源模式定價策略與實際表現耐人尋味。在使用場景裡關注推理能力的小夥伴,可以對照價格和能力找到自己心儀的模型去使用。
低資源場景下,小模型也有不少亮點,MR-Ben評測中Phi-3-mini在一眾小模型裡脫穎而出,甚至高於或持平幾百億參數的大模型,展現出了微調數據的重要性。
MR-Ben場景包含複雜的邏輯解析和逐步推斷,Few-shot模式下過長的上下文反而會使得模型困惑,造成水平下降的後果。
MR-Ben評估了不少產生-反思-重生成的消融實驗,查看不同提示策略的差異,發現對低水平的模型沒有效果,對高水平的模型如GPT4-Turbo效果也不明顯。反而對中間水平的模型因為總把錯的改對,對的改錯,效果反而略有提升。
將MR-Ben評測的科目大致分割成知識型、邏輯型、計算型、演算法型後,不同的模式在不同的推理類型上各有優劣。
賈佳亞團隊已在github上傳一鍵評測的方式,歡迎所有關注複雜推理的小伙伴在自家的模型上評測並提交,團隊會及時更新相應的leaderboard。
對了,使用官方的腳本一鍵評測,只需花費12M tokens左右,過程非常絲滑,不妨一試!
參考
Training Verifiers to Solve Math Word Problems(https://arxiv.org/abs/2110.14168)
Measuring Massive Multitask Language Understanding(https://arxiv.org/abs/QA Dataset for Machine Reading Comprehension with Logical Reasoning(https://arxiv.org/abs/2007.08124)
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation(https://arxiv.org/abs/3uage Models Beyond Basic Code Generation(https://arxiv.org/abs/12430) Sparks of Artificial General Intelligence: Early experiments with GPT-4(https://arxiv.org/abs/2303.12712)
Qwen Technical Report(https://arxiv.org/abs/2309.16609)
DeepSeek-V2:16609)
Deep Strong,V2: Economical, and Efficient Mixture-of-Experts Language Model(https://arxiv.org/abs/2405.04434)
Textbooks Are All You Need(https://arxiv.org/abs/2306.11644)
Large Self- Models Correct Reasoning Yet(https://arxiv.org/abs/2310.01798)
The above is the detailed content of Jia Jiaya team teamed up with Cambridge Tsinghua University and others to promote a new evaluation paradigm to detect 'high scores and low energy' in large models in one second. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



