



The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Yizuo Diao Haiwen is a doctoral student at Dalian University of Technology, and his supervisor is Professor Lu Huchuan. Currently interning at Beijing Zhiyuan Artificial Intelligence Research Institute, the instructor is Dr. Wang Xinlong. His research interests are vision and language, efficient transfer of large models, multi-modal large models, etc. Co-first author Cui Yufeng graduated from Beihang University and is an algorithm researcher at the Vision Center of Beijing Zhiyuan Artificial Intelligence Research Institute. His research interests are multimodal models, generative models, and computer vision, and his main work is in the Emu series.
Recently, research on multi-modal large models has been in full swing, and the industry has invested more and more in this. Hot models have been launched abroad, such as GPT-4o (OpenAI), Gemini (Google), Phi-3V (Microsoft), Claude-3V (Anthropic), and Grok-1.5V (xAI). At the same time, domestic GLM-4V (Wisdom Spectrum AI), Step-1.5V (Step Star), Emu2 (Beijing Zhiyuan), Intern-VL (Shanghai AI Laboratory), Qwen-VL (Alibaba), etc. Models bloom.
The current visual language model (VLM) usually relies on the visual encoder (Vision Encoder, VE) to extract visual features, and then combines the user instructions with the large language model (LLM) for processing and answering. The main challenge lies in the visual encoder and Training separation for large language models. This separation causes visual encoders to introduce visual induction bias issues when interfacing with large language models, such as limited image resolution and aspect ratio, and strong visual semantic priors. As the capacity of visual encoders continues to expand, the deployment efficiency of multi-modal large models in processing visual signals is also greatly limited. In addition, how to find the optimal capacity configuration of visual encoders and large language models has become increasingly complex and challenging.
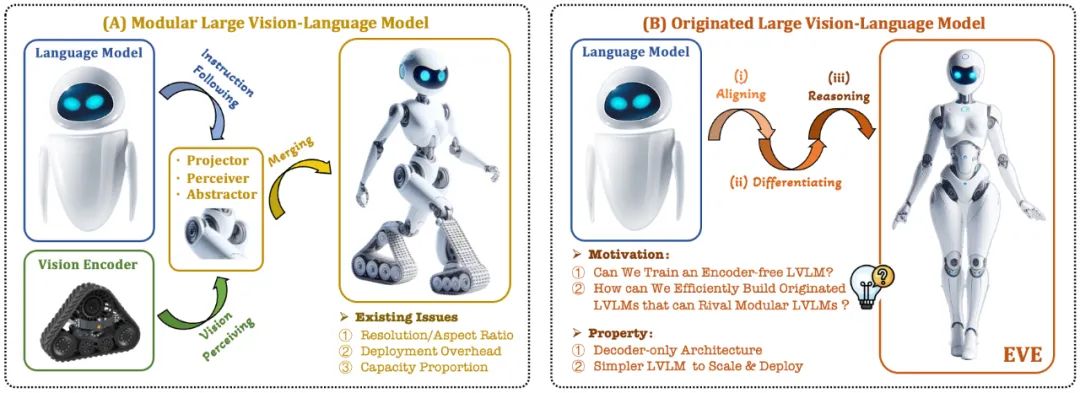
In this context, some more cutting-edge ideas quickly emerged:
Can we remove the visual encoder, that is, directly build a native multi-modal large model without a visual encoder?
How to efficiently and smoothly evolve a large language model into a native multi-modal large model without visual encoder?
How to bridge the performance gap between encoder-less native multi-modal frameworks and mainstream encoder-based multi-modal paradigms?
Adept AI released the Fuyu series model at the end of 2023 and made some related attempts, but did not disclose any training strategies, data resources and equipment information. At the same time, there is a significant performance gap between the Fuyu model and mainstream algorithms in public visual text evaluation indicators. During the same period, some pilot experiments we conducted showed that even if the scale of pre-training data is increased on a large scale, the native multi-modal large model without encoder still faces thorny problems such as slow convergence speed and poor performance.
In response to these challenges, the vision team of Zhiyuan Research Institute, together with Dalian University of Technology, Peking University and other domestic universities, launched a new generation of coder-free visual language model EVE. Through refined training strategies and additional visual supervision, EVE integrates visual-linguistic representation, alignment, and inference into a unified pure decoder architecture. Using publicly available data, EVE performs well on multiple visual-linguistic benchmarks, competing with mainstream encoder-based multimodal methods of similar capacity and significantly outperforming fellow Fuyu-8B. EVE is proposed to provide a transparent and efficient path for the development of native multi-modal architectures for pure decoders.


Paper address: https://arxiv.org/abs/2406.11832
Project code: https://github.com/baaivision/EVE
Model address: https ://huggingface.co/BAAI/EVE-7B-HD-v1.0
1. Technical Highlights
Native visual language model: breaks the fixed paradigm of mainstream multi-modal models, removes the visual encoder, and can handle any image aspect ratio. It significantly outperforms the same type of Fuyu-8B model in multiple visual language benchmarks and is close to the mainstream visual encoder-based visual language architecture.
Low data and training costs: The pre-training of the EVE model only screened public data from OpenImages, SAM and LAION, and utilized 665,000 LLaVA instruction data and an additional 1.2 million visual dialogue data to build respectively Regular and high-resolution versions of EVE-7B. Training takes approximately 9 days to complete on two 8-A100 (40G) nodes, or approximately 5 days on four 8-A100 nodes.
Transparent and efficient exploration: EVE tries to explore an efficient, transparent and practical path to the native visual language model, providing new ideas and valuable experience for the development of a new generation of pure decoder visual language model architecture. The development of future multimodal models opens up new exploration directions.
2. Model structure
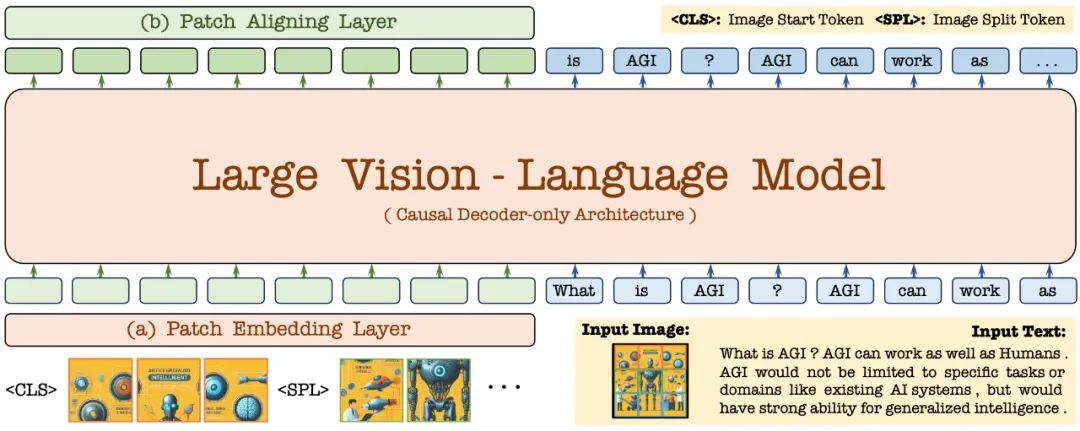
First, it is initialized through the Vicuna-7B language model, so that it has rich language knowledge and powerful instruction following capabilities. On this basis, the deep visual encoder is removed, a lightweight visual encoding layer is constructed, the image input is efficiently and losslessly encoded, and input into a unified decoder together with user language commands. In addition, the visual alignment layer performs feature alignment with a general visual encoder to enhance fine-grained visual information encoding and representation.
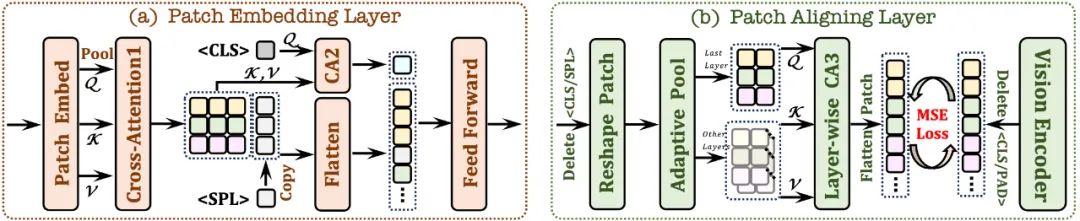
2.1 Patch Embedding Layer
First use a single convolutional layer to obtain the 2D feature map of the image, and then downsample through the average pooling layer;
Use the cross attention module (CA1) Interact in a limited receptive field to enhance the local features of each patch;
uses token and combined with the cross attention module (CA2) to provide global information for each subsequent patch feature;
in each patch feature A learnable token is inserted at the end of the line to help the network understand the two-dimensional spatial structure of the image.
2.2 Patch Aligning Layer
Record the 2D shape of the valid patch; discard /
through hierarchical cross-attention Module (CA3), integrates multi-layer network visual features to achieve fine-grained alignment with the visual encoder output.
3. Training strategy
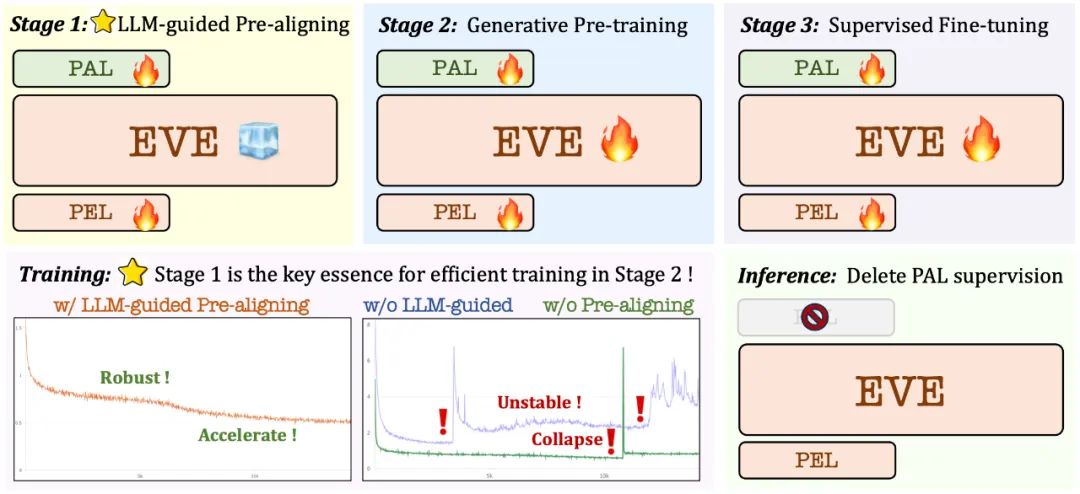
Pre-training stage guided by large language model: establish the initial connection between vision and language, laying the foundation for subsequent stable and efficient large-scale pre-training;
Generative pre-training phase: further improve the model's ability to understand visual-linguistic content and achieve a smooth transition from a pure language model to a multi-modal model;
Supervised fine-tuning phase: further standardize the model to follow language instructions and the ability to learn conversational patterns that meet the requirements of various visual language benchmarks.

In the pre-training stage, 33 million public data from SA-1B, OpenImages and LAION were filtered, and only image samples with a resolution higher than 448×448 were retained. In particular, to address the problem of high redundancy in LAION images, 50,000 clusters were generated by applying K-means clustering on the image features extracted by EVA-CLIP, and the 300 images closest to each cluster center were selected. images, and finally selected 15 million LAION image samples. Subsequently, high-quality image descriptions were regenerated using Emu2 (17B) and LLaVA-1.5 (13B).
In the supervised fine-tuning stage, use the LLaVA-mix-665K fine-tuning data set to train the standard version of EVE-7B, and integrate mixed data such as AI2D, Synthdog, DVQA, ChartQA, DocVQA, Vision-Flan and Bunny-695K Set to train to obtain a high-resolution version of EVE-7B.
4. Quantitative analysis
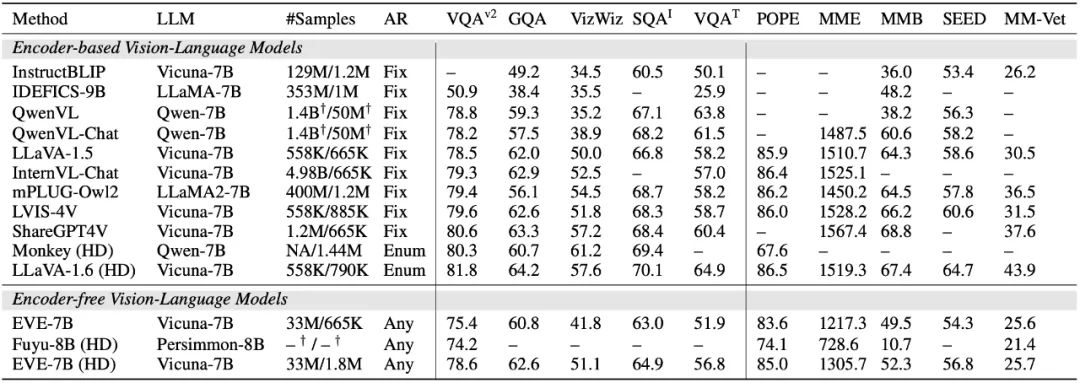
The EVE model significantly outperforms the similar Fuyu-8B model in multiple visual language benchmarks, and performs on par with a variety of mainstream encoder-based visual language models. However, due to the use of a large amount of visual language data for training, there are challenges in accurately responding to specific instructions, and its performance in some benchmark tests needs to be improved. What is exciting is that through efficient training strategies, the encoder-less EVE can achieve comparable performance to the encoder-based visual language model, fundamentally solving the problems of input size flexibility, deployment efficiency and modality of mainstream models. Capacity matching issues.
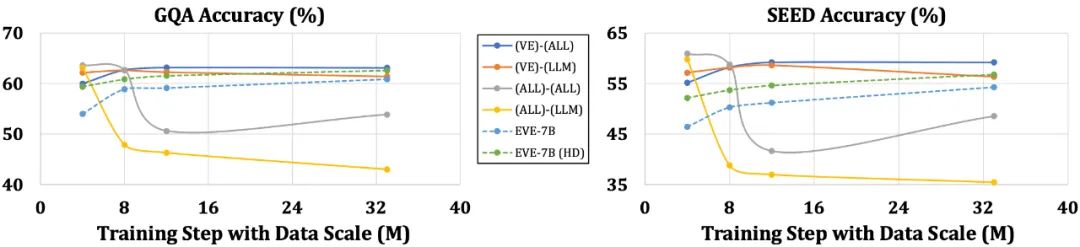
Compared with models with encoders, which are susceptible to problems such as simplification of language structure and loss of rich knowledge, EVE has shown a gradual and stable improvement in performance as the data size increases, gradually approaching the performance of encoder-based models level. This may be because encoding and aligning visual and language modalities in a unified network is more challenging, making encoder-free models less prone to overfitting relative to models with encoders.
5. What do your peers think?
Ali Hatamizadeh, senior researcher at NVIDIA, said that EVE is refreshing and tries to propose a new narrative, which is different from the construction of complex evaluation standards and progressive visual language model improvements.

Armand Joulin, principal researcher at Google Deepmind, said that it is exciting to build a pure decoder visual language model.

Apple machine learning engineer Prince Canuma said that the EVE architecture is very interesting and is a good addition to the MLX VLM project set.

6. Future Outlook
As an encoder-less native visual language model, EVE has currently achieved encouraging results. Along this path, there are some interesting directions worth exploring in the future:
Further performance improvement: Experiments found that pre-training using only visual-linguistic data significantly reduced the language ability of the model (SQA score from 65.3% dropped to 63.0%), but the multi-modal performance of the model was gradually improved. This indicates that there is an internal catastrophic forgetting of language knowledge when large language models are updated. It is recommended to appropriately integrate pure language pre-training data or use a mixture of experts (MoE) strategy to reduce the interference between visual and language modalities.
Imagination of encoder-less architecture: With appropriate strategies and training with high-quality data, encoder-less visual language models can rival models with encoders. So under the same model capacity and massive training data, what is the performance of the two? We speculate that by expanding the model capacity and training data amount, the encoder-less architecture can reach or even surpass the encoder-based architecture, because the former inputs images almost losslessly and avoids the a priori bias of the visual encoder.
Construction of native multi-modal models: EVE completely demonstrates how to efficiently and stably build native multi-modal models, which opens up transparency for the subsequent integration of more modalities (such as audio, video, thermal imaging, depth, etc.) and practical paths. The core idea is to pre-align these modalities through a frozen large language model before introducing large-scale unified training, and utilize corresponding single-modal encoders and language concept alignment for supervision.
The above is the detailed content of Abandoning the visual encoder, this 'native version' multi-modal large model is also comparable to mainstream methods. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



