


The four major VLMs are all trying to blindly touch the elephant?
Let the most popular SOTA models (GPT-4o, Gemini-1.5, Sonnet-3, Sonnet-3.5) count how many intersections there are between two lines. Will they perform better than humans?
The answer is probably no.
Since the launch of GPT-4V, visual language models (VLMs) have made the intelligence of large models a big step forward towards the level of artificial intelligence we imagined.
VLMs can both understand pictures and use language to describe what they see, and perform complex tasks based on these understandings. For example, if you send the VLM model a picture of a dining table and a picture of a menu, it can extract the number of beer bottles and the unit price on the menu from the two pictures, and calculate how much the beer cost for the meal.
VLMs have advanced so fast that it has become a task for the model to find out whether there are some unreasonable "abstract elements" in this picture. For example, it is necessary to ask the model to identify whether there is a person ironing clothes in a speeding taxi. A common assessment method.

However, the current benchmark test set does not evaluate the visual capabilities of VLMs well. Taking MMMU as an example, 42.9% of the questions can be solved without looking at pictures, which means that many answers can be inferred from text questions and options alone. Secondly, the capabilities currently demonstrated by VLM are largely the result of "memorizing" large-scale Internet data. This results in VLMs scoring very high in the test set, but this does not mean that the judgment is true: can VLMs perceive images like humans?
In order to get the answer to this question, researchers from Auburn University and the University of Alberta decided to "test vision" for VLMs. Inspired by the optometrist's "vision test", they asked four top VLMs: GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet and Claude-3.5 Sonnet to make a set of "vision test questions".

Paper title: Vision language models are blind
Paper link: https://arxiv.org/pdf/2407.06581
Project link: https://vlmsareblind.github.io/
This set of questions is very simple. For example, counting the number of intersections of two lines and identifying which letter is marked by a red circle requires almost no knowledge of the world. The test results are shocking. VLMs are actually "myopic" and the details of the image are actually blurred in their view.
VLM Blind or not? Seven major tasks, you can know them with just one test
In order to prevent VLMs from "copying answers" directly from Internet data sets, the author of the paper designed a new set of "vision tests". The authors of the paper chose to let VLMs determine the relationship between geometric figures in space, such as whether two figures intersect. Because the spatial information of these patterns on a white canvas usually cannot be described in natural language.
When humans process this information, they will perceive it through the "visual brain". But for VLMs, they rely on combining image features and text features in the early stages of the model, that is, integrating the visual encoder into a large language model, which is essentially a knowledge brain without eyes.
Preliminary experiments show that VLMs perform amazingly well when faced with human vision tests, such as the upside-down "E" eye chart that each of us has tested.
Test and results
Level 1: Count how many intersections are there between the lines?
The author of the paper created 150 images containing two line segments on a white background. The x-coordinates of these line segments are fixed and equally spaced, while the y-coordinates are randomly generated. There are only three intersection points between two line segments: 0, 1, and 2.

As shown in Figure 5, in the test of two versions of prompt words and three versions of line segment thickness, all VLMs performed poorly on this simple task.

Sonnet-3.5, which has the best accuracy, is only 77.33% (see Table 1).

More specifically, VLMs tend to perform worse when the distance between two lines shrinks (see Figure 6 below). Since each line graph consists of three key points, the distance between two lines is calculated as the average distance of three corresponding point pairs.

This result is in sharp contrast to the high accuracy of VLMs on ChartQA, which shows that VLMs are able to identify the overall trend of the line graph, but cannot "zoom in" to see details such as "which lines intersect".
Second level: Determine the positional relationship between two circles
As shown in the picture, the author of the paper randomly generated two circles of the same size on a canvas of a given size. There are only three situations in the positional relationship between two circles: intersection, tangency and separation. 
Surprisingly, in this task that is intuitively visible to humans and whose answer can be seen at a glance, no VLM can give the answer perfectly (see Figure 7).

The model with the best accuracy (92.78%) is Gemini-1.5 (see Table 2).

In experiments, one situation occurred frequently: when two circles are very close, VLMs tend to perform poorly but make educated guesses. As shown in the figure below, Sonnet-3.5 usually answers a conservative "no".

As shown in Figure 8, even when the distance between the two circles is far apart and has a radius (d = 0.5) as wide as that, GPT-4o, which has the worst accuracy, cannot achieve 100 % precise.
That said, VLM's vision doesn't seem to be clear enough to see the small gaps or intersections between the two circles.

Level 3: How many letters are circled in red?
Since the distance between letters in a word is very small, the authors of the paper hypothesized that if VLMs are "myopic", then they will not be able to recognize the letters circled in red.
So, they chose strings like "Acknowledgement", "Subdermatoglyphic" and "tHyUiKaRbNqWeOpXcZvM". Randomly generate a red circle to circle a letter in the string as a test.

The test results show that the tested models performed very poorly at this level (see Figure 9 and Table 3).


For example, visual language models tend to make mistakes when letters are slightly obscured by red circles. They often confuse the letters next to the red circle. Sometimes the model will produce hallucinations. For example, although it can spell the word accurately, it will add garbled characters (for example, "9", "n", "©") to the word.

All models except GPT-4o performed slightly better on words than on random strings, suggesting that knowing the spelling of a word may help visual language models make judgments, thereby slightly improving accuracy.
Gemini-1.5 and Sonnet-3.5 are the top two models with accuracy rates of 92.81% and 89.22% respectively, and outperform GPT-4o and Sonnet-3 by almost 20%.

Level 4 and Level 5: How many overlapping shapes are there? How many "matryoshka" squares are there?
Assuming that VLMs are "myopic", they may not be able to clearly see the intersection between each two circles in a pattern similar to the "Olympic rings". To this end, the author of the paper randomly generated 60 groups of patterns similar to the "Olympic Rings" and asked VLMs to count how many overlapping patterns they had. They also generated a pentagonal version of the "Olympic rings" for further testing.

Since VLMs perform poorly when counting the number of intersecting circles, the authors further tested the case when the edges of the pattern do not intersect and each shape is completely nested within another shape. They generated a "matryoshka"-like pattern of 2-5 squares and asked VLMs to count the total number of squares in the image.

It is easy to see from the bright red crosses in the table below that these two levels are also insurmountable obstacles for VLMs.

In the nested square test, the accuracy of each model varies greatly: GPT-4o (accuracy 48.33%) and Sonnet-3 (accuracy 55.00%) are at least better than Gemini-1.5 (80.00% accuracy) and Sonnet-3.5 (87.50% accuracy) are 30 percentage points lower.
This gap will be larger when the model counts overlapping circles and pentagons, but Sonnet-3.5 performs several times better than other models. As shown in the table below, when the image is a pentagon, Sonnet-3.5’s accuracy of 75.83% far exceeds Gemini-1.5’s 9.16%.
Surprisingly, all four models tested achieved 100% accuracy when counting 5 rings, but adding just one additional ring was enough to cause the accuracy to drop significantly to near zero.
However, when computing pentagons, all VLMs (except Sonnet-3.5) perform poorly even when computing 5 pentagons. Overall, computing 6 to 9 shapes (including circles and pentagons) is difficult for all models.

This shows that VLM is biased and they are more inclined to output the famous "Olympic rings" as the result. For example, Gemini-1.5 will predict the result as "5" in 98.95% of the trials, regardless of the actual number of circles (see Table 5). For other models, this prediction error occurs much more frequently for rings than for pentagons.

In addition to quantity, VLM also has different "preferences" in the color of shapes.
GPT-4o performs better on colored shapes than pure black shapes, while Sonnet-3.5 predicts better and better as the image size increases. However, when the researchers changed the color and image resolution, the accuracy of other models changed only slightly.
It is worth noting that in the task of calculating nested squares, even if the number of squares is only 2-3, GPT-4o and Sonnet-3 are still difficult to calculate. When the number of squares increases to four and five, all models fall far short of 100% accuracy. This shows that it is difficult for VLM to accurately extract the target shape even if the edges of the shapes do not intersect.

Level 6: Count how many rows are there in the table? How many columns are there?
While VLMs have trouble overlapping or nesting graphics, what do they see as tiling patterns? In the basic test set, especially DocVQA, which contains many tabular tasks, the accuracy of the tested models is ≥90%. The author of the paper randomly generated 444 tables with different numbers of rows and columns, and asked VLMs to count how many rows there were in the table? How many columns are there?
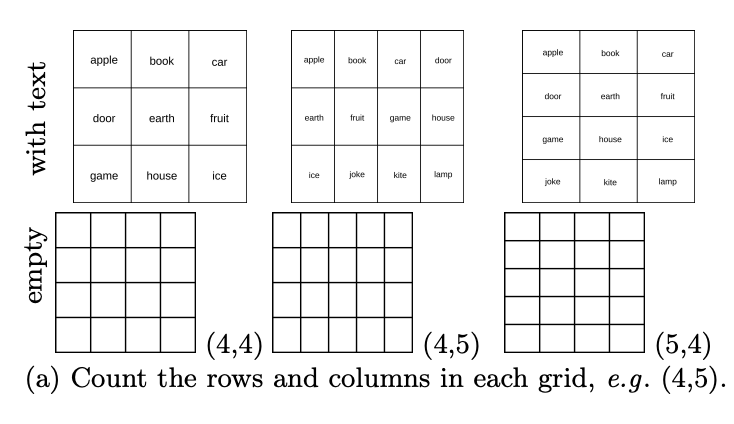
The results show that although it achieved high scores in the basic data set, as shown in the figure below, VLM also performed poorly in counting rows and columns in empty tables.

Specifically, they are usually 1-2 bars off. As shown in the figure below, GPT-4o recognizes the 4×5 grid as 4×4, and Gemini-1.5 recognizes it as 5×5.

This shows that while VLMs can extract important content from tables to answer table-related questions in DocVQA, they cannot clearly identify tables cell by cell.
This may be because the tables in the document are mostly non-empty, and VLM is not used to empty tables. Interestingly, after the researchers simplified the task by trying to add a word to each cell, a significant improvement in accuracy was observed for all VLMs, for example, GPT-4o improved from 26.13% to 53.03% (see Table 6 ). However, in this case, the performance of the model under test is still not perfect. As shown in Figure 15a and b, the best performing model (Sonnet-3.5) performed 88.68% in grids containing text and 59.84% in empty grids.
And most models (Gemini-1.5, Sonnet-3 and Sonnet-3.5) consistently perform better in counting columns than in counting rows (see Figure 15c and d).

Level 7: How many direct subway lines are there from the starting point to the destination?
This test tests the ability of VLMs to follow paths, which is crucial for the model to interpret maps, charts, and understand annotations such as arrows added by users in input images. To this end, the author of the paper randomly generated 180 subway line maps, each with four fixed stations. They asked VLMs to count how many monochromatic paths there are between two sites.

The test results are shocking. Even if the path between the two sites is simplified to only one, all models cannot achieve 100% accuracy. As shown in Table 7, the best performing model is Sonnet-3.5 with an accuracy of 95%; the worst model is Sonnet-3 with an accuracy of 23.75%.

It is not difficult to see from the figure below that the prediction of VLM usually has a deviation of 1 to 3 paths. As the map complexity increases from 1 to 3 paths, the performance of most VLMs becomes worse.

Faced with the "brutal fact" that today's mainstream VLM performs extremely poorly in image recognition, many netizens first put aside their status as "AI defense lawyers" and left many pessimistic comments.
A netizen said: “It’s embarrassing that the SOTA models (GPT-4o, Gemini-1.5 Pro, Sonnet-3, Sonnet-3.5) perform so poorly, and these models actually claim in their promotion: they can Understanding images? For example they could be used to help blind people or teach geometry to children!


On the other side of the pessimistic camp, one netizen believes that these poor results can be easily solved with training and fine-tuning. About 100,000 examples and trained with real data, the problem is solved

However, both the "AI defenders" and the "AI pessimists" have acquiesced in the fact that VLM still performs well in the image test. There are factual flaws that are extremely difficult to reconcile.
The author of the paper has also received more questions about whether this test is scientific.

Some netizens believe that the test in this paper does not prove that VLMs are "myopic". First of all, people with myopia do not see blurry details. "Blurry details" is a symptom of hyperopia. Secondly, not being able to see details is not the same thing as not being able to count the number of intersections. The accuracy of counting the number of rows and columns of a blank grid does not improve with increasing resolution, and increasing the resolution of the image does not help in understanding this task. Furthermore, increasing image resolution does not have a significant impact on understanding overlapping lines or intersections in this task.
In fact, the challenges faced by these visual language models (VLMs) in handling such tasks may have more to do with their reasoning capabilities and the way they interpret image content, rather than just a problem of visual resolution. In other words, even if every detail of an image is clearly visible, models may still not be able to accurately complete these tasks if they lack the correct reasoning logic or a deep understanding of visual information. Therefore, this research may need to delve deeper into the capabilities of VLMs in visual understanding and reasoning, rather than just their image processing capabilities.
Some netizens believe that if human vision is processed by convolution, humans themselves will also encounter difficulties in the test of judging the intersection of lines.
For more information, please refer to the original paper.
Reference links:
https://arxiv.org/pdf/2407.06581
https://news.ycombinator.com/item?id=40926734
https://vlmsareblind.github.io/
The above is the detailed content of Are all these VLMs blind? GPT-4o and Sonnet-3.5 successively failed the 'vision' test. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



