


In order to achieve high-precision regional-level multi-modal understanding, this paper proposes a dynamic resolution scheme to simulate the human visual cognitive system.
The author of this article is from the LAMP Laboratory of the University of Chinese Academy of Sciences. The first author Zhao Yuzhong is a doctoral student of the University of Chinese Academy of Sciences in 2023, and the co-author Liu Feng is a direct doctoral student of the University of Chinese Academy of Sciences in 2020. Their main research directions are visual language models and visual object perception.



 represents the size of the entire image, and t represents the interpolation coefficient. During training, we randomly select n views from candidate views to simulate images generated due to gaze and rapid eye movements. These n views correspond to the interpolation coefficient t, which is
represents the size of the entire image, and t represents the interpolation coefficient. During training, we randomly select n views from candidate views to simulate images generated due to gaze and rapid eye movements. These n views correspond to the interpolation coefficient t, which is
 . We fixedly retain the view containing only the reference region (i.e.
. We fixedly retain the view containing only the reference region (i.e.
 ). This view has been experimentally proven to help preserve regional details, which is crucial for all regional multi-modal tasks.
). This view has been experimentally proven to help preserve regional details, which is crucial for all regional multi-modal tasks.



 . This is shown on the left side of Figure 3. These region embeddings are not spatially aligned due to spatial errors introduced by cropping, resizing, and RoI-Align. Inspired by the deformable convolution operation, we propose an alignment module to reduce the bias by aligning
. This is shown on the left side of Figure 3. These region embeddings are not spatially aligned due to spatial errors introduced by cropping, resizing, and RoI-Align. Inspired by the deformable convolution operation, we propose an alignment module to reduce the bias by aligning
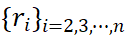 to
to
 , where
, where
 is the region embedding of the view encoding containing only the reference region. For each region embedding
is the region embedding of the view encoding containing only the reference region. For each region embedding
 , it is first concatenated with
, it is first concatenated with
 and then a 2D offset map is calculated through a convolutional layer. The spatial features of
and then a 2D offset map is calculated through a convolutional layer. The spatial features of
 are then resampled based on the 2D offset. Finally, the aligned region embeddings are concatenated along the channel dimension and fused through linear layers. The output is further compressed through a visual resampling module, i.e. Q-former, which extracts a regional representation of the reference region
are then resampled based on the 2D offset. Finally, the aligned region embeddings are concatenated along the channel dimension and fused through linear layers. The output is further compressed through a visual resampling module, i.e. Q-former, which extracts a regional representation of the reference region
 of the original image x (
of the original image x (
 in Figure 3).
in Figure 3).

 computed by the stochastic multi-view embedding module is decoded by three decoders
computed by the stochastic multi-view embedding module is decoded by three decoders
 as shown in Figure 3 (right), respectively supervised by three multi-modal tasks:
as shown in Figure 3 (right), respectively supervised by three multi-modal tasks:
 is shown in Figure 3 (right). The tagging process is completed by calculating the confidence of a predefined tag using the tag as query,
is shown in Figure 3 (right). The tagging process is completed by calculating the confidence of a predefined tag using the tag as query,
 as key and value. We parse labels from ground-truth subtitles to supervise the recognition decoder. ii) Region-text contrastive learning. Similar to the region tag decoder, the decoder
as key and value. We parse labels from ground-truth subtitles to supervise the recognition decoder. ii) Region-text contrastive learning. Similar to the region tag decoder, the decoder
 is defined as a query-based recognition decoder. The decoder computes similarity scores between subtitles and region features, supervised using SigLIP loss. iii) Language modeling. We use a pre-trained large language model
is defined as a query-based recognition decoder. The decoder computes similarity scores between subtitles and region features, supervised using SigLIP loss. iii) Language modeling. We use a pre-trained large language model
 to convert the regional representation
to convert the regional representation
 into a language description.
into a language description.

 . View one is fixed (
. View one is fixed ( ), view two is randomly selected or fixed.
), view two is randomly selected or fixed.
 of the sampled n views, we can obtain a regional representation with dynamic resolution characteristics. To evaluate the properties at different dynamic resolutions, we trained a dual-view (n=2) DynRefer model and evaluated it on four multi-modal tasks. As can be seen from the curves in Figure 4, attribute detection achieves better results for views without contextual information (
of the sampled n views, we can obtain a regional representation with dynamic resolution characteristics. To evaluate the properties at different dynamic resolutions, we trained a dual-view (n=2) DynRefer model and evaluated it on four multi-modal tasks. As can be seen from the curves in Figure 4, attribute detection achieves better results for views without contextual information (
 ). This can be explained by the fact that such tasks often require detailed regional information. For Region-level captioning and Dense captioning tasks, a context-rich view (
). This can be explained by the fact that such tasks often require detailed regional information. For Region-level captioning and Dense captioning tasks, a context-rich view (
 ) is required to fully understand the reference region. It is important to note that views with too much context (
) is required to fully understand the reference region. It is important to note that views with too much context (
 ) degrade performance on all tasks because they introduce too much region-irrelevant information. When the task type is known, we can sample appropriate views based on task characteristics. When the task type is unknown, we first construct a set of candidate views under different interpolation coefficients t,
) degrade performance on all tasks because they introduce too much region-irrelevant information. When the task type is known, we can sample appropriate views based on task characteristics. When the task type is unknown, we first construct a set of candidate views under different interpolation coefficients t,
 . From the candidate set, n views are sampled via a greedy search algorithm. The objective function of the search is defined as:
. From the candidate set, n views are sampled via a greedy search algorithm. The objective function of the search is defined as:
 where
where represents the interpolation coefficient of the i-th view,
represents the interpolation coefficient of the i-th view, represents the i-th view, pHASH (・) represents the perceptual image hash function, and
represents the i-th view, pHASH (・) represents the perceptual image hash function, and represents the XOR operation. In order to compare the information of views from a global perspective, we use the "pHASH (・)" function to convert the views from the spatial domain to the frequency domain and then encode them into hash codes. For this item
represents the XOR operation. In order to compare the information of views from a global perspective, we use the "pHASH (・)" function to convert the views from the spatial domain to the frequency domain and then encode them into hash codes. For this item , we reduce the weight of context-rich views to avoid introducing too much redundant information.
, we reduce the weight of context-rich views to avoid introducing too much redundant information.







The above is the detailed content of Surpassing the CVPR 2024 method, DynRefer achieves multiple SOTAs in regional-level multi-modal recognition tasks. For more information, please follow other related articles on the PHP Chinese website!
 Introduction to article tag attributes
Introduction to article tag attributes How to turn off windows security center
How to turn off windows security center The difference between WeChat service account and official account
The difference between WeChat service account and official account How to remove the first few elements of an array in php
How to remove the first few elements of an array in php What are the file server software?
What are the file server software? HOW TO INSTALL LINUX
HOW TO INSTALL LINUX What are the mobile operating systems?
What are the mobile operating systems? How to delete a directory in LINUX
How to delete a directory in LINUX




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



