


Feature selection is a key step in the process of building a machine learning model. Choosing good features for the model and the task we want to accomplish can improve performance.

If we are dealing with high-dimensional data sets, then selecting features is particularly important. It enables the model to learn faster and better. The idea is to find the optimal number of features and the most meaningful features.
In this article, we will introduce and implement a new feature selection through reinforcement learning strategy. We start by discussing reinforcement learning, specifically Markov decision processes. It is a very new method in the field of data science, especially suitable for feature selection. Then it introduces its implementation and how to install and use the python library (FSRLearning). Finally, a simple example is used to demonstrate this process.
Reinforcement learning (RL) techniques can be very effective in solving problems like game solving The problem. The concept of reinforcement learning is based on Markov Decision Process (MDP). The point here is not to get into an in-depth definition but to get a general understanding of how it works and how it can be useful for our problem. In reinforcement learning, an agent learns by interacting with its environment. It makes decisions by observing the current state and reward signals, and will receive positive or negative feedback based on the chosen action. The agent's goal is to maximize the cumulative reward by trying different actions. An important concept of reinforcement learning
The thinking behind reinforcement learning is that the agent starts from an unknown environment. Collect actions to complete the mission. The agent will be more inclined to choose some actions under the influence of its current state and previously selected actions. Each time a new state is reached and an action taken, the agent receives a reward. Here are the main parameters we need to define for feature selection:
State, action, reward, how to choose action
First, dataset A subset of the features that exist. For example, if the dataset has three features (age, gender, height) plus a label, the possible states are as follows:
[] --> Empty set [Age], [Gender], [Height] --> 1-feature set [Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set [Age, Gender, Height] --> All-feature set
In a state, The order of the features doesn't matter, we have to think of it as a set, not a list of features.
Regarding actions, we can go from one subset to any subset of unexplored features. In a feature selection problem, the action is to select features that have not yet been explored in the current state and add them to the next state. Here are some possible moves:
[Age] -> [Age, Gender] [Gender, Height] -> [Age, Gender, Height]
Here is an example of an impossible move:
[Age] -> [Age, Gender, Height] [Age, Gender] -> [Age] [Gender] -> [Gender, Gender]
We have defined the status and action, but not the reward yet. The reward is a real number used to evaluate the quality of the state.
In feature selection problems, one possible reward is to improve the accuracy metric of the same model by adding new features. Here is an example of how the reward is calculated:
[Age] --> Accuracy = 0.65 [Age, Gender] --> Accuracy = 0.76 Reward(Gender) = 0.76 - 0.65 = 0.11
For each state we visit for the first time, a classifier (model) is trained using a set of features . This value is stored in the state and the corresponding classifier. The process of training the classifier is time-consuming and laborious, so we only train it once. Because the classifier does not take into account the order of features, we can treat this problem as a graph rather than a tree. In this example, the reward for selecting “gender” as a new feature for the model is the difference in accuracy between the current state and the next state.
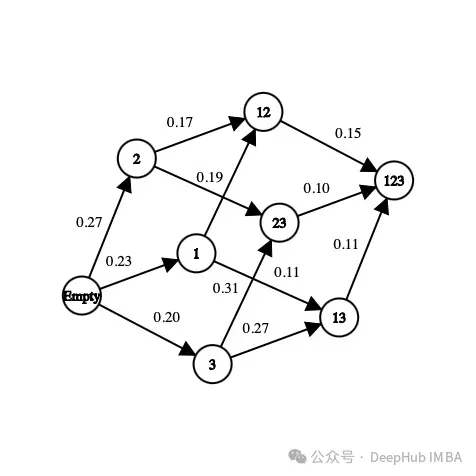
In the above image, each feature is mapped to a number ("Age" is 1, "Gender" is 2, "Height" is ” is 3). How do we choose the next state from the current state or how do we explore the environment?
We have to find the optimal method because if we explore all possible feature sets in a problem with 10 features, the number of states will be
10! + 2 = 3 628 802
这里的+2是因为考虑一个空状态和一个包含所有可能特征的状态。我们不可能在每个状态下都训练一个模型,这是不可能完成的,而且这只是有10个特征,如果有100个特征那基本上就是无解了。
但是在强化学习方法中,我们不需要在所有的状态下都去训练一个模型,我们要为这个问题确定一些停止条件,比如从当前状态随机选择下一个动作,概率为epsilon(介于0和1之间,通常在0.2左右),否则选择使函数最大化的动作。对于特征选择是每个特征对模型精度带来的奖励的平均值。
这里的贪心算法包含两个步骤:
1、以概率为epsilon,我们在当前状态的可能邻居中随机选择下一个状态
2、选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了减少时间复杂度,可以初始化了一个包含每个特征值的列表。每当选择一个特性时,此列表就会更新。使用以下公式,更新是非常理想的:
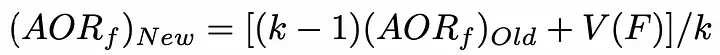
AORf:特征“f”带来的奖励的平均值
K: f被选中的次数
V(F):特征集合F的状态值(为了简单描述,本文不详细介绍)
所以我们就找出哪个特征给模型带来了最高的准确性。这就是为什么我们需要浏览不同的状态,在在许多不同的环境中评估模型特征的最全局准确值。
因为目标是最小化算法访问的状态数,所以我们访问的未访问过的状态越少,需要用不同特征集训练的模型数量就越少。因为从时间和计算能力的角度来看,训练模型以获得精度是最昂贵方法,我们要尽量减少训练的次数。
最后在任何情况下,算法都会停止在最终状态(包含所有特征的集合)而我们希望避免达到这种状态,因为用它来训练模型是最昂贵的。
上面就是我们针对于特征选择的强化学习描述,下面我们将详细介绍在python中的实现。
有一个python库可以让我们直接解决这个问题。但是首先我们先准备数据
我们直接使用UCI机器学习库中的数据:
#Get the pandas DataFrame from the csv file (15 features, 690 rows) australian_data = pd.read_csv('australian_data.csv', header=None) #DataFrame with the features X = australian_data.drop(14, axis=1) #DataFrame with the labels y = australian_data[14]然后安装我们用到的库
pip install FSRLearning
直接导入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL类就可以创建一个特性选择器。我们需要以下的参数
feature_number (integer): DataFrame X中的特性数量
feature_structure (dictionary):用于图实现的字典
eps (float [0;1]):随机选择下一状态的概率,0为贪婪算法,1为随机算法
alpha (float [0;1]):控制更新速率,0表示不更新状态,1表示经常更新状态
gamma (float[0,1]):下一状态观察的调节因子,0为近视行为状态,1为远视行为
nb_iter (int):遍历图的序列数
starting_state (" empty "或" random "):如果" empty ",则算法从空状态开始,如果" random ",则算法从图中的随机状态开始
所有参数都可以机型调节,但对于大多数问题来说,迭代大约100次就可以了,而epsilon值在0.2左右通常就足够了。起始状态对于更有效地浏览图形很有用,但它非常依赖于数据集,两个值都可以测试。
我们可以用下面的代码简单地初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
与大多数ML库相同,训练算法非常简单:
results = fsrl_obj.fit_predict(X, y)
下面是输出的一个例子:
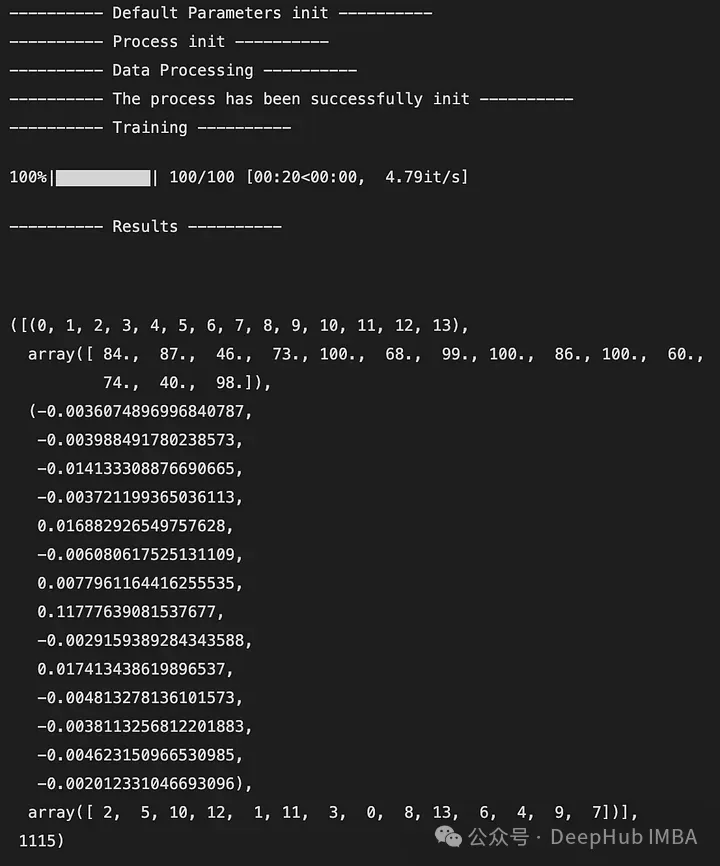
输出是一个5元组,如下所示:
DataFrame X中特性的索引(类似于映射)
特征被观察的次数
所有迭代后特征带来的奖励的平均值
从最不重要到最重要的特征排序(这里2是最不重要的特征,7是最重要的特征)
全局访问的状态数
还可以与Scikit-Learn的RFE选择器进行比较。它将X, y和选择器的结果作为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在RFE和FSRLearning的全局度量的每一步选择之后的结果。它还输出模型精度的可视化比较,其中x轴表示所选特征的数量,y轴表示精度。两条水平线是每种方法的准确度中值。
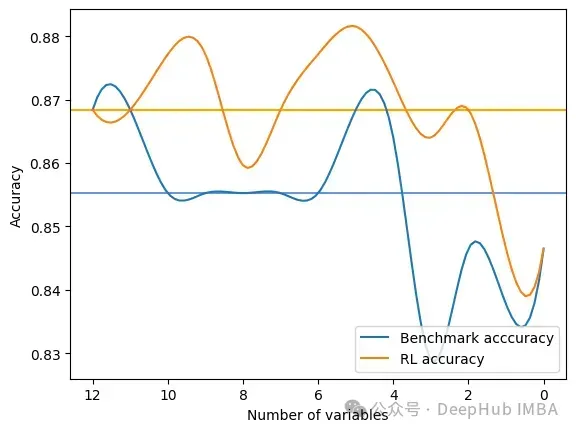
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909 Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579 Probability to get a set of variable with a better metric than RFE : 1.0 Area between the two curves : 0.17105263157894512
可以看到RL方法总是为模型提供比RFE更好的特征集。
另一个有趣的方法是get_plot_ratio_exploration。它绘制了一个图,比较一个精确迭代序列中已经访问节点和访问节点的数量。
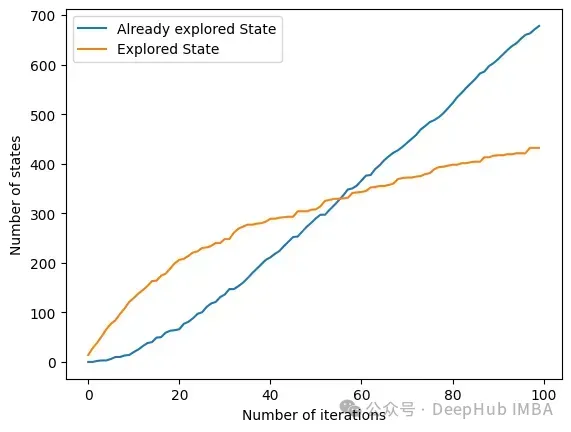
由于设置了停止条件,算法的时间复杂度呈指数级降低。即使特征的数量很大,收敛性也会很快被发现。下面的图表示一定大小的集合被访问的次数。
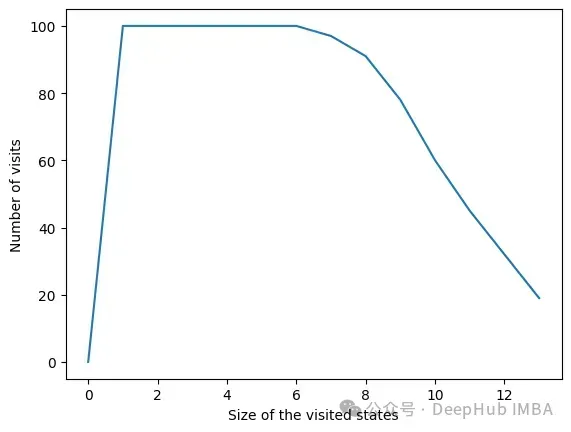
在所有迭代中,算法访问包含6个或更少变量的状态。在6个变量之外,我们可以看到达到的状态数量正在减少。这是一个很好的行为,因为用小的特征集训练模型比用大的特征集训练模型要快。
我们可以看到RL方法对于最大化模型的度量是非常有效的。它总是很快地收敛到一个有趣的特性子集。该方法在使用FSRLearning库的ML项目中非常容易和快速地实现。
The above is the detailed content of Feature selection via reinforcement learning strategies. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



