84669 人学习
152542 人学习
20005 人学习
5487 人学习
7821 人学习
359900 人学习
3350 人学习
180660 人学习
48569 人学习
18603 人学习
40936 人学习
1549 人学习
1183 人学习
32909 人学习
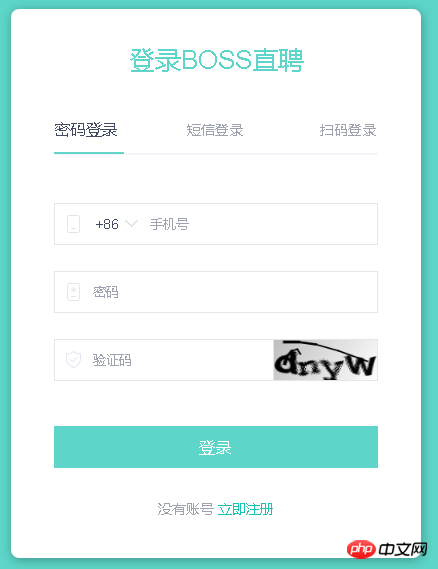
最近想用Python写个爬虫去抓取一些东西,但是碰到个问题,就是验证码不知道该如何处理。现在验证码一般有两种,一种是简单的,比如下面这种纯字符型的:
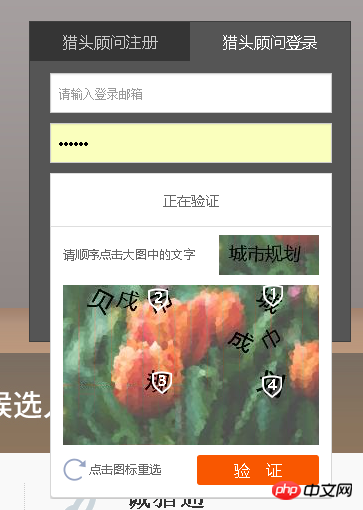
另外一种就是出来一些特定字符,需要按顺序点击的:
我看有的人说可以获取浏览器cookies写到程序里就直接通过验证了,有的说这个涉及到机器学习方面的东西。由于我个人以前没接触过这方面东西,所以不知道从何处入手,想问下要处理这种验证码的话,一般该如何处理? 有没有这方面合适的书推荐下啊……
走同样的路,发现不同的人生
这个本身用验证码技术就是防止爬虫之类的网络程序的,我所知道的破解验证码就是用人工智能的图像识别那块,好像有类似的函数可用,但是准确率都不会太高的
验证码问题,一可以转到专业服务商提供的API(他们用机器学习或者人工),如优优图,二是自己写验证码识别程序,提供一个项目供参考:https://github.com/luyishisi/...
有一种方案是在浏览器手动登陆然后把cookies提取出来直接在爬虫里包在请求里发出去。
图片一好处理,验证码就是张图片,通过图片处理可以获取验证码(ocr技术);图片二比较麻烦,如果用第一种方法的话,它的数字覆盖在文字上面了,在获取图片内容的时候难度比较大,第二种方法我没有什么好方法,希望有这方面经验的同学帮忙解答一下
验证码就是用来反制机器和爬虫的,如果验证码能让你的自动化爬虫轻松绕过,那还能叫验证码么?楼主还是先搞清楚验证码是个怎么机制,再来看看是否真如你想象中能够轻松绕过.总而言之,除非人家网站的验证码实现有漏洞,否则你是无法绕过验证码机制的,你只能识别出验证码上的文字,比如OCR(Optical Character Recognition)技术就是用来解决这个问题的.OCR是指电子设备(如扫描仪)检查纸上打印的字符.通过检测暗/亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程.
验证码识别基本步骤:1.预处理2.灰度化3.二值化4.去噪5.分割6.识别
总而言之,验证码识别门槛高,成本也高,避无可避.比如下图,验证码东倒西歪,还重叠,识别起来有难度.
可以用一个验证码服务像是我在用的9eu。
最省事的方式就是把cookie拿出来写在代码里,不过cookie是有时效性的
应对复杂的验证码,比较高效省时的方法应是对接到打码平台,交由他们的人工处理。


































这个本身用验证码技术就是防止爬虫之类的网络程序的,我所知道的破解验证码就是用人工智能的图像识别那块,好像有类似的函数可用,但是准确率都不会太高的
验证码问题,一可以转到专业服务商提供的API(他们用机器学习或者人工),如优优图,二是自己写验证码识别程序,提供一个项目供参考:https://github.com/luyishisi/...
有一种方案是在浏览器手动登陆然后把cookies提取出来直接在爬虫里包在请求里发出去。
图片一好处理,验证码就是张图片,通过图片处理可以获取验证码(ocr技术);
图片二比较麻烦,如果用第一种方法的话,它的数字覆盖在文字上面了,在获取图片内容的时候难度比较大,第二种方法我没有什么好方法,希望有这方面经验的同学帮忙解答一下
验证码就是用来反制机器和爬虫的,如果验证码能让你的自动化爬虫轻松绕过,那还能叫验证码么?楼主还是先搞清楚验证码是个怎么机制,再来看看是否真如你想象中能够轻松绕过.总而言之,除非人家网站的验证码实现有漏洞,否则你是无法绕过验证码机制的,你只能识别出验证码上的文字,比如OCR(Optical Character Recognition)技术就是用来解决这个问题的.OCR是指电子设备(如扫描仪)检查纸上打印的字符.通过检测暗/亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程.
验证码识别基本步骤:
1.预处理
2.灰度化
3.二值化
4.去噪
5.分割
6.识别
总而言之,验证码识别门槛高,成本也高,避无可避.
比如下图,验证码东倒西歪,还重叠,识别起来有难度.
可以用一个验证码服务像是我在用的9eu。
最省事的方式就是把cookie拿出来写在代码里,不过cookie是有时效性的
应对复杂的验证码,比较高效省时的方法应是对接到打码平台,交由他们的人工处理。