

我现在有很多pdf文件,现在假设这些pdf文件都是文字类型的,非扫描版图片格式的。虽然可以使用软件将pdf转为txt文本文件,但是由于pdf文件数量太多,大概有好几百篇,所以我也没有尝试使用操作软件的手工方式。这两天,尝试过使用itext,引用itextpdf-5.5.10.jar,代码来自于http://stackoverflow.com/ques... 的ExtractPageContent类,直接使用,正确运行,没有报错。但是转换之后的文本内容明显减少,好像也只能识别出英文数据,达不到要求。使用python的pdfminer3k进行转换,乱码。使用ghostscript转换,乱码。后来用了别人的源码(基于poppler),效果还行,但是由于pdf是两列的格式,它进行转换时候,是按照行来转换的,转换之后的格式不好,如下图所示。
转换之后的效果如图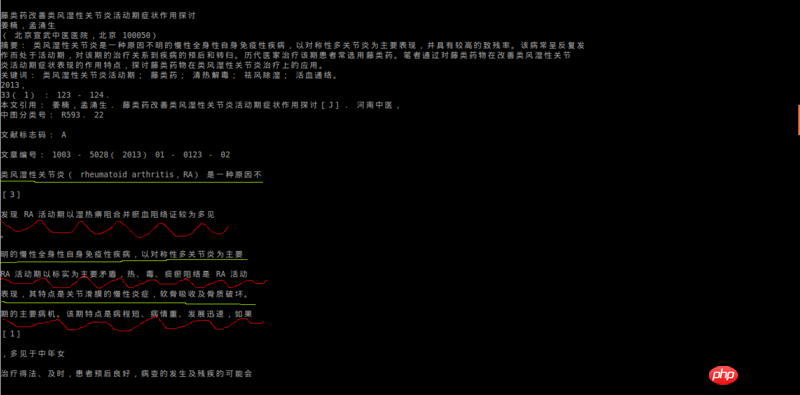
可以看到解析之后的文本明显错位了。
原来的pdf文件,百度网盘地址https://pan.baidu.com/s/1nvLQnLf
我现在还有一个问题是:pdf文件产生的方式有很多种,既可以使用latex编写产生,还可以使用word另存为,还可以使用编程语言如iReport等产生。而且这些格式如果不一样,那么会不会转换很麻烦?















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




光阴似箭催人老,日月如移越少年。