python – Verwenden Sie das Scrapy-Framework, um Baidu-Bilder zu crawlen und blockiert zu werden
给我你的怀抱2017-05-24 11:34:48
0
3
677
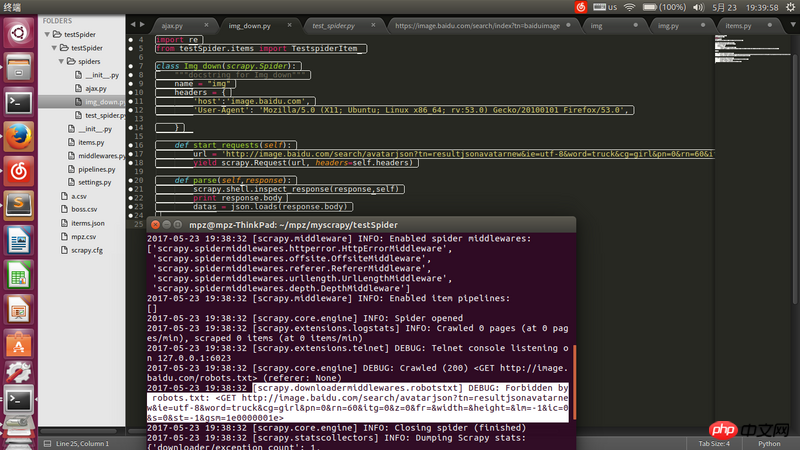
Die URL der Anforderungsadresse ist die über Firefox erhaltene JSON-Adresse. Sie kann mit einem Browser geöffnet werden, wurde jedoch beim Crawlen mit Scrapy gesperrt.
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




在
settings.py将ROBOTSTXT_OBEY = False试试。不要加hearders试试
赞成楼上,如果还会被墙。可采用scrapy+selenium+phantomjs的方式。