Insgesamt10000 bezogener Inhalt gefunden

Verstärkungslernmethode für die Vue-Komponentenkommunikation
Artikeleinführung:Verstärkungslernmethode für die Vue-Komponentenkommunikation In der Vue-Entwicklung ist die Komponentenkommunikation ein sehr wichtiges Thema. Es geht darum, wie man Daten zwischen mehreren Komponenten teilt, Ereignisse auslöst usw. Ein gängiger Ansatz besteht darin, Requisiten und $emit-Methoden für die Kommunikation zwischen übergeordneten und untergeordneten Komponenten zu verwenden. Diese einfache Kommunikationsmethode kann jedoch umständlich und schwierig zu warten sein, wenn Anwendungen größer werden und die Beziehungen zwischen Komponenten komplex werden. Reinforcement Learning ist ein Algorithmus, der Versuch-und-Irrtum- und Belohnungsmechanismen nutzt, um die Problemlösung zu optimieren. In der Komponentenkommunikation I
2023-07-17
Kommentar 0
1269

So erstellen Sie einen Reinforcement-Learning-Algorithmus mit PHP
Artikeleinführung:So erstellen Sie einen Reinforcement-Learning-Algorithmus mit PHP. Einführung: Reinforcement Learning ist eine maschinelle Lernmethode, die lernt, durch Interaktion mit der Umgebung optimale Entscheidungen zu treffen. In diesem Artikel stellen wir vor, wie man Reinforcement-Learning-Algorithmen mithilfe der Programmiersprache PHP erstellt, und stellen Codebeispiele bereit, um den Lesern ein besseres Verständnis zu erleichtern. 1. Was ist ein Reinforcement-Learning-Algorithmus? Der Reinforcement-Learning-Algorithmus ist eine maschinelle Lernmethode, die lernt, Entscheidungen zu treffen, indem sie das Feedback aus der Umgebung beobachtet. Im Gegensatz zu anderen Algorithmen für maschinelles Lernen basieren Reinforcement-Learning-Algorithmen nicht nur auf vorhandenen Daten
2023-07-31
Kommentar 0
703

Lernen Sie, eine Leiterplatte in 20 Minuten zusammenzubauen! Das Open-Source-SERL-Framework weist eine Erfolgsquote bei der Präzisionskontrolle von 100 % auf und ist dreimal schneller als Menschen
Artikeleinführung:Jetzt können Roboter Präzisionsaufgaben in der Fabriksteuerung erlernen. In den letzten Jahren wurden auf dem Gebiet der Lerntechnologie zur Verstärkung von Robotern erhebliche Fortschritte erzielt, z. B. beim Gehen im Vierfüßlerstand, beim Greifen, bei der geschickten Manipulation usw., die meisten davon beschränken sich jedoch auf die Labordemonstrationsphase. Die umfassende Anwendung der Robotic Reinforcement Learning-Technologie in tatsächlichen Produktionsumgebungen steht noch vor vielen Herausforderungen, was ihren Anwendungsbereich in realen Szenarien bis zu einem gewissen Grad einschränkt. Im Prozess der praktischen Anwendung der Reinforcement-Learning-Technologie ist es notwendig, mehrere komplexe Probleme zu überwinden, darunter die Einstellung des Belohnungsmechanismus, das Zurücksetzen der Umgebung, die Verbesserung der Probeneffizienz und die Gewährleistung der Aktionssicherheit. Branchenexperten betonen, dass die Lösung der vielen Probleme bei der tatsächlichen Implementierung der Reinforcement-Learning-Technologie ebenso wichtig ist wie die kontinuierliche Innovation des Algorithmus selbst. Vor dieser Herausforderung standen Forscher der University of California, Berkeley, der Stanford University, der University of Washington und
2024-02-21
Kommentar 0
1193

Die Trainingsgeschwindigkeit wird um 17 % erhöht. Das Open-Source-Forschungsframework für verstärktes Lernen unterstützt das Training mit einzelnen und mehreren Agenten.
Artikeleinführung:OpenRL ist ein PyTorch-basiertes Forschungsframework für verstärktes Lernen, das vom Team für verstärktes Lernen von Fourth Paradigm entwickelt wurde. Es unterstützt das Training von Einzelagenten, mehreren Agenten, natürlicher Sprache und anderen Aufgaben. OpenRL wird auf Basis von PyTorch entwickelt, mit dem Ziel, der Forschungsgemeinschaft für Reinforcement Learning eine benutzerfreundliche, flexible, effiziente und nachhaltig skalierbare Plattform bereitzustellen. Zu den derzeit von OpenRL unterstützten Funktionen gehören: eine gemeinsame Schnittstelle, die einfach zu verwenden ist und das Training mit einem oder mehreren Agenten unterstützt; ; unterstützt LSTM, GRU, Modelle wie Transformer unterstützen eine Vielzahl von Trainingsbeschleunigungen, wie zum Beispiel: automatisches gemischtes Präzisionstraining,
2023-05-11
Kommentar 0
1064

Xishanju-KI-Technikexperte Huang Hongbo: Praktische Integration von Verstärkungslernen und Verhaltensbäumen in Spielen
Artikeleinführung:Vom 6. bis 7. August 2022 findet wie geplant die AISummit Global Artificial Intelligence Technology Conference statt. Auf dem Unterforum „Artificial Intelligence Frontier Exploration“, das am Nachmittag des 7. stattfand, brachte Huang Hongbo, technischer Experte für künstliche Intelligenz in Xishanju, einen Themenvortrag zum Thema „Praktische Kombination von Verstärkungslernen und Verhaltensbäumen in Spielen“ und erläuterte dabei ausführlich die Auswirkungen der Verstärkung Lernen im Spielbereich. Huang Hongbo sagte, dass die Implementierung der Reinforcement-Learning-Technologie nicht darin besteht, den Algorithmus zu ändern, um ihn leistungsfähiger zu machen, sondern darin, Reinforcement-Learning-Technologie mit Deep Learning und Spielplanung zu kombinieren, um einen vollständigen Satz von Lösungen zu bilden und diese umzusetzen. Reinforcement Learning macht Spiele intelligenter. Die Implementierung von Reinforcement Learning in Spielen kann Spiele intelligenter und spielbarer machen.
2023-04-09
Kommentar 0
1822

Maschinelles Lernen: Top 19 Reinforcement Learning (RL)-Projekte auf Github
Artikeleinführung:Reinforcement Learning (RL) ist eine Methode des maschinellen Lernens, bei der Agenten durch Versuch und Irrtum lernen. Reinforcement-Learning-Algorithmen werden in vielen Bereichen eingesetzt, beispielsweise in der Gaming-, Robotik- und Finanzbranche. Das Ziel von RL besteht darin, eine Strategie zu finden, die die erwarteten langfristigen Renditen maximiert. Reinforcement-Learning-Algorithmen werden im Allgemeinen in zwei Kategorien unterteilt: modellbasiert und modellfrei. Modellbasierte Algorithmen nutzen Umgebungsmodelle, um optimale Handlungspfade zu planen. Dieser Ansatz basiert auf einer genauen Modellierung der Umgebung und der anschließenden Verwendung des Modells, um die Ergebnisse verschiedener Aktionen vorherzusagen. Im Gegensatz dazu lernen modellfreie Algorithmen direkt aus Interaktionen mit der Umgebung, ohne die Umgebung explizit zu modellieren. Diese Methode eignet sich besser für Situationen, in denen das Umgebungsmodell schwer zu erhalten oder ungenau ist. Im tatsächlichen Vergleich ist dies bei modellfreien Reinforcement-Learning-Algorithmen nicht der Fall
2024-03-19
Kommentar 0
929
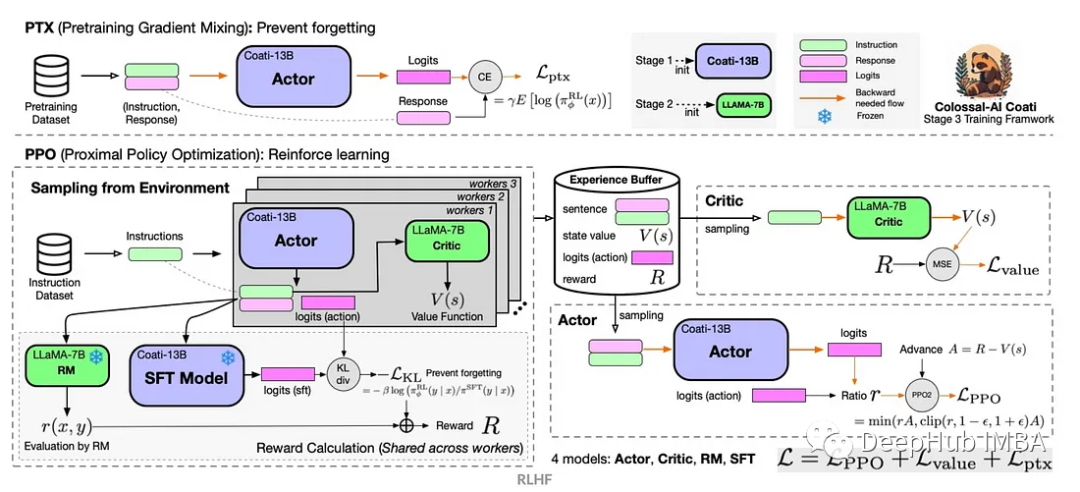
Tiefgreifendes Q-Learning-Verstärkungslernen mit der Roboterarmsimulation von Panda-Gym
Artikeleinführung:Reinforcement Learning (RL) ist eine Methode des maschinellen Lernens, die es einem Agenten ermöglicht, durch Versuch und Irrtum zu lernen, wie er sich in seiner Umgebung verhält. Agenten werden dafür belohnt oder bestraft, dass sie Maßnahmen ergreifen, die zu den gewünschten Ergebnissen führen. Im Laufe der Zeit lernt der Agent, Maßnahmen zu ergreifen, die seine erwartete Belohnung maximieren. RL-Agenten werden normalerweise mithilfe eines Markov-Entscheidungsprozesses (MDP) trainiert, einem mathematischen Rahmen zur Modellierung sequentieller Entscheidungsprobleme. MDP besteht aus vier Teilen: Zustand: eine Reihe möglicher Zustände der Umgebung. Aktion: Eine Reihe von Aktionen, die ein Agent ausführen kann. Übergangsfunktion: Eine Funktion, die die Wahrscheinlichkeit des Übergangs in einen neuen Zustand anhand des aktuellen Zustands und der aktuellen Aktion vorhersagt. Belohnungsfunktion: Eine Funktion, die dem Agenten für jede Conversion eine Belohnung zuweist. Das Ziel des Agenten besteht darin, eine Richtlinienfunktion zu erlernen.
2023-10-31
Kommentar 0
644

Eine Methode zur Optimierung von AB mithilfe des Lernens zur Verstärkung des Richtliniengradienten
Artikeleinführung:AB-Tests sind eine Technik, die in Online-Experimenten weit verbreitet ist. Sein Hauptzweck besteht darin, zwei oder mehr Versionen einer Seite oder Anwendung zu vergleichen, um festzustellen, welche Version bessere Geschäftsziele erreicht. Diese Ziele können Klickraten, Konversionsraten usw. sein. Im Gegensatz dazu handelt es sich beim Reinforcement Learning um eine Methode des maschinellen Lernens, die mithilfe von Trial-and-Error-Lernen Entscheidungsstrategien optimiert. Policy Gradient Reinforcement Learning ist eine spezielle Reinforcement-Learning-Methode, die darauf abzielt, die kumulativen Belohnungen durch das Erlernen optimaler Richtlinien zu maximieren. Beide haben unterschiedliche Anwendungen bei der Optimierung von Geschäftszielen. Beim AB-Testen betrachten wir unterschiedliche Seitenversionen als unterschiedliche Aktionen und Geschäftsziele können als wichtige Indikatoren für Belohnungssignale betrachtet werden. Um maximale Geschäftsziele zu erreichen, müssen wir eine Strategie entwerfen, die wählbar ist
2024-01-24
Kommentar 0
991
Vom Transformer zum Diffusionsmodell: Erfahren Sie in einem Artikel mehr über Methoden des verstärkenden Lernens, die auf der Sequenzmodellierung basieren
Artikeleinführung:Groß angelegte generative Modelle haben in den letzten zwei Jahren große Durchbrüche bei der Verarbeitung natürlicher Sprache und sogar bei der Computervision gebracht. In jüngster Zeit hat sich dieser Trend auch auf das Verstärkungslernen ausgewirkt, insbesondere auf das Offline-Verstärkungslernen (Offline-RL), wie z. B. Decision Transformer (DT)[1], Trajectory Transformer (TT)[2], Gato[3], Diffuser[4] usw Diese Methode betrachtet Reinforcement-Learning-Daten (einschließlich Status, Aktion, Belohnung und Return-to-Go) als eine Reihe destrukturierter Sequenzdaten und modelliert diese Sequenzdaten als Kernaufgabe des Lernens. Diese Modelle können alle überwachte oder selbstüberwachte Lernmethoden verwenden
2023-04-14
Kommentar 0
959

Klettern, Springen und das Überqueren enger Lücken – Open-Source-Lernstrategien zur Verstärkung ermöglichen es Roboterhunden, Parkour zu machen
Artikeleinführung:Parkour ist eine Extremsportart und stellt eine große Herausforderung für Roboter dar, insbesondere für vierbeinige Roboterhunde, die in komplexen Umgebungen schnell verschiedene Hindernisse überwinden müssen. Einige Studien haben versucht, Referenztierdaten oder komplexe Belohnungen zu verwenden, aber diese Ansätze erzeugen Parkour-Fähigkeiten, die entweder vielfältig, aber blind sind, oder visionsbasiert, aber szenenspezifisch. Beim autonomen Parkour müssen Roboter jedoch visionsbasierte und vielfältige allgemeine Fähigkeiten erlernen, um verschiedene Szenarien wahrzunehmen und schnell zu reagieren. Kürzlich ging ein Video eines Roboterhund-Parkours viral. Der Roboterhund im Video überwindet in verschiedenen Szenarien schnell verschiedene Hindernisse. Wenn Sie beispielsweise durch die Lücke unter der Eisenplatte gehen, auf eine Holzkiste klettern und dann auf eine andere Holzkiste springen, sind eine Reihe von Aktionen reibungslos und reibungslos: Diese Aktionsreihe zeigt, dass der Roboterhund das Krabbeln, Klettern und Klettern beherrscht auf dem Boden kriechen.
2023-09-20
Kommentar 0
1091

Leitfaden zur Integration künstlicher Intelligenztechnologie in die C++-Grafikprogrammierung
Artikeleinführung:Durch die Integration der Technologie der künstlichen Intelligenz in die C++-Grafikprogrammierung können Entwickler intelligentere und interaktivere Anwendungen erstellen. Dazu gehören Bildklassifizierung, Objekterkennung, Bildgenerierung, Spiel-KI, Pfadplanung, Szenengenerierung und andere Funktionen. Künstliche Intelligenztechnologien wie neuronale Netze, Reinforcement Learning und generative kontradiktorische Netze können über Frameworks wie TensorFlow, OpenAIGym und PyTorch in C++ integriert werden, um diese Funktionen zu realisieren.
2024-06-02
Kommentar 0
348

Was sind die Reinforcement-Learning-Algorithmen in Python?
Artikeleinführung:Mit der Entwicklung der Technologie der künstlichen Intelligenz wurde Reinforcement Learning als wichtige Technologie der künstlichen Intelligenz in vielen Bereichen wie Steuerungssystemen, Spielen usw. weit verbreitet. Als beliebte Programmiersprache bietet Python auch die Implementierung vieler Reinforcement-Learning-Algorithmen. In diesem Artikel werden häufig verwendete Reinforcement-Learning-Algorithmen und ihre Eigenschaften in Python vorgestellt. Q-Learning ist ein verstärkender Lernalgorithmus, der auf einer Wertfunktion basiert. Er leitet Verhaltensstrategien durch das Erlernen einer Wertfunktion und ermöglicht es dem Agenten, in der Umgebung auszuwählen.
2023-06-04
Kommentar 0
1408

Eine einzelne GPU realisiert 20-Hz-Online-Entscheidungsfindung und Interpretation der neuesten effizienten Flugbahnplanungsmethode basierend auf einem Sequenzgenerierungsmodell
Artikeleinführung:Zuvor haben wir die Anwendung von Sequenzmodellierungsmethoden basierend auf dem Transformer- und Diffusionsmodell beim Reinforcement Learning eingeführt, insbesondere im Bereich der Offline-Kontinuitätssteuerung. Unter ihnen sind Trajectory Transformer (TT) und Diffusser modellbasierte Planungsalgorithmen. Sie zeigen eine sehr präzise Flugbahnvorhersage und eine gute Flexibilität, aber die Entscheidungsverzögerung ist relativ hoch. Insbesondere diskretisiert TT jede Dimension unabhängig als Symbol in der Sequenz, wodurch die gesamte Sequenz sehr lang wird und der Zeitaufwand für die Sequenzgenerierung mit der Dimension von Zuständen und Aktionen schnell zunimmt.
2023-04-13
Kommentar 0
1641

Gemeinsam produziert von Qingbei! Eine Umfrage zum Verständnis der Besonderheiten des „Transformer+Reinforcement Learning'
Artikeleinführung:Seit seiner Veröffentlichung hat sich das Transformer-Modell schnell zu einer gängigen neuronalen Architektur in überwachten Lernumgebungen in den Bereichen Verarbeitung natürlicher Sprache und Computer Vision entwickelt. Obwohl die Begeisterung für Transformer begonnen hat, den Bereich des verstärkenden Lernens zu durchdringen, ist die aktuelle Kombination von Transformer und verstärkendem Lernen aufgrund der Eigenschaften von RL selbst, wie der Notwendigkeit einzigartiger Funktionen, des Architekturdesigns usw., nicht reibungslos. und seinem Entwicklungspfad fehlen relevante Papiere, um eine gründliche Analyse durchzuführen. Kürzlich haben Forscher der Tsinghua-Universität, der Peking-Universität und Tencent gemeinsam einen Forschungsbericht zur Kombination von Transformer und Reinforcement Learning veröffentlicht, in dem sie systematisch die Motivation und den Entwicklungsprozess der Verwendung von Transformer beim Reinforcement Learning überprüfen. Papier
2023-04-13
Kommentar 0
1108

Nanyang Polytechnic veröffentlicht den quantitativen Handelsmaster TradeMaster, der 15 Arten von Reinforcement-Learning-Algorithmen abdeckt
Artikeleinführung:Vor kurzem hat die Familie der quantitativen Plattformen ein neues Mitglied begrüßt, eine Open-Source-Plattform, die auf Reinforcement Learning basiert: TradeMaster – Trading Master. TradeMaster wurde von der Nanyang Technological University entwickelt und ist eine einheitliche, durchgängige und benutzerfreundliche quantitative Handelsplattform, die vier große Finanzmärkte, sechs große Handelsszenarien, 15 Reinforcement-Learning-Algorithmen und eine Reihe visueller Bewertungstools abdeckt! Plattformadresse: https://github.com/TradeMaster-NTU/TradeMaster Hintergrund Einführung In den letzten Jahren nimmt die Technologie der künstlichen Intelligenz eine immer wichtigere Position in quantitativen Handelsstrategien ein. Aufgrund seiner herausragenden Entscheidungsfähigkeit in komplexen Umgebungen wird die Reinforcement-Learning-Technologie eingesetzt
2023-04-11
Kommentar 0
1073
KI-Neugier tötet nicht nur die Katze! Der neue Reinforcement-Learning-Algorithmus des MIT, diesmal ist der Agent „schwierig und leicht, alles zu ertragen'
Artikeleinführung:Jeder ist schon einmal auf ein uraltes Problem gestoßen. Sie versuchen, ein Restaurant auszuwählen, in dem Sie an einem Freitagabend essen möchten, haben aber keine Reservierung. Sollten Sie in Ihrem Lieblingsrestaurant, in dem es viele Menschen gibt, in der Schlange stehen oder ein neues Restaurant ausprobieren, in der Hoffnung, noch leckerere Überraschungen zu entdecken? Letzteres kann zwar zu Überraschungen führen, aber ein solches aus Neugier getriebenes Verhalten birgt Risiken: Das Essen in dem neuen Restaurant, das Sie probieren, könnte sogar noch schmackhafter sein. Neugier ist die treibende Kraft für KI, die Welt zu erkunden, und es gibt unzählige Beispiele – autonome Navigation, Roboter-Entscheidungsfindung, optimierte Erkennungsergebnisse usw. In einigen Fällen nutzen Maschinen „Reinforcement Learning“, um ein Ziel zu erreichen, bei dem der KI-Agent wiederholt lernt, indem er für gutes Verhalten belohnt und für schlechtes Verhalten bestraft wird. Genauso wie wenn Menschen ein Restaurant auswählen
2023-04-13
Kommentar 0
990

Die Blackbox von AlphaZero ist geöffnet! DeepMind-Artikel in PNAS veröffentlicht
Artikeleinführung:Schach war schon immer ein Testgelände für KI. Vor 70 Jahren stellte Alan Turing die Hypothese auf, dass es möglich sei, eine Schachspielmaschine zu bauen, die selbstständig lernt und sich aus eigener Erfahrung kontinuierlich verbessert. „Deep Blue“, das im letzten Jahrhundert erschien, besiegte erstmals Menschen, verließ sich jedoch auf Experten, um menschliches Schachwissen zu kodieren. AlphaZero, das 2017 geboren wurde, verwirklichte Turings Vermutung als eine neuronale Netzwerk-gesteuerte Verstärkungslernmaschine. AlphaZero muss keine von Hand entwickelten Heuristiken verwenden oder Menschen beim Schachspielen zusehen, sondern wird vollständig durch das Spielen gegen sich selbst trainiert. Erlernt es also wirklich menschliche Konzepte über Schach? Dies ist ein Problem der Interpretierbarkeit neuronaler Netze. In dieser Hinsicht ist AlphaZero’s
2023-04-12
Kommentar 0
1382
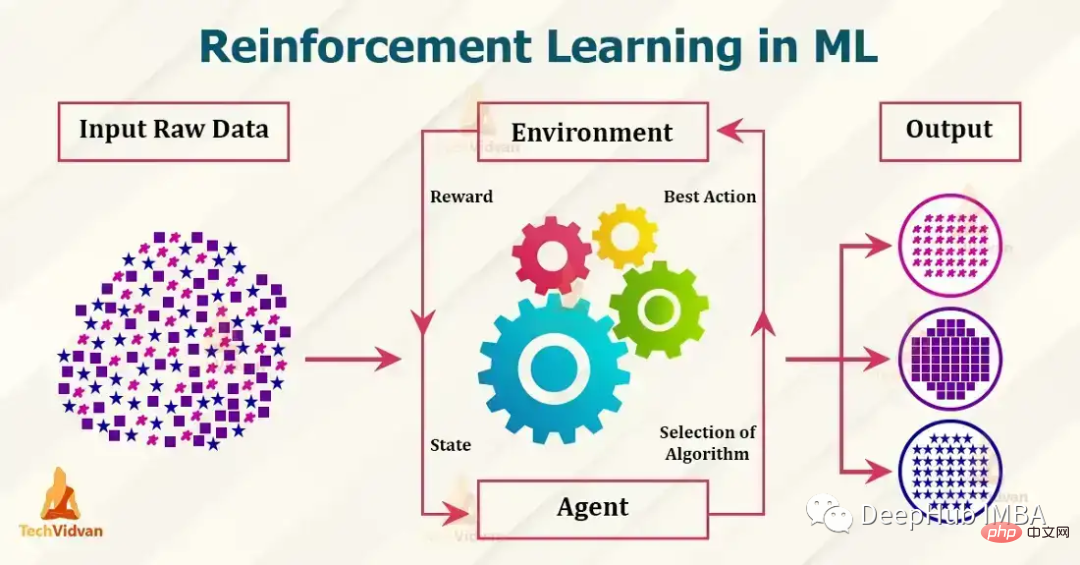
Sieben beliebte Reinforcement-Learning-Algorithmen und Code-Implementierungen
Artikeleinführung:Zu den derzeit beliebten Reinforcement-Learning-Algorithmen gehören Q-Learning, SARSA, DDPG, A2C, PPO, DQN und TRPO. Diese Algorithmen wurden in verschiedenen Anwendungen wie Spielen, Robotik und Entscheidungsfindung eingesetzt und werden ständig weiterentwickelt und verbessert. In diesem Artikel geben wir eine kurze Einführung in sie. 1. Q-LearningQ-Learning: Q-Learning ist ein modellfreier, nicht strategischer Verstärkungslernalgorithmus. Es schätzt die optimale Aktionswertfunktion mithilfe der Bellman-Gleichung, die den geschätzten Wert für ein bestimmtes Zustands-Aktionspaar iterativ aktualisiert. Q-Learning ist bekannt für seine Einfachheit und die Fähigkeit, große kontinuierliche Zustandsräume zu verarbeiten.
2023-04-11
Kommentar 0
1628

Von Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens
Artikeleinführung:Wenn es um Reinforcement Learning geht, steigt bei vielen Forschern der Adrenalinspiegel unkontrolliert an! Es spielt eine sehr wichtige Rolle in Spiel-KI-Systemen, modernen Robotern, Chip-Design-Systemen und anderen Anwendungen. Es gibt viele verschiedene Arten von Reinforcement-Learning-Algorithmen, sie werden jedoch hauptsächlich in zwei Kategorien unterteilt: „modellbasiert“ und „modellfrei“. In einem Gespräch mit TechTalks diskutierte der Neurowissenschaftler und Autor von „The Birth of Intelligence“ Daeyeol Lee verschiedene Modelle des verstärkenden Lernens bei Menschen und Tieren, künstliche Intelligenz und natürliche Intelligenz sowie zukünftige Forschungsrichtungen. Modellfreies verstärkendes Lernen Im späten 19. Jahrhundert wurde das vom Psychologen Edward Thorndike vorgeschlagene „Gesetz der Wirkung“ zur Grundlage des modellfreien verstärkenden Lernens. Th
2023-05-09
Kommentar 0
874

