Insgesamt10000 bezogener Inhalt gefunden
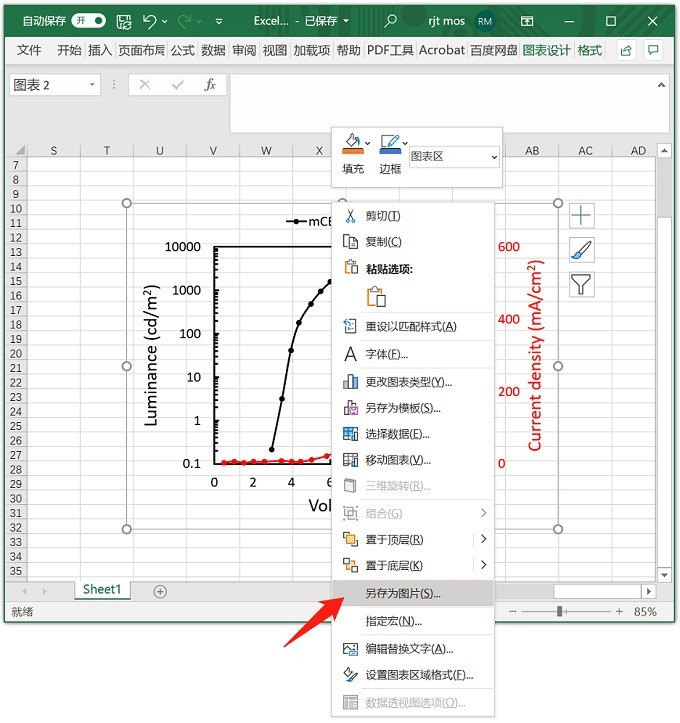
So exportieren Sie hochauflösende Bilder aus Excel-Tabellendaten_So exportieren Sie hochauflösende Bilder aus Excel-Tabellendaten
Artikeleinführung:Schritt 1: Klicken Sie mit der rechten Maustaste auf das Bild in Excel und klicken Sie auf [Als Bild speichern]. Schritt 2: Wählen Sie den Speichertyp: TIFF-Format. Schritt 3: Das gespeicherte Bild ist standardmäßig auf 330 dpi eingestellt, die Kapazität beträgt 330 KB und die Auflösung ist bereits sehr gut. Schritt 4: Wenn Sie ein Bild mit höherer Auflösung oder im Vektorformat wünschen, können Sie es über PPT im PDF-Format speichern und es dann mit PS in das PDF-Format konvertieren.
2024-04-24
Kommentar 0
1335

Reverse-Engineering-Datenbankmodelldiagramm in Visio2010
Artikeleinführung:1. Erstellen Sie ein neues Datenbankmodelldiagramm in Visio. Öffnen Sie Visio2010, Datei->Neu->Datenbank->Datenbankmodelldiagramm. Nach dem Erstellen des Datenbankmodelldiagramms gibt es in der Menüleiste einen zusätzlichen Menüpunkt [Datenbank]. Schauen Sie sich das Bild unten an. Es gibt einen zusätzlichen Datenbankpunkt in der Menüleiste 2. Reverse Engineering-Menüpunkt Datenbank – „Reverse Engineering“. Starten Sie den Reverse-Engineering-Assistenten und nehmen Sie die Reverse-Engineering-Einstellungen Schritt für Schritt vor. 2.1. Stellen Sie eine Verbindung mit der Datenbank her. Der Typ des ausgewählten Visio-Treibers bestimmt, welche Datenbanktypen verbunden werden können und welche Optionen verfügbar sind. Die Datenquelle gibt den Datenbankstandort und die Verbindungsinformationen an. Hier wählen wir den Visio-Treiber als MicrosoftSqlServer und die Datenquelle als neu erstellte BASICDATA. 2.2
2024-06-02
Kommentar 0
1149
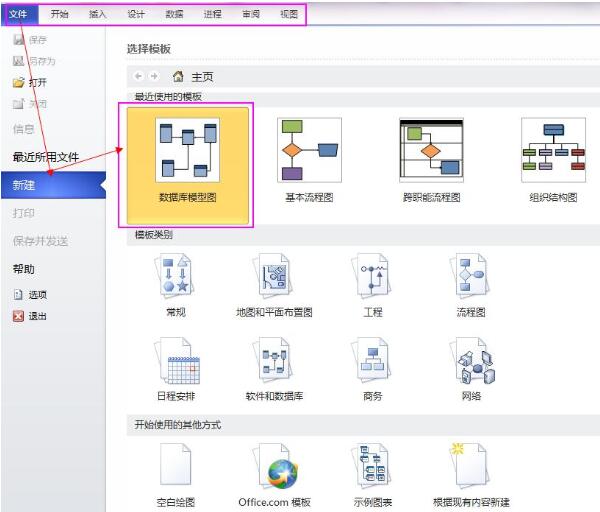
Detaillierte Methode zum Erstellen eines Datenbankmodelldiagramms in Visio2010
Artikeleinführung:1. Erstellen Sie ein neues Datenbankmodelldiagramm in Visio. Öffnen Sie Visio2010, Datei->Neu->Datenbank->Datenbankmodelldiagramm. Nach dem Erstellen des Datenbankmodelldiagramms gibt es in der Menüleiste einen zusätzlichen Menüpunkt [Datenbank]. Schauen Sie sich das Bild unten an. In der Menüleiste gibt es ein zusätzliches Datenbankelement. 2. Zeichnen Sie jede in der Datenbank erstellte Tabelle, Ansicht usw. Wählen Sie den Zeichnungsstatus aus Klicken Sie auf das Zeichnungsmodell [Entity] und ziehen Sie es mit gedrückter linker Maustaste direkt in den Zeichenbereich. Die nächste Hauptarbeit besteht darin, die Eigenschaften der Tabelle festzulegen. Sehen Sie sich die Eigenschafteneinstellungen unten im Hauptfenster des Programms an. Wählen Sie nun in der Kategorie links den physischen Namen und den konzeptionellen Namen aus Namen sind inkonsistent
2024-06-12
Kommentar 0
362

ICLR 2024 Spotlight |. NoiseDiffusion: Korrigiert das Rauschen des Diffusionsmodells und verbessert die Interpolationsbildqualität
Artikeleinführung:Autor|PengfeiZheng Unit|USTC,HKBUTMLRGroup In den letzten Jahren hat die rasante Entwicklung der generativen KI auffälligen Bereichen wie der Text-zu-Bild-Generierung und der Videogenerierung starke Impulse verliehen. Der Kern dieser Techniken liegt in der Anwendung von Diffusionsmodellen. Das Diffusionsmodell wandelt das Bild zunächst schrittweise in Gaußsches Rauschen um, indem es einen Vorwärtsprozess definiert, der kontinuierlich Rauschen hinzufügt, und entrauscht dann das Gaußsche Rauschen schrittweise durch einen umgekehrten Prozess und wandelt es in ein klares Bild um, um echte Proben zu erhalten. Das gewöhnliche Diffusionsdifferenzialmodell wird zum Interpolieren der Werte der generierten Bilder verwendet, was ein großes Anwendungspotenzial bei der Generierung von Videos und einigen Werbekreativen bietet. Allerdings ist uns aufgefallen, dass bei der Anwendung dieser Methode auf natürliche Bilder die interpolierten Bildeffekte oft unbefriedigend sind. existieren
2024-05-06
Kommentar 0
1076

Wie läuft beim Datenbankdesign die Konvertierung eines ER-Diagramms in ein relationales Datenmodell ab?
Artikeleinführung:Beim Datenbankentwurf gehört der Prozess der Konvertierung von E-R-Diagrammen in relationale Datenmodelle zur „logischen Entwurfsphase“. E-R-Diagramme werden verwendet, um konzeptionelle Modelle der realen Welt zu beschreiben. Die Hauptarbeit der logischen Entwurfsphase besteht darin, das konzeptionelle Datenmodell der realen Welt in ein logisches Modell der Datenbank umzuwandeln, das heißt, an die unterstützten logischen Daten anzupassen ein spezifisches Datenbankverwaltungssystem.
2021-05-07
Kommentar 0
30414
Detaillierte Methode zum Anzeigen des Datenbankmodelldiagramms in Visio
Artikeleinführung:1. Öffnen Sie Visio, wie unten gezeigt. 2. Klicken Sie auf Datei, Neu, Software und Datenbank, wie unten gezeigt. 3. Wählen Sie das Datenbankmodelldiagramm aus, klicken Sie auf Erstellen und erstellen Sie dann erfolgreich eine vsd-Datei. Wie nachfolgend dargestellt. 4. Wählen Sie das Werkzeug auf der linken Seite aus und ziehen Sie die Entität wie unten gezeigt auf die Seite. 5. Bearbeiten Sie unten auf der Seite die relevanten Informationen der Entität (d. h. Tabelle), wie unten gezeigt. 6. Klicken Sie auf die Spalte. Hier können Sie den Schlüsselnamen und das Datenformat festlegen, wie unten gezeigt. 7. Aktivieren Sie pk, um den Primärschlüssel einer Tabelle festzulegen, wie unten gezeigt.
2024-06-11
Kommentar 0
1083
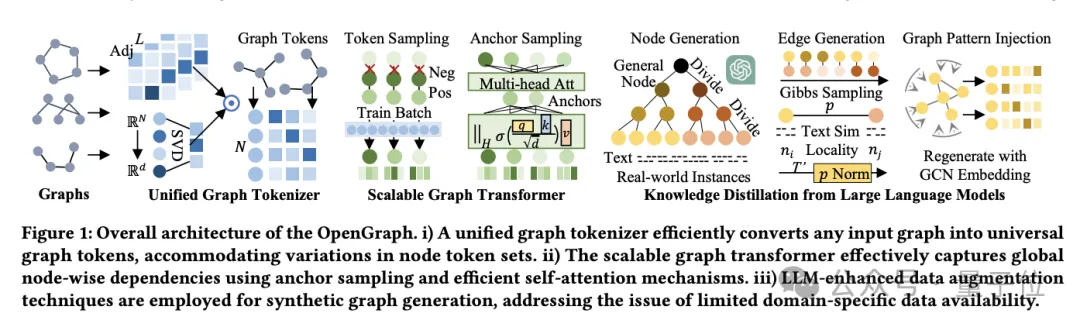
HKUs großes Open-Source-Graph-Grundmodell OpenGraph: starke Generalisierungsfähigkeit, Vorwärtsausbreitung zur Vorhersage neuer Daten
Artikeleinführung:Es gibt eine neue Möglichkeit, das Problem des Datenmangels im Bereich des Graphenlernens zu lindern! OpenGraph, ein grundlegendes graphbasiertes Modell, das speziell für die Zero-Shot-Vorhersage für eine Vielzahl von Graphdatensätzen entwickelt wurde. Das Team von Chao Huang, Leiter des Data Intelligence Laboratory an der Universität Hongkong, schlug außerdem Verbesserungs- und Anpassungstechniken für das Modell vor, um die Anpassungsfähigkeit des Modells an neue Aufgaben zu verbessern. Derzeit wurde diese Arbeit auf GitHub veröffentlicht. Diese Arbeit stellt Techniken zur Datenerweiterung vor und konzentriert sich auf eine eingehende Untersuchung von Strategien zur Verbesserung der Generalisierungsfähigkeit grafischer Modelle (insbesondere, wenn erhebliche Unterschiede in Trainings- und Testdaten bestehen). OpenGraph ist ein allgemeines Diagrammstrukturmodell, das eine Vorwärtsausbreitung durch Ausbreitungsvorhersage durchführt, um eine Vorhersage neuer Daten ohne Stichprobe zu erreichen. Um ihre Ziele zu erreichen, muss das Team
2024-05-09
Kommentar 0
333

Wie kann mit Hilfe des SectionReader-Moduls von Go das Lesen und Schreiben großer Datenbankdaten effizient gehandhabt werden?
Artikeleinführung:Wie kann mit Hilfe des SectionReader-Moduls von Go das Lesen und Schreiben großer Datenbankdaten effizient gehandhabt werden? Datenbanken sind ein unverzichtbarer Bestandteil moderner Anwendungen und das Lesen und Schreiben von Daten in großen Datenbanken ist ein sehr zeitaufwändiger Vorgang. Um die Effizienz zu verbessern, können wir das SectionReader-Modul der Go-Sprache verwenden, um diese Vorgänge abzuwickeln. SectionReader ist ein Typ in der Go-Standardbibliothek, der io.ReaderAt, io.Writ implementiert
2023-07-21
Kommentar 0
887
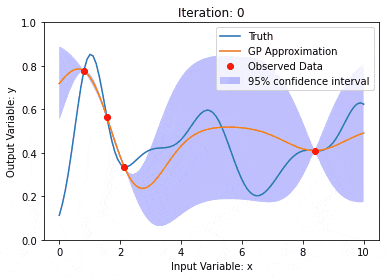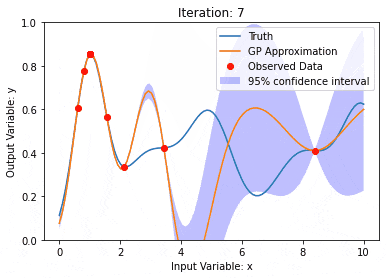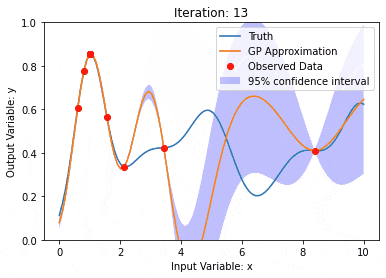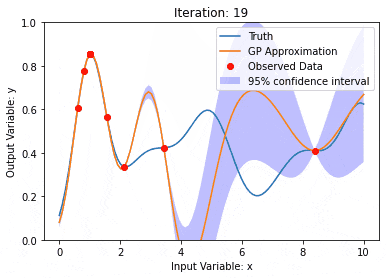
Datenmodellierung mit Kernel Model Gaußian Processes (KMGPs)
Artikeleinführung:Kernel Model Gaussian Processes (KMGPs) sind hochentwickelte Werkzeuge zur Bewältigung der Komplexität verschiedener Datensätze. Es erweitert das Konzept traditioneller Gaußscher Prozesse um Kernelfunktionen. In diesem Artikel werden die theoretischen Grundlagen, praktischen Anwendungen und Herausforderungen von KMGPs ausführlich erörtert. Der Gaußsche Prozess des Kernelmodells ist eine Erweiterung des traditionellen Gaußschen Prozesses und wird beim maschinellen Lernen und in der Statistik verwendet. Bevor Sie kmgp verstehen, müssen Sie die Grundkenntnisse des Gaußschen Prozesses beherrschen und dann die Rolle des Kernelmodells verstehen. Gaußsche Prozesse (GPs) Gaußsche Prozesse sind Sätze von Zufallsvariablen mit einer endlichen Anzahl von Variablen, die durch die Gaußsche Verteilung gemeinsam verteilt werden, und werden zur Definition von Funktionswahrscheinlichkeitsverteilungen verwendet. Gaußsche Prozesse werden häufig bei Regressions- und Klassifizierungsaufgaben beim maschinellen Lernen verwendet und können zur Anpassung der Wahrscheinlichkeitsverteilung von Daten verwendet werden. Ein wichtiges Merkmal von Gaußschen Prozessen ist ihre Fähigkeit, Unsicherheitsschätzungen und -vorhersagen zu liefern
2024-01-30
Kommentar 0
945

Erweitertes Tutorial zu Vue und ECharts4Taro3: So implementieren Sie die Datenvisualisierung gemischter Diagrammtypen
Artikeleinführung:Vue und ECharts4Taro3 Fortgeschrittenes Tutorial: So implementieren Sie die Datenvisualisierung gemischter Diagrammtypen Einführung: In der modernen Datenanalyse und -visualisierung ist die Datenanzeige gemischter Diagrammtypen zu einer häufigen Anforderung geworden. Zu den gängigen Hybriddiagrammtypen gehören Liniendiagramme, Balkendiagramme, Kreisdiagramme und mehr. In diesem Artikel wird vorgestellt, wie Sie das Vue-Framework und die ECharts4Taro3-Bibliothek verwenden, um die Datenvisualisierung gemischter Diagrammtypen zu implementieren. 1. Installations- und Konfigurationsumgebung Zuerst müssen wir Vue und Taro installieren und eine neue erstellen
2023-07-21
Kommentar 0
1391

Suche nach hochwertigen KI-Datenlösungen: Herausforderungen für Unternehmen im Zeitalter großer Modelle
Artikeleinführung:Der Beginn der Ära der großen Modelle beschleunigt den Wandel der Entwicklung künstlicher Intelligenz von modellzentriert zu datenzentriert. Der „China AIGC Data Annotation Industry Panorama Report“ von Qubit Think Tank wies darauf hin, dass derzeit vielerorts Lösungen für große Modelldaten florieren, die sich auf maßgeschneiderte Dienstleistungen aus einer Hand konzentrieren und sich auf den gesamten Lebenszyklus der Entwicklung großer Modelle (einschließlich Vorschulung) konzentrieren , Überwachung und Feinabstimmung, RLHF, Red-Team-Tests, Benchmark-Tests usw.), professionelle Datendienstleister, große Modellunternehmen, KI-Unternehmen und andere Parteien haben relevante Datenlösungen entwickelt, die meisten davon aus einer Hand. maßgeschneiderte Dienstleistungen. Mithilfe von Cloud-Messdaten als Fallstudie für große Modelldatenlösungen für vertikale Branchen kann die Lösung qualitativ hochwertige und effiziente Daten für den End-to-End-Prozess großer Branchenmodelle bereitstellen, einschließlich kontinuierlicher Vorschulung und Aufgabenmikro -Verarbeitung usw.
2023-11-27
Kommentar 0
953
Erhöhen Sie den Wert von KI-Daten und beschleunigen Sie die Entwicklung der großen Modellindustrie
Artikeleinführung:Mit der rasanten Entwicklung der Branche der künstlichen Intelligenz wird künstliche Intelligenz in alle Richtungen kommerzialisiert. KI-Technologie wurde in vielen Bereichen wie Finanzen, medizinische Versorgung, Fertigung, Bildung und Sicherheit implementiert. Die Anwendungsszenarien werden immer vielfältiger und die Bedeutung von Daten wird immer wichtiger. Als wichtiges Glied in der Industriekette der künstlichen Intelligenz spielen Qualität und Quantität der Daten eine Schlüsselrolle bei der Verbesserung der Genauigkeit und Zuverlässigkeit von KI-Modellen. Künstliche Intelligenz (KI) entwickelt sich heute mit großen Modellen als Kern schneller und tritt mit voller Geschwindigkeit in eine neue Ära ein. Als Vertreter hochwertiger, szenariobasierter Datendienste für künstliche Intelligenz verlässt sich Cloud Measurement Data auf seine führenden technischen Fähigkeiten, seine hervorragende Servicequalität und seine umfassende Branchenerfahrung, um professionelle, effiziente und sichere KI-Datendienste für die Branche der künstlichen Intelligenz bereitzustellen.
2023-11-03
Kommentar 0
800
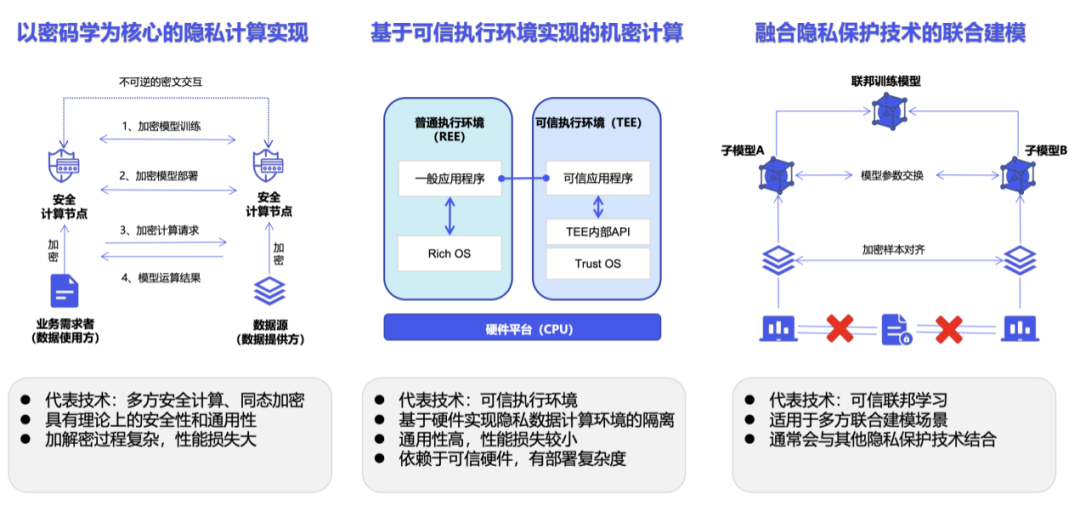
Fehlen qualitativ hochwertige Daten zum Trainieren großer Modelle? Wir haben eine neue Lösung gefunden
Artikeleinführung:Daten als einer der drei Hauptfaktoren, die die Leistung von Modellen für maschinelles Lernen bestimmen, werden zu einem Engpass, der die Entwicklung großer Modelle einschränkt. Wie das Sprichwort sagt: „Müll rein, Müll raus“ [1]: Unabhängig davon, wie gut Ihr Algorithmus ist und wie leistungsfähig Ihre Rechenressourcen sind, hängt die Qualität des Modells direkt von den Daten ab, die Sie zum Trainieren des Modells verwenden. Mit dem Aufkommen verschiedener großer Open-Source-Modelle ist die Bedeutung von Daten, insbesondere von hochwertigen Branchendaten, noch stärker hervorgehoben worden. Bloomberg hat das Finanz-Großmodell BloombergGPT auf Basis des Open-Source-GPT-3-Frameworks erstellt und damit die Machbarkeit der Entwicklung großer vertikaler Branchenmodelle auf Basis des Open-Source-Großmodell-Frameworks bewiesen. Tatsächlich ist es die Aufgabe der meisten großen Modell-Startups in China, Closed-Source-Leichtbau-Großmodelle für vertikale Industrien zu bauen oder anzupassen.
2023-09-18
Kommentar 0
788

Das graphische neuronale Netzwerkmodell SpatialGlue des BGI-Teams integriert Multi-Omics-Daten und wurde in der Unterzeitschrift „Nature' veröffentlicht
Artikeleinführung:Herausgeber: KX Räumliche Transkriptomik und Multi-Omics-Datenintegration Die räumliche Transkriptomik ist eine wichtige Entwicklung nach der Einzelzell-Transkriptomik, weshalb die Integration von Multi-Omics-Daten von entscheidender Bedeutung ist. SpatialGlue: Ein graphisches neuronales Netzwerkmodell mit doppeltem Aufmerksamkeitsmechanismus. Forschungsteams der Singapore Agency for Science, Technology and Research (A*STAR), des BGI und des Renji Hospital der Shanghai Jiao Tong University School of Medicine haben ein graphisches neuronales Netzwerk namens SpatialGlue vorgeschlagen . Modell, das Multi-Omics-Daten durch einen Mechanismus mit doppelter Aufmerksamkeit integriert, um die histologisch relevante Struktur von Gewebeproben räumlich bewusst darzustellen. Vorteile von SpatialGlue SpatialGlue ist in der Lage, mehrere Datenmodalitäten mit ihren jeweiligen räumlichen Kontexten zu kombinieren. Im Vergleich zu anderen Methoden
2024-07-03
Kommentar 0
526

Stärkung der Kapazitäten für die Bereitstellung hochwertiger Daten und Förderung von Innovationen im Bereich allgemeiner großer Modelle künstlicher Intelligenz
Artikeleinführung:In den letzten Jahren waren groß angelegte Pre-Training-Modelle eine der wichtigen treibenden Kräfte für Durchbrüche in der künstlichen Intelligenz, beschleunigten den Entwicklungsprozess der Technik und Popularisierung künstlicher Intelligenz und werden voraussichtlich zum Eckpfeiler einer neuen Generation intelligenter Technologie . Durchbrüche bei großen Modellen der künstlichen Intelligenz sind auf die kontinuierliche Entwicklung hochwertiger Datenversorgungsfunktionen zurückzuführen, die der Schlüssel zur Förderung von Innovationen im Bereich der großen Modelle der allgemeinen künstlichen Intelligenz sind Das Modell hängt mit seinen Parametern und Daten zusammen. Es gibt ein Potenzgesetz zwischen der Berechnungsmenge und der Berechnungsmenge, nämlich „ScalingLaws“. Die Parameter, Daten und der Berechnungsumfang des Modells nehmen exponentiell zu, während der Verlust des Modells im Testsatz exponentiell abnimmt, was darauf hinweist, dass die Leistung des Modells besser ist. Mit anderen Worten, wenn der Berechnungsumfang fest ist und die Parameterskala festgelegt ist klein
2023-08-08
Kommentar 0
1350

Die flexible Crowdsourcing-Plattform unterstützt hochwertige Daten und eine effiziente menschliche Ausrichtung für die Modellindustrie im großen Maßstab
Artikeleinführung:Am 23. August wurde Dr. Wu Runze, technischer Direktor der NetEase Fuxi User Portrait Group, eingeladen, am großen Themenforum der Modellindustrie mit dem Thema „Boiling Capital, AGI Riding the Waves“ teilzunehmen. Im Forum hielt er einen Vortrag zum Thema „Effiziente menschliche Ausrichtung für große Modellimplementierungsanwendungen“. Er stellte den relevanten Unternehmen in der großen Modellbranche vor, wie NetEase Fuxi dabei hilft, einen geschlossenen Kreislauf großer Modelldaten zu erstellen, und teilte diese mit wie man zu geringen Kosten einen großen, datenbasierten Datenkreislauf aufbaut. Unter den drei Elementen großer Modelle – Daten, Rechenleistung und Algorithmen – sind die Stärkung des Maßstabs vorab trainierter Modelle und die Verbesserung der Datenqualität Schlüsselmethoden, um bessere Effekte der künstlichen Intelligenz zu erzielen. Allerdings führt eine einfache Vergrößerung der Modellgröße nicht zwangsläufig zu besseren Ergebnissen. Im Kontext der Subjektivität, die in vielen realen Aufgaben vorhanden ist, erfolgt die Skalierung von Modellen
2024-01-22
Kommentar 0
878

Die neuesten Untersuchungen von Google MIT zeigen: Hochwertige Daten zu erhalten ist nicht schwierig, große Modelle sind die Lösung
Artikeleinführung:Die Beschaffung hochwertiger Daten ist zu einem großen Engpass beim aktuellen Training großer Modelle geworden. Vor einigen Tagen wurde OpenAI von der New York Times verklagt und forderte eine Entschädigung in Milliardenhöhe. In der Beschwerde werden mehrere Beweise für ein Plagiat von GPT-4 aufgeführt. Die New York Times forderte sogar die Zerstörung fast aller großen Modelle wie GPT. Viele große Namen in der KI-Branche glauben seit langem, dass „synthetische Daten“ die beste Lösung für dieses Problem sein könnten. Zuvor hatte das Google-Team auch RLAIF vorgeschlagen, eine Methode, die LLM verwendet, um menschliche Kennzeichnungspräferenzen zu ersetzen, und deren Wirkung den menschlichen nicht einmal nachsteht. Jetzt haben Forscher von Google und MIT herausgefunden, dass das Lernen aus großen Modellen zu Darstellungen der besten Modelle führen kann, die mit echten Daten trainiert wurden. Diese neueste Methode heißt SynCLR und basiert vollständig auf synthetischen Bildern und synthetischen Renderings.
2024-01-14
Kommentar 0
1248

Wie kann man mit Hilfe des SectionReader-Moduls von Go die Sortierung und Zusammenfassung großer Datendateien effizient handhaben?
Artikeleinführung:Wie kann man mit Hilfe des SectionReader-Moduls von Go die Sortierung und Zusammenfassung großer Datendateien effizient handhaben? Bei der Verarbeitung großer Datendateien müssen wir diese häufig sortieren und zusammenfassen. Die herkömmliche Methode, die gesamte Datei auf einmal zu lesen, eignet sich jedoch nicht für große Datendateien, da diese möglicherweise die Speichergrenzen überschreiten. Glücklicherweise bietet das SectionReader-Modul in der Go-Sprache eine effiziente Möglichkeit, dieses Problem zu lösen. SectionReader ist ein Paket in der Go-Sprache.
2023-07-23
Kommentar 0
1132

Databricks veröffentlicht KI-Modell-SDK für die Big-Data-Analyseplattform Spark: Generierung von SQL- und FySpark-Sprachdiagrammcode mit einem Klick
Artikeleinführung:Laut Nachrichten vom 10. Juli hat Databricks kürzlich das von der Big-Data-Analyseplattform Spark verwendete KI-Modell-SDK veröffentlicht. Wenn Entwickler Code schreiben, können sie Anweisungen auf Englisch geben, und der Compiler konvertiert die englischen Anweisungen in die Sprache PySpark oder SQL Codes zur Verbesserung der Entwicklereffizienz. ▲Bildquelle Databricks-Website Es wird berichtet, dass Spark ein Open-Source-Big-Data-Analysetool ist, das mehr als 1 Milliarde Mal pro Jahr heruntergeladen und in 208 Ländern und Regionen auf der ganzen Welt verwendet wird. ▲Bildquelle Databricks-Website Databricks sagte, dass der KI-Code-Assistent GitHubCopilot von Microsoft leistungsstark ist, aber die Schwelle für die Verwendung ist auch relativ hoch, das SDK von Databricks ist relativ universeller und einfacher zu verwenden.
2023-07-17
Kommentar 0
1209

Welche Art von Bildern speichert MySQL?
Artikeleinführung:MySQL speichert Bilder in drei Typen: BLOB, MEDIUMBLOB und LONGBLOB. Spezifische Einführung: 1. Der BLOB-Typ kann Binärdaten speichern, die zum Speichern einiger kleinerer Bilder wie Avatare, Symbole usw. geeignet sind. 2. Der MEDIUMBLOB-Typ kann mittelgroße Binärdaten speichern, die zum Speichern einiger etwas größerer Bilder geeignet sind. LONGBLOB-Typ Kann größere Binärdaten speichern und eignet sich zum Speichern großer Bilder oder Bilder, die in hoher Auflösung gespeichert werden müssen.
2023-07-18
Kommentar 0
10575

