


Empfehlungssysteme sind wichtig, um der Herausforderung der Informationsüberflutung zu begegnen, da sie maßgeschneiderte Empfehlungen basierend auf den persönlichen Vorlieben der Benutzer bereitstellen. In den letzten Jahren hat die Deep-Learning-Technologie die Entwicklung von Empfehlungssystemen stark vorangetrieben und Einblicke in das Verhalten und die Präferenzen der Nutzer verbessert.
Allerdings stehen herkömmliche Methoden des überwachten Lernens in praktischen Anwendungen vor Herausforderungen, da das Problem der Datenknappheit ihre Fähigkeit einschränkt, die Benutzerleistung effektiv zu erlernen.
Um dieses Problem zu schützen und zu überwinden, wird bei Schülern die Technologie des selbstüberwachten Lernens (SSL) angewendet, die die inhärente Datenstruktur zur Generierung von Überwachungssignalen nutzt und sich nicht ausschließlich auf gekennzeichnete Daten verlässt.
Diese Methode verwendet ein Empfehlungssystem, das aussagekräftige Informationen aus unbeschrifteten Daten extrahieren und genaue Vorhersagen und Empfehlungen treffen kann, selbst wenn die Daten knapp sind.

Artikeladresse: https://arxiv.org/abs/2404.03354
Open-Source-Datenbank: https://github.com/HKUDS/Awesome-SSLRec-Papers
Open Source Code-Bibliothek: https://github.com/HKUDS/SSLRec
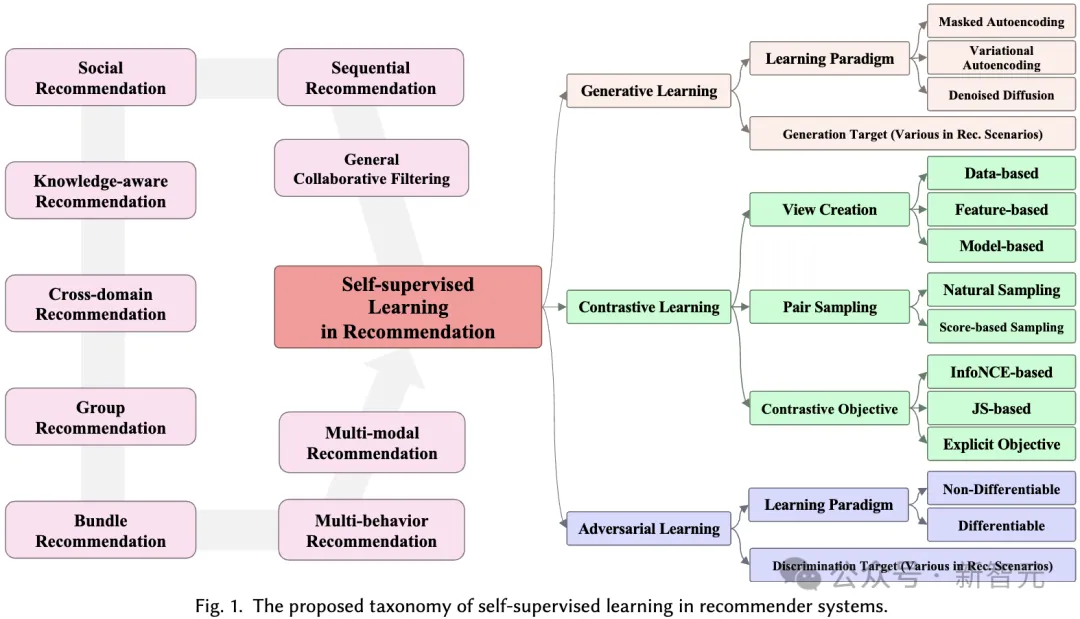
Dieser Artikel bespricht selbstüberwachte Lernrahmen, die für Empfehlungssysteme entwickelt wurden, und führt eine eingehende Analyse von mehr als 170 verwandten Artikeln durch. Wir haben neun verschiedene Anwendungsszenarien untersucht, um ein umfassendes Verständnis dafür zu gewinnen, wie SSL Empfehlungssysteme in verschiedenen Szenarien verbessern kann.
Für jede Domäne diskutieren wir ausführlich verschiedene selbstüberwachte Lernparadigmen, einschließlich kontrastivem Lernen, generativem Lernen und kontradiktorischem Lernen, und zeigen, wie SSL die Leistung von Empfehlungssystemen in verschiedenen Situationen verbessern kann.
Die Forschung zu Empfehlungssystemen deckt verschiedene Aufgaben in verschiedenen Szenarien ab, wie z. B. kollaborative Filterung, Sequenzempfehlung, Multiverhaltensempfehlung usw. Diese Aufgaben haben unterschiedliche Datenparadigmen und Ziele. Hier geben wir zunächst eine allgemeine Definition, ohne auf spezifische Variationen für verschiedene Empfehlungsaufgaben einzugehen. In Empfehlungssystemen gibt es zwei Hauptgruppen: Benutzergruppen, bezeichnet als 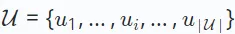 , und Elementgruppen, bezeichnet als
, und Elementgruppen, bezeichnet als 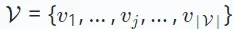 .
.
Verwenden Sie dann eine Interaktionsmatrix 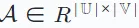 , um die aufgezeichneten Interaktionen zwischen dem Benutzer und dem Artikel darzustellen. In dieser Matrix wird dem Eintrag Ai,j der Matrix der Wert 1 zugewiesen, wenn der Benutzer ui mit dem Element vj interagiert hat, andernfalls ist er 0.
, um die aufgezeichneten Interaktionen zwischen dem Benutzer und dem Artikel darzustellen. In dieser Matrix wird dem Eintrag Ai,j der Matrix der Wert 1 zugewiesen, wenn der Benutzer ui mit dem Element vj interagiert hat, andernfalls ist er 0.
Die Definition von Interaktion kann an verschiedene Kontexte und Datensätze angepasst werden (z. B. Ansehen eines Films, Klicken auf eine E-Commerce-Website oder Tätigen eines Kaufs).
Darüber hinaus gibt es in verschiedenen Empfehlungsaufgaben unterschiedliche Hilfsbeobachtungsdaten, die als entsprechende Beziehungen aufgezeichnet werden.
Und in der sozialen Empfehlung umfasst X Beziehungen auf Benutzerebene, wie zum Beispiel Freundschaft. Basierend auf der obigen Definition optimiert das Empfehlungsmodell eine Vorhersagefunktion f(⋅) mit dem Ziel, den Präferenzwert zwischen jedem Benutzer u und Element v genau zu schätzen:
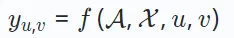
Der Präferenzwert yu,v repräsentiert Benutzer u und Artikel v Möglichkeit der Interaktion.
Basierend auf dieser Bewertung kann das Empfehlungssystem jedem Benutzer nicht interagierte Artikel empfehlen, indem es eine Rangliste der Artikel basierend auf der geschätzten Präferenzbewertung bereitstellt. In der Rezension untersuchen wir weiter die Datenform von (A,X) in verschiedenen Empfehlungsszenarien und die Rolle des selbstüberwachten Lernens darin.
In den letzten Jahren haben tiefe neuronale Netze beim überwachten Lernen gute Leistungen erbracht, was sich in verschiedenen Bereichen widerspiegelt, darunter Computer Vision, Verarbeitung natürlicher Sprache und Empfehlungssysteme. Aufgrund der starken Abhängigkeit von beschrifteten Daten steht das überwachte Lernen jedoch vor Herausforderungen im Umgang mit der Label-Spärlichkeit, die auch in Empfehlungssystemen ein häufiges Problem darstellt.
Um diese Einschränkung zu beseitigen, hat sich selbstüberwachtes Lernen als vielversprechende Methode herausgestellt, bei der die Daten selbst als gelernte Bezeichnung verwendet werden. Selbstüberwachtes Lernen in Empfehlungssystemen umfasst drei verschiedene Paradigmen: kontrastives Lernen, generatives Lernen und kontradiktorisches Lernen. 2.1 Kontrastives Lernen Beim kontrastiven Lernen des Empfehlungssystems besteht das Ziel darin, die folgende Verlustfunktion zu minimieren:
ω∗ repräsentiert den kontrastiven Ansichtserstellungsvorgang und verschiedene Empfehlungsalgorithmen, die auf kontrastivem Lernen basieren haben unterschiedliche Erstellungsprozesse. Die Konstruktion jeder Ansicht besteht aus einem Datenerweiterungsprozess ω∗ (der Knoten/Kanten im erweiterten Graphen umfassen kann) und einem Einbettungskodierungsprozess E∗. Das Ziel von
minimizing 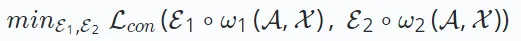
besteht darin, eine robuste Codierungsfunktion zu erhalten, die die Konsistenz zwischen Ansichten maximiert. Diese Konsistenz über Ansichten hinweg kann durch Methoden wie gegenseitige Informationsmaximierung oder Instanzunterscheidung erreicht werden.
2.2 Generatives Lernen
 Das Ziel des generativen Lernens besteht darin, die Struktur und Muster von Daten zu verstehen, um sinnvolle Darstellungen zu lernen. Es optimiert ein tiefes Encoder-Decoder-Modell, das fehlende oder beschädigte Eingabedaten rekonstruiert. Der
Das Ziel des generativen Lernens besteht darin, die Struktur und Muster von Daten zu verstehen, um sinnvolle Darstellungen zu lernen. Es optimiert ein tiefes Encoder-Decoder-Modell, das fehlende oder beschädigte Eingabedaten rekonstruiert. Der
 Hier steht ω für eine Operation wie Maskierung oder Störung. D∘E repräsentiert den Prozess der Kodierung und Dekodierung zur Rekonstruktion der Ausgabe. Neuere Forschungen haben auch eine reine Decoder-Architektur eingeführt, die Daten ohne Encoder-Decoder-Setup effizient rekonstruiert. Dieser Ansatz verwendet ein einzelnes Modell (z. B. Transformer) zur Rekonstruktion und wird typischerweise auf serialisierte Empfehlungen angewendet, die auf generativem Lernen basieren. Das Format der Verlustfunktion
Hier steht ω für eine Operation wie Maskierung oder Störung. D∘E repräsentiert den Prozess der Kodierung und Dekodierung zur Rekonstruktion der Ausgabe. Neuere Forschungen haben auch eine reine Decoder-Architektur eingeführt, die Daten ohne Encoder-Decoder-Setup effizient rekonstruiert. Dieser Ansatz verwendet ein einzelnes Modell (z. B. Transformer) zur Rekonstruktion und wird typischerweise auf serialisierte Empfehlungen angewendet, die auf generativem Lernen basieren. Das Format der Verlustfunktion 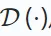 hängt vom Datentyp ab, z. B. mittlerer quadratischer Fehler für kontinuierliche Daten und Kreuzentropieverlust für kategoriale Daten. 2.3 Kontradiktorisches Lernen ist real oder generiert. Im Gegensatz zum generativen Lernen unterscheidet sich das kontradiktorische Lernen dadurch, dass es einen Diskriminator einschließt, der konkurrierende Interaktionen nutzt, um die Fähigkeit des Generators zu verbessern, qualitativ hochwertige Ergebnisse zu erzeugen und so den Diskriminator zu täuschen.
hängt vom Datentyp ab, z. B. mittlerer quadratischer Fehler für kontinuierliche Daten und Kreuzentropieverlust für kategoriale Daten. 2.3 Kontradiktorisches Lernen ist real oder generiert. Im Gegensatz zum generativen Lernen unterscheidet sich das kontradiktorische Lernen dadurch, dass es einen Diskriminator einschließt, der konkurrierende Interaktionen nutzt, um die Fähigkeit des Generators zu verbessern, qualitativ hochwertige Ergebnisse zu erzeugen und so den Diskriminator zu täuschen.
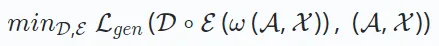 Daher kann das Lernziel des kontradiktorischen Lernens wie folgt definiert werden:
Daher kann das Lernziel des kontradiktorischen Lernens wie folgt definiert werden:
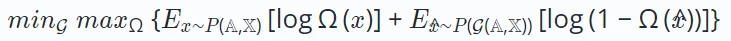
Hier stellt die Variable x die reale Stichprobe dar, die aus der zugrunde liegenden Datenverteilung erhalten wurde, während 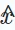 die vom Generator G(⋅) generierte synthetische Stichprobe darstellt. Während des Trainings verbessern sowohl der Generator als auch der Diskriminator ihre Fähigkeiten durch konkurrierende Interaktionen. Letztendlich ist der Generator bestrebt, qualitativ hochwertige Ergebnisse zu erzeugen, die für nachgelagerte Aufgaben von Vorteil sind.
die vom Generator G(⋅) generierte synthetische Stichprobe darstellt. Während des Trainings verbessern sowohl der Generator als auch der Diskriminator ihre Fähigkeiten durch konkurrierende Interaktionen. Letztendlich ist der Generator bestrebt, qualitativ hochwertige Ergebnisse zu erzeugen, die für nachgelagerte Aufgaben von Vorteil sind.
In diesem Abschnitt schlagen wir ein umfassendes Klassifizierungssystem für die Anwendung von selbstüberwachtem Lernen in Empfehlungssystemen vor. Wie bereits erwähnt, können selbstüberwachte Lernparadigmen in drei Kategorien unterteilt werden: kontrastives Lernen, generatives Lernen und kontradiktorisches Lernen. Daher basiert unser Klassifizierungssystem auf diesen drei Kategorien und bietet tiefere Einblicke in jede Kategorie.
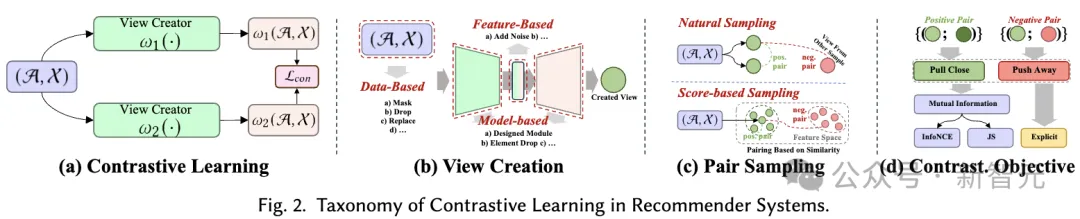
Das Grundprinzip des kontrastiven Lernens (CL) besteht darin, die Konsistenz zwischen verschiedenen Ansichten zu maximieren. Daher schlagen wir eine ansichtszentrierte Taxonomie vor, die aus drei Schlüsselkomponenten besteht, die bei der Anwendung kontrastiven Lernens zu berücksichtigen sind: Ansichten erstellen, Ansichten koppeln, um die Konsistenz zu maximieren, und Konsistenz optimieren.
Erstellung anzeigen. Erstellen Sie Ansichten, die die verschiedenen Datenaspekte hervorheben, auf die sich das Modell konzentriert. Es kann globale kollaborative Informationen kombinieren, um die Fähigkeit des Empfehlungssystems zur Handhabung globaler Beziehungen zu verbessern, oder zufälliges Rauschen einführen, um die Robustheit des Modells zu verbessern.
Wir betrachten die Verbesserung von Eingabedaten (z. B. Diagramme, Sequenzen, Eingabemerkmale) als Ansichtserstellung auf Datenebene, während die Verbesserung latenter Merkmale während der Inferenz als Ansichtserstellung auf Merkmalsebene betrachtet wird. Wir schlagen ein hierarchisches Klassifizierungssystem vor, das Techniken zur Ansichtserstellung von der Basisdatenebene bis zur Ebene des neuronalen Modells umfasst.
Paar-Sampling. Der Ansichtserstellungsprozess generiert mindestens zwei verschiedene Ansichten für jede Stichprobe in den Daten. Der Kern des kontrastiven Lernens besteht darin, die Ausrichtung bestimmter Ansichten zu maximieren (d. h. sie näher zusammenzubringen), während andere Ansichten verdrängt werden.
Um dies zu erreichen, besteht der Schlüssel darin, die positiven Probenpaare zu identifizieren, die näher gebracht werden sollten, und andere Ansichten zu identifizieren, die negative Probenpaare bilden. Diese Strategie wird als gepaarte Stichprobe bezeichnet und besteht hauptsächlich aus zwei gepaarten Stichprobenmethoden:
Kontrastives Objektiv. Das Lernziel beim kontrastiven Lernen besteht darin, die gegenseitige Information zwischen Paaren positiver Stichproben zu maximieren, was wiederum die Leistung des Lernempfehlungsmodells verbessern kann. Da es nicht möglich ist, gegenseitige Informationen direkt zu berechnen, wird beim kontrastiven Lernen normalerweise eine zulässige Untergrenze als Lernziel verwendet. Allerdings gibt es auch explizite Ziele, positive Paare näher zusammenzubringen.

Beim generativen selbstüberwachten Lernen besteht das Hauptziel darin, die Wahrscheinlichkeitsschätzung der realen Datenverteilung zu maximieren. Dadurch können die erlernten, aussagekräftigen Darstellungen die zugrunde liegende Struktur und Muster in den Daten erfassen, die dann in nachgelagerten Aufgaben verwendet werden können. In unserem Klassifizierungssystem berücksichtigen wir zwei Aspekte, um verschiedene auf generativem Lernen basierende Empfehlungsmethoden zu unterscheiden: generatives Lernparadigma und generatives Ziel.
Generatives Lernparadigma. Im Kontext der Empfehlung können selbstüberwachte Methoden, die generatives Lernen verwenden, in drei Paradigmen eingeteilt werden:
Generation Target. Beim generativen Lernen ist die Frage, welches Datenmuster als generierte Bezeichnung betrachtet wird, ein weiterer Punkt, der berücksichtigt werden muss, um aussagekräftige selbstüberwachte Hilfssignale zu liefern. Im Allgemeinen variieren die Generierungsziele für verschiedene Methoden und in verschiedenen Empfehlungsszenarien. Beispielsweise können bei einer Sequenzempfehlung die Elemente in der Sequenz das Generierungsziel sein, um die Beziehung zwischen Elementen in der Sequenz zu simulieren. Bei der interaktiven Diagrammempfehlung können die Generierungsziele Knoten/Kanten im Diagramm sein, um topologische Korrelationen auf hoher Ebene im Diagramm zu erfassen.
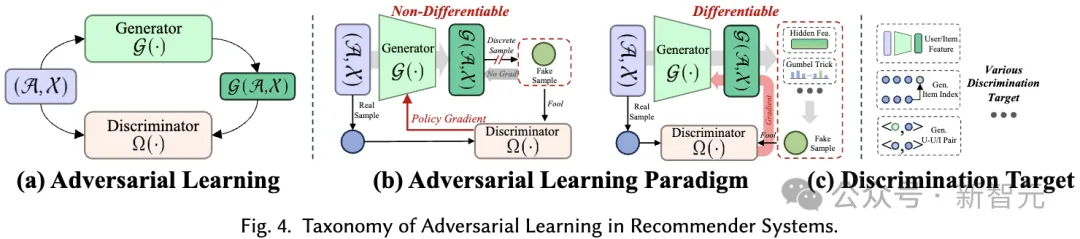
Beim kontradiktorischen Lernen von Empfehlungssystemen spielt der Diskriminator eine entscheidende Rolle bei der Unterscheidung der generierten Fake-Samples von echten Samples. Ähnlich wie beim generativen Lernen deckt das von uns vorgeschlagene Klassifizierungssystem kontroverse Lernmethoden in Empfehlungssystemen aus zwei Perspektiven ab: Lernparadigma und Diskriminierungsziel:
Gegnerisches Lernparadigma. In Empfehlungssystemen besteht kontradiktorisches Lernen aus zwei verschiedenen Paradigmen, je nachdem, ob der diskriminierende Verlust des Diskriminators auf differenzierbare Weise auf den Generator zurückpropagiert werden kann.
Diskriminierungsziel. Unterschiedliche Empfehlungsalgorithmen bewirken, dass der Generator unterschiedliche Eingaben generiert, die dann zur Unterscheidung an den Diskriminator weitergeleitet werden. Dieser Prozess zielt darauf ab, die Fähigkeit des Generators zu verbessern, qualitativ hochwertige Inhalte zu produzieren, die näher an der Realität sind. Auf der Grundlage konkreter Empfehlungsaufgaben werden konkrete Diskriminierungsziele entworfen. 3.4 Verschiedene Empfehlungsszenarien Weitere Informationen finden Sie im Artikel):
Soziale Empfehlung – Kombiniert Benutzerbeziehungsinformationen in sozialen Netzwerken, um personalisiertere Empfehlungen bereitzustellen.
Das obige ist der detaillierte Inhalt vonHKU überprüft 170 Empfehlungsalgorithmen für „selbstüberwachtes Lernen' und veröffentlicht SSL4Rec: Der Code und die Datenbank sind vollständig Open Source!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 So beheben Sie den Discuz-Datenbankfehler
So beheben Sie den Discuz-Datenbankfehler
 Das Computersystem besteht aus
Das Computersystem besteht aus
 Was bedeuten Zeichen in voller Breite?
Was bedeuten Zeichen in voller Breite?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



