


Das neueste inländische Open-Source-MoE-Großmodell ist gleich nach seinem Debüt populär geworden.
Die Leistung von DeepSeek-V2 erreicht GPT-4-Niveau, aber es ist Open Source, kostenlos für die kommerzielle Nutzung und der API-Preis beträgt nur ein Prozent von GPT-4-Turbo.
Als es veröffentlicht wurde, löste es sofort viele Diskussionen aus.
 Bilder
Bilder
Den veröffentlichten Leistungsindikatoren zufolge übertreffen die umfassenden chinesischen Fähigkeiten von DeepSeek V2 die vieler Open-Source-Modelle. Gleichzeitig sind auch Closed-Source-Modelle wie GPT-4 Turbo und Wenkuai 4.0 dabei Echelon.
Die umfassenden Englischkenntnisse liegen ebenfalls auf der gleichen ersten Stufe wie LLaMA3-70B und übertreffen Mixtral 8x22B, das ebenfalls ein MoE ist.
Es zeigt auch gute Leistungen in den Bereichen Wissen, Mathematik, logisches Denken, Programmieren usw. Und unterstützt 128K-Kontext.
 Bilder
Bilder
Diese Funktionen können von normalen Benutzern direkt und kostenlos genutzt werden. Die Closed Beta ist jetzt geöffnet, Sie können sie sofort nach der Registrierung erleben.
 Pictures
Pictures
API ist noch teurer: Die Eingabe beträgt 1 Yuan und die Ausgabe 2 Yuan pro Million Token (32K-Kontext). Der Preis beträgt nur knapp ein Prozent des GPT-4-Turbo.
Gleichzeitig wird auch die Modellarchitektur innoviert, indem selbst entwickelte MLA- (Multi-head Latent Attention) und Sparse-Strukturen verwendet werden, wodurch der Umfang der Modellberechnung und des Inferenzspeichers erheblich reduziert werden kann.
Netizens beklagten: DeepSeek bringt den Menschen immer Überraschungen!
 Bilder
Bilder
Wir waren die ersten, die die konkreten Auswirkungen erlebt haben!
Derzeit kann die interne Betaversion V2 den universellen Dialog- und Code-Assistenten erleben.
 Bilder
Bilder
Sie können die Logik, das Wissen, die Generierung, die Mathematik und andere Fähigkeiten großer Modelle in allgemeinen Gesprächen testen.
Zum Beispiel können Sie es bitten, den Stil von „The Legend of Zhen Huan“ zu imitieren, um Lippenstift-Texte zu schreiben.
 Bilder
Bilder
können auch auf beliebte Weise erklären, was Quantenverschränkung ist.
 Bilder
Bilder
In Bezug auf die Mathematik kann es Fragen zur Infinitesimalrechnung mit hohen Zahlen beantworten, wie zum Beispiel:
Verwenden Sie Infinitesimalrechnung, um die unendliche Reihendarstellung der Basis e des natürlichen Logarithmus zu beweisen.
 Bilder
Bilder
können auch einige Sprachlogikfallen vermeiden.
 Bilder
Bilder
Der Test zeigt, dass der Wissensinhalt von DeepSeek-V2 auf 2023 aktualisiert wurde.
 Bilder
Bilder
In Bezug auf den Code zeigt die interne Testseite, dass DeepSeek-Coder-33B zur Beantwortung von Fragen verwendet wird.
Bei der Generierung einfacherer Codes gab es in mehreren tatsächlichen Tests keinen Fehler.
 Bilder
Bilder
können den angegebenen Code auch erklären und analysieren.
 Bilder
Bilder
 Bilder
Bilder
Allerdings gibt es auch Fälle von falschen Antworten im Test.
In der folgenden Logikfrage hat DeepSeek-V2 während des Berechnungsprozesses fälschlicherweise berechnet, dass die Zeit, die eine Kerze benötigt, um von beiden Enden gleichzeitig angezündet zu werden und auszubrennen, ein Viertel der Zeit beträgt, die zum Brennen benötigt wird aus einem Ende heraus. Welche Upgrades bringen
 Bilder
Bilder
Laut der offiziellen Einführung verfügt DeepSeek-V2 über einen Gesamtparameter von 236B und eine Aktivierung von 21B, was ungefähr die Modellfähigkeit von 70B~110B Dense erreicht.
 Bilder
Bilder
Im Vergleich zum vorherigen DeepSeek 67B bietet es eine stärkere Leistung und geringere Schulungskosten. Es kann 42,5 % der Schulungskosten einsparen, den KV-Cache um 93,3 % reduzieren und den maximalen Durchsatz auf das 5,76-fache erhöhen.
Offiziell heißt es, dass dies bedeutet, dass der von DeepSeek-V2 verbrauchte Videospeicher (KV-Cache) nur 1/5 bis 1/100 des Dense-Modells derselben Stufe beträgt und die Kosten pro Token erheblich reduziert werden.
Es wurden viele Kommunikationsoptimierungen speziell für die H800-Spezifikationen vorgenommen. Es wird tatsächlich auf einer 8-Karten-H800-Maschine eingesetzt. Der Eingabedurchsatz übersteigt 100.000 Token pro Sekunde.
 Bilder
Bilder
Bei einigen grundlegenden Benchmarks ist die Leistung des DeepSeek-V2-Basismodells wie folgt:
 Bilder
Bilder
DeepSeek-V2 verwendet eine innovative Architektur.
Vorgeschlagene MLA-Architektur (Multi-Head Latent Attention), um die Menge an Berechnungs- und Inferenzspeicher deutlich zu reduzieren.
Gleichzeitig haben wir die Sparse-Struktur selbst entwickelt, um den Berechnungsaufwand weiter zu reduzieren.
 Bilder
Bilder
Einige Leute haben gesagt, dass diese Upgrades für groß angelegte Computer in Rechenzentren sehr hilfreich sein könnten.
 Bilder
Bilder
Und in Bezug auf die API-Preise ist DeepSeek-V2 fast niedriger als alle Star-Modelle auf dem Markt.
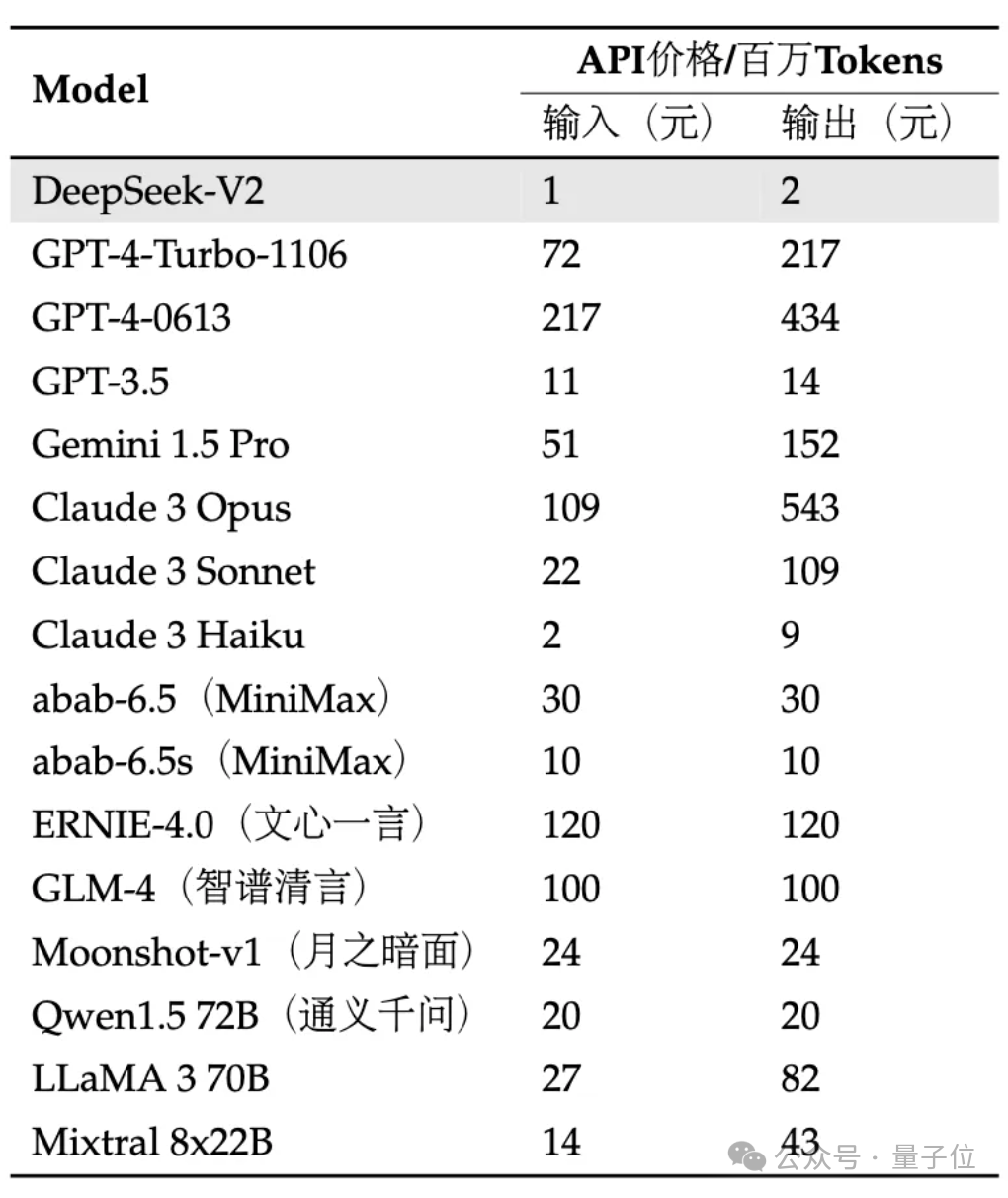 Bilder
Bilder
Das Team gab an, dass das DeepSeek-V2-Modell und -Papier ebenfalls vollständig Open Source sein werden. Modellgewichte und technische Berichte werden angegeben.
Melden Sie sich jetzt bei der offenen Plattform DeepSeek API an und registrieren Sie sich, um 10 Millionen Input-/5 Millionen Output-Token als Geschenk zu erhalten. Die normale Testversion ist völlig kostenlos.
Das obige ist der detaillierte Inhalt vonInländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



