


Nach Google kommt Meta auch dazu, unendlich lange Kontexte zu rollen.
Die quadratische Komplexität und die schwache Längenextrapolation von Transformern schränken ihre Fähigkeit ein, auf lange Sequenzen zu skalieren. Obwohl es quadratische Lösungen wie lineare Aufmerksamkeits- und Zustandsraummodelle gibt, schneiden sie in Bezug auf die Effizienz vor dem Training schlecht ab und nachgelagerte Aufgabengenauigkeit.
Kürzlich hat der von Google vorgeschlagene Infini-Transformer die Aufmerksamkeit der Menschen auf sich gezogen, indem er eine effektive Methode eingeführt hat, mit der Transformer-basierte große Sprachmodelle (LLM) auf unendlich lange Eingaben erweitert werden können, ohne den Speicher- und Rechenbedarf zu erhöhen.
Fast zeitgleich schlug Meta auch eine Technologie für unendlich lange Texte vor.

Papieradresse: https://arxiv.org/pdf/2404.08801.pdf
Papiertitel: MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length
Code: https:/ /github.com/XuezheMax/megalodon
In einem am 12. April eingereichten Artikel stellten Institutionen von Meta, University of Southern California, CMU, UCSD und anderen Institutionen MEGALODON vor, ein neuronales Netzwerk für effiziente Sequenzmodellierung und Kontextlänge ist nicht begrenzt.
MEGALODON entwickelt die Struktur von MEGA (Exponential Moving Average with Gated Attention) weiter und führt eine Vielzahl technischer Komponenten ein, um seine Fähigkeiten und Stabilität zu verbessern, darunter Complex Exponential Moving Average (CEMA), eine Zeitschritt-Normalisierungsschicht, einen normalisierten Aufmerksamkeitsmechanismus und eine vornormierte Restverbindung mit zwei Merkmalen.

Im direkten Vergleich mit LLAMA2 erreicht MEGALODON auf einer Skala von 7 Milliarden Parametern und 2 Billionen Trainingstokens eine bessere Effizienz als Transformer. Der Trainingsverlust von MEGALODON erreicht 1,70, was zwischen LLAMA2-7B (1,75) und 13B (1,67) liegt. Die Verbesserungen von MEGALODON gegenüber Transformers zeigen eine starke Leistung in einer Reihe von Benchmarks für verschiedene Aufgaben und Modalitäten.
MEGALODON ist im Wesentlichen eine verbesserte MEGA-Architektur (Ma et al., 2023), die den Gated-Attention-Mechanismus und die klassische Methode des exponentiellen gleitenden Durchschnitts (EMA) nutzt. Um die Fähigkeiten und Effizienz von MEGALODON beim groß angelegten Vortraining mit langen Kontexten weiter zu verbessern, schlugen die Autoren eine Vielzahl technischer Komponenten vor. Zunächst führt MEGALODON eine CEMA-Komponente (Complex Exponential Moving Average) ein, die den mehrdimensionalen gedämpften EMA in MEGA auf den komplexen Bereich erweitert. Zweitens schlägt MEGALODON eine Zeitschritt-Normalisierungsschicht vor, die Gruppennormalisierungsschichten auf autoregressive Sequenzmodellierungsaufgaben verallgemeinert, um eine Normalisierung entlang der sequentiellen Dimension zu ermöglichen.
Um die Stabilität des groß angelegten Vortrainings zu verbessern, schlägt MEGALODON außerdem eine normalisierte Aufmerksamkeit sowie eine Vornormalisierung mit einer Restkonfiguration mit zwei Sprüngen vor, indem die weit verbreiteten Vornormalisierungs- und Postnormalisierungsmethoden modifiziert werden. Durch einfaches Unterteilen der Eingabesequenz in feste Blöcke, wie dies bei MEGA-chunk der Fall ist, erreicht MEGALODON eine lineare Rechen- und Speicherkomplexität beim Modelltraining und bei der Inferenz.
Im direkten Vergleich mit LLAMA2 übertrifft MEGALODON-7B bei der Kontrolle von Daten und Berechnungen die hochmoderne Transformer-Variante, die zum Trainieren von LLAMA2-7B verwendet wird, in Bezug auf die Trainingsperplexität deutlich. Auswertungen zur Modellierung langer Kontexte, einschließlich Perplexity in verschiedenen Kontextlängen bis zu 2M und QS-Aufgaben für lange Kontexte in Scrolls, zeigen die Fähigkeit von MEGALODON, Sequenzen unendlicher Länge zu modellieren. Zusätzliche experimentelle Ergebnisse zu kleinen und mittelgroßen Benchmarks, darunter LRA, ImageNet, Speech Commands, WikiText-103 und PG19, zeigen die Fähigkeiten von MEGALODON in Bezug auf Lautstärke und Multimodalität.
Einführung in die Methode
Zunächst geht der Artikel kurz auf die Schlüsselkomponenten der MEGA-Architektur (Moving Average Ausgestattet Gated Attention) ein und erörtert die bei MEGA bestehenden Probleme.
MEGA bettet eine EMA-Komponente (exponentieller gleitender Durchschnitt) in die Berechnung der Aufmerksamkeitsmatrix ein, um induktive Verzerrungen über Zeitschrittdimensionen hinweg zu berücksichtigen. Insbesondere erweitert der mehrdimensional gedämpfte EMA zunächst jede Dimension der Eingabesequenz Die Form ist wie folgt: 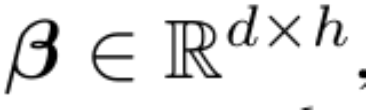
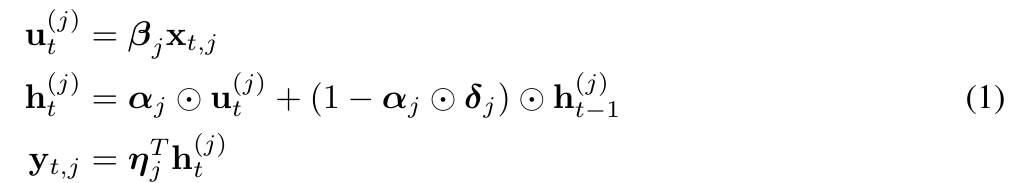
Technisch gesehen hilft die EMA-Unterschicht in MEGA dabei, lokale Kontextinformationen in der Nähe jedes Tokens zu erfassen, wodurch das Problem des Informationsverlusts im Kontext über Blockgrenzen hinweg gemildert wird. Obwohl MEGA beeindruckende Ergebnisse erzielt, steht es vor den folgenden Problemen:
i) Aufgrund der begrenzten Ausdruckskraft der EMA-Unterschicht in MEGA bleibt die Leistung von MEGA mit Aufmerksamkeit auf Blockebene immer noch hinter der von MEGA mit voller Aufmerksamkeit zurück.
ii) Für unterschiedliche Aufgaben und Datentypen kann es architektonische Unterschiede in der endgültigen MEGA-Architektur geben, wie z. B. unterschiedliche Normalisierungsschichten, Normalisierungsmodi und Aufmerksamkeitsfunktionen f (・).
iii) Es gibt keine empirischen Beweise dafür, dass MEGA für ein groß angelegtes Vortraining geeignet ist.


CEMA: Erweiterung der mehrdimensionalen Dämpfungs-EMA auf den komplexen Bereich
Um die Probleme von MEGA zu lösen, schlägt diese Forschung MEGALODON vor.
Konkret schlugen sie kreativ den komplexen exponentiellen gleitenden Durchschnitt CEMA (komplexer exponentieller gleitender Durchschnitt) vor, indem sie die obige Gleichung (1) in die folgende Form umschrieben:
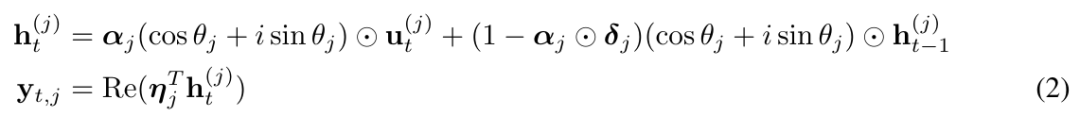
und θ_j in (2) wie folgt parametrisierten:
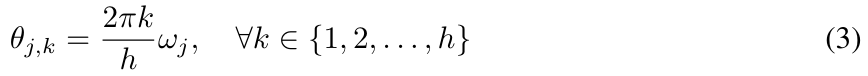
Zeitschrittnormalisierung
Obwohl die Leistung der Ebenennormalisierung in Kombination mit Transformer beeindruckend ist, ist es offensichtlich, dass die Ebenennormalisierung nicht direkt entlang der räumlichen Dimension reduziert werden kann (auch Die interne Kovariatenverschiebung wird als Zeitschritt- oder Sequenzdimension bezeichnet).
In MEGALODON erweitert diese Studie die Gruppennormalisierung auf den autoregressiven Fall, indem der kumulative Mittelwert und die Varianz berechnet werden.
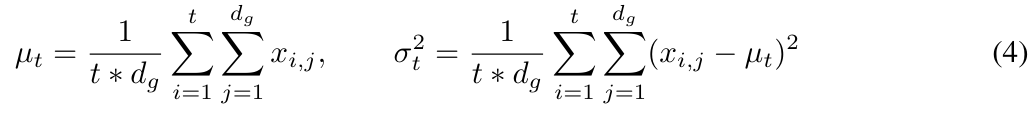
Abbildung 2 veranschaulicht die Ebenennormalisierung und die Zeitschrittnormalisierung.
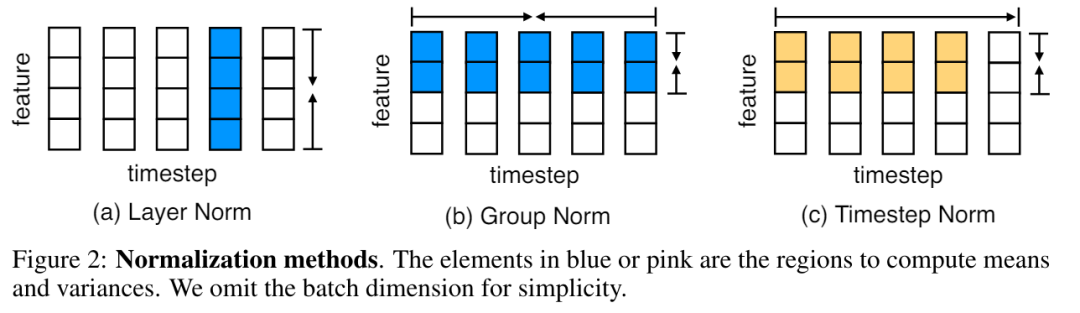
Normalisierte Aufmerksamkeit bei MEGALODON
Darüber hinaus schlägt die Forschung auch einen normalisierten Aufmerksamkeitsmechanismus vor, der speziell auf MEGA zugeschnitten ist, um seine Stabilität zu verbessern. Die Form ist wie folgt:

Dann wird die Aufmerksamkeitsoperation in der obigen Gleichung (17) geändert in:

Vornorm mit Zwei-Hop-Residuum
Durch Untersuchungen wird festgestellt, dass Eine Vergrößerung der Modellgröße kann zu einer Instabilität der Vornormierung führen. Die auf dem Transformer-Block basierende Vornormalisierung kann wie folgt ausgedrückt werden (dargestellt in Abbildung 3 (b)):

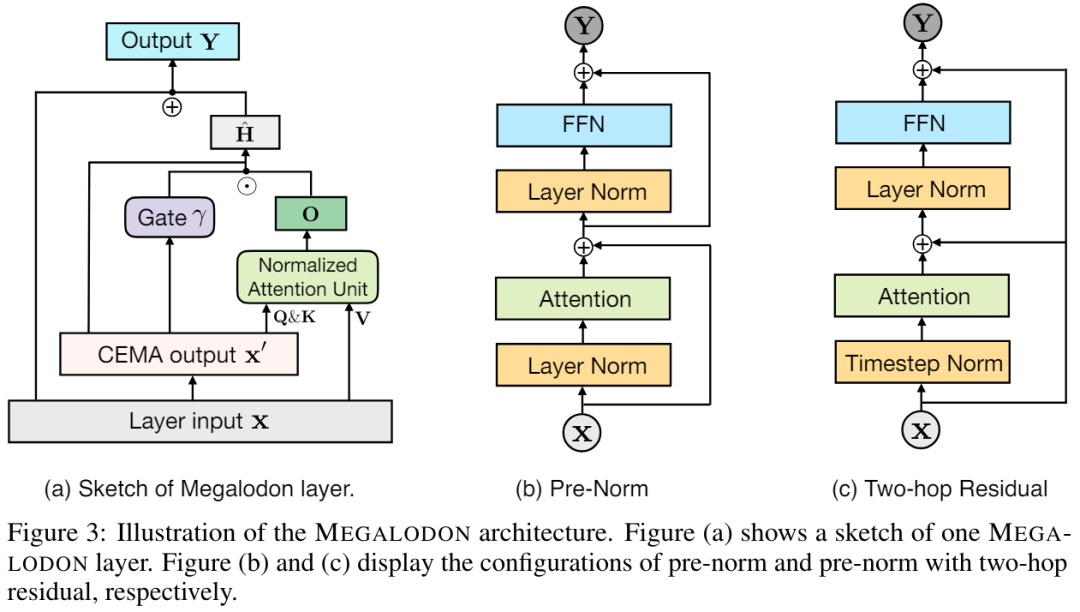
In der ursprünglichen MEGA-Architektur wird φ (19) für die Gated-Restverbindung (21) verwendet ), um dieses Problem zu lindern. Das Update-Gate φ führt jedoch mehr Modellparameter ein, und das Instabilitätsproblem besteht weiterhin, wenn die Modellgröße auf 7 Milliarden erweitert wird. MEGALODON führt eine neue Konfiguration namens Pre-Norm mit Two-Hop-Residuen ein, die einfach die Restverbindungen in jedem Block neu anordnet, wie in Abbildung 3(c) dargestellt: Um die Skalierbarkeit und Effizienz von MEGALODON bei der Modellierung langer Kontextsequenzen zu bewerten, erweitert dieser Artikel MEGALODON auf eine Skala von 7 Milliarden.
 LLM-Vortraining
LLM-Vortraining
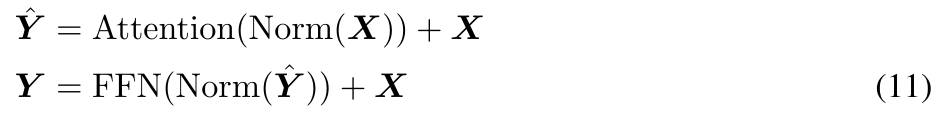 Um die Dateneffizienz zu verbessern, zeigten die Forscher während des Trainingsprozesses die negative Log Likelihood (NLL) von MEGALODON-7B, LLAMA2-7B und LLAMA2-13B, wie in Abbildung 1 dargestellt.
Um die Dateneffizienz zu verbessern, zeigten die Forscher während des Trainingsprozesses die negative Log Likelihood (NLL) von MEGALODON-7B, LLAMA2-7B und LLAMA2-13B, wie in Abbildung 1 dargestellt.
Unter der gleichen Anzahl an Trainingstokens erreichte MEGALODON-7B eine deutlich bessere (niedrigere) NLL als LLAMA2-7B und zeigte eine bessere Dateneffizienz.
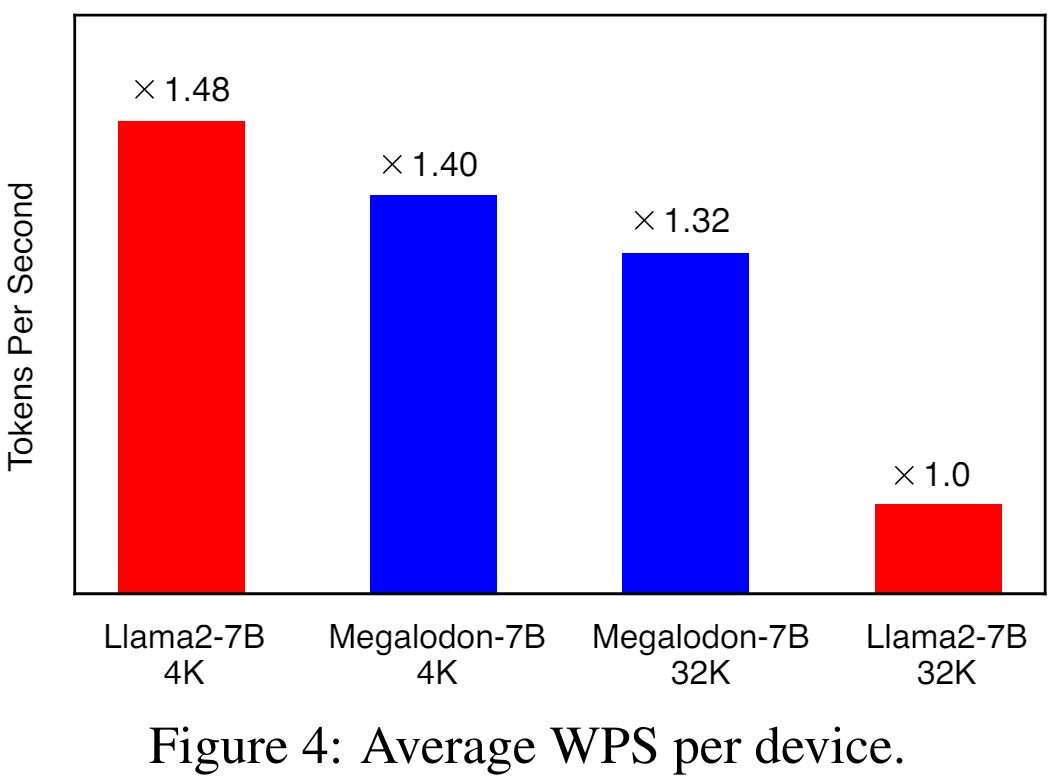
Abbildung 4 zeigt die durchschnittliche WPS (Wort/Token pro Sekunde) pro Gerät für LLAMA2-7B und MEGALODON-7B unter Verwendung von 4K bzw. 32K Kontextlängen. Für das LLAMA2-Modell nutzt die Studie Flash-Attention V2, um die Berechnung der vollen Aufmerksamkeit zu beschleunigen. Bei einer Kontextlänge von 4K ist MEGALODON-7B aufgrund der Einführung von CEMA und der Zeitschrittnormalisierung etwas langsamer (~6 %) als LLAMA2-7B. Bei der Erweiterung der Kontextlänge auf 32 KB ist MEGALODON-7B deutlich schneller als LLAMA2-7B (ca. 32 %), was die Recheneffizienz von MEGALODON für das Vortraining mit langen Kontexten demonstriert.
Kurze Kontextbewertung
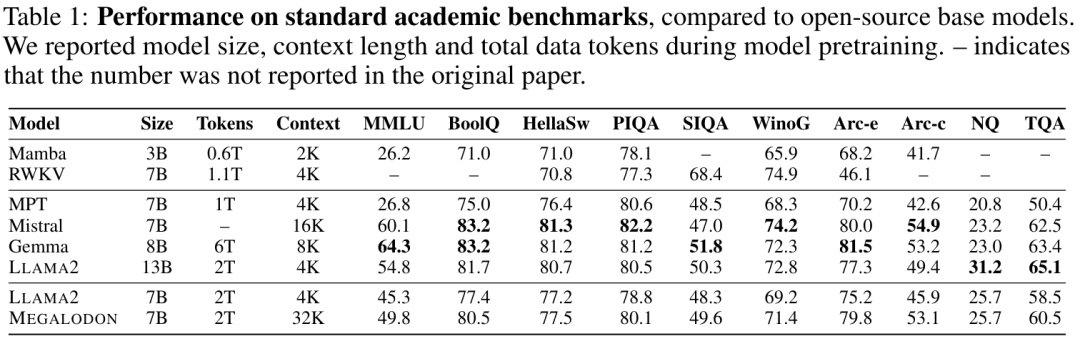
Tabelle 1 fasst die Ergebnisse von MEGALODON und LLAMA2 bei akademischen Benchmarks sowie die Vergleichsergebnisse anderer Open-Source-Basismodelle, einschließlich MPT, RWKV, Mamba, Mistral und Gemma, zusammen. Nach dem Vortraining mit denselben 2T-Tokens übertrifft MEGALODON-7B LLAMA2-7B in allen Benchmarks. Bei einigen Aufgaben ist die Leistung von MEGALODON-7B mit der von LLAMA2-13B vergleichbar oder sogar besser.
Auswertung des langen Kontexts
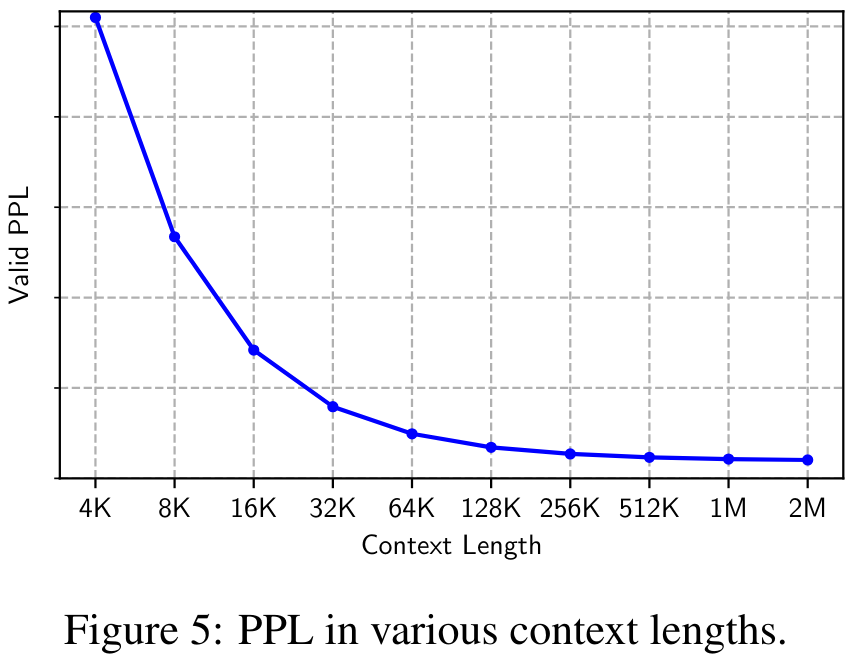
Abbildung 5 zeigt die Perplexität (PPL) des Validierungsdatensatzes unter verschiedenen Kontextlängen von 4K bis 2M. Es ist zu beobachten, dass der PPL monoton mit der Kontextlänge abnimmt, was die Wirksamkeit und Robustheit von MEGALODON bei der Modellierung extrem langer Sequenzen bestätigt.
Feinabstimmung der Anleitung
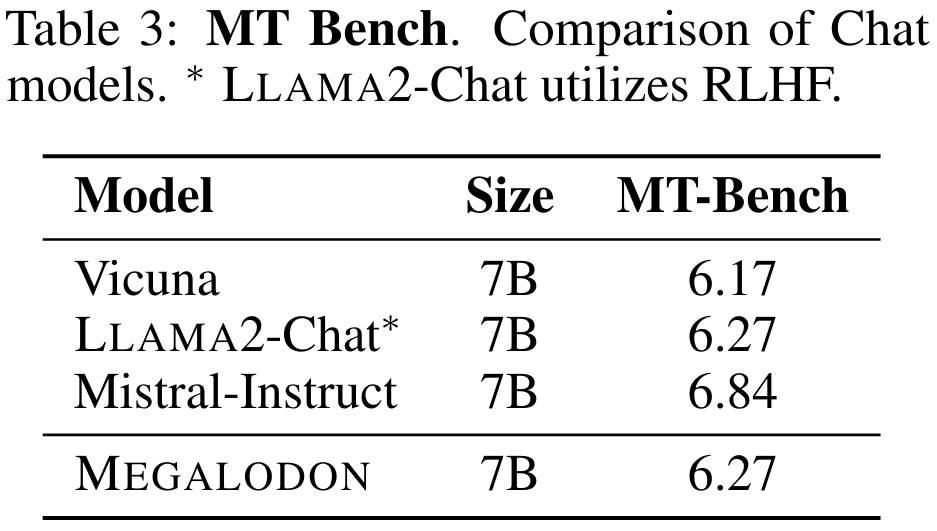
Tabelle 3 fasst die Leistung des 7B-Modells auf MT-Bench zusammen. MEGALODON zeigt auf MT-Bench eine überlegene Leistung im Vergleich zu Vicuna und ist vergleichbar mit LLAMA2-Chat, das RLHF zur weiteren Feinabstimmung der Ausrichtung nutzt.
Benchmark-Bewertung im mittleren Maßstab
Um die Leistung von MEGALODON bei Bildklassifizierungsaufgaben zu bewerten, führte die Studie Experimente mit dem Imagenet-1K-Datensatz durch. Tabelle 4 gibt die Top-1-Genauigkeit des Validierungssatzes an. Die Genauigkeit von MEGALODON ist 1,3 % höher als die von DeiT-B und 0,8 % höher als die von MEGA.
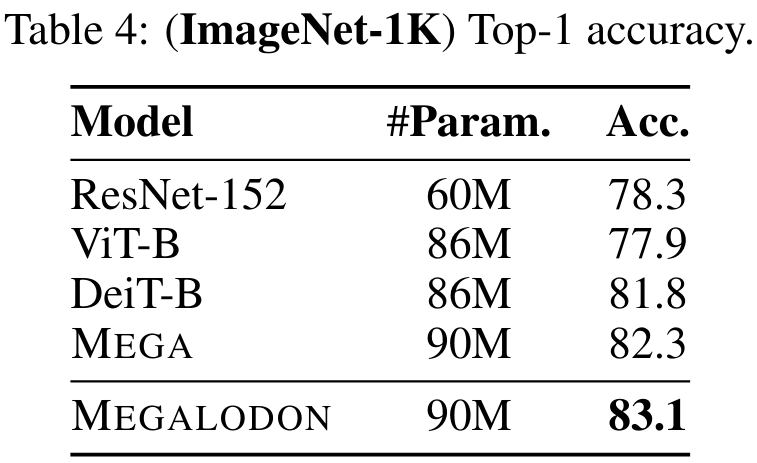
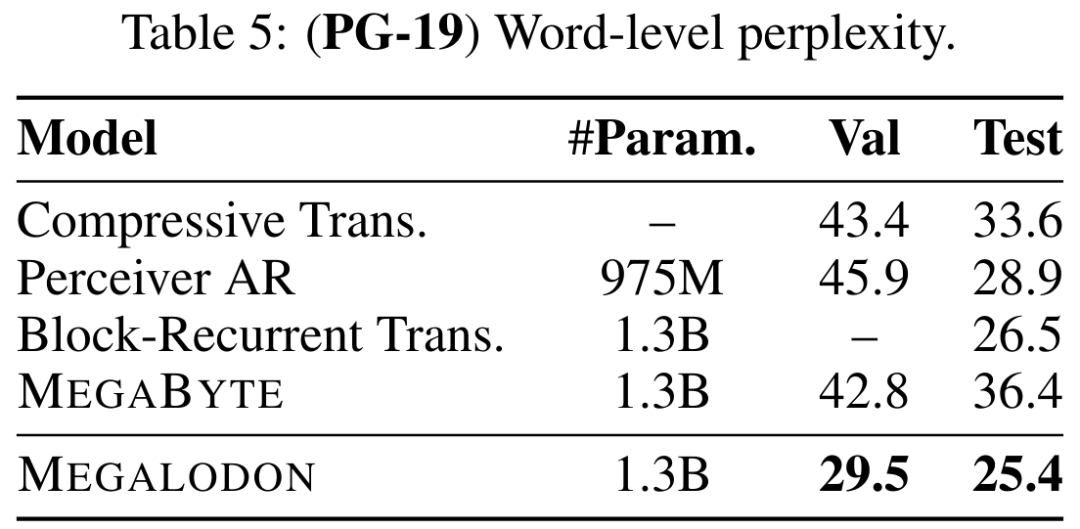
Tabelle 5 veranschaulicht die Wortebenenperplexität (PPL) von MEGALODON auf PG-19 und den Vergleich mit früheren Modellen auf dem neuesten Stand der Technik, einschließlich Compressive Transformer, Perceiver AR, Perceiver AR und Block Loop Transformer und MEGABYTE usw. . Die Leistung von MEGALODON liegt klar vorn.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonMeta unbegrenztes Langtext-Großmodell ist da: nur 7B Parameter, Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Mobile Festplattenpartitionssoftware
Mobile Festplattenpartitionssoftware
 Linux Systeminformationen anzeigen
Linux Systeminformationen anzeigen

























