Durch die Einführung der Hybridtiefe kann das neue Design von DeepMind die Transformer-Effizienz erheblich verbessern.
Die Bedeutung von Transformer liegt auf der Hand. Derzeit arbeiten viele Forschungsteams an der Verbesserung dieser revolutionären Technologie. Eine der wichtigen Verbesserungsrichtungen besteht darin, die Effizienz von Transformer zu verbessern, beispielsweise durch die Ausstattung mit adaptiven Rechenfunktionen Dies erspart unnötige Berechnungen. Wie Illiya Polosukhin, einer der Vorreiter der Transformer-Architektur und Mitbegründer des NEAR-Protokolls, vor nicht allzu langer Zeit in einem Gespräch mit Jen-Hsun Huang sagte: „Adaptives Computing muss als nächstes erscheinen. Wir müssen.“ Achten Sie insbesondere darauf, wie viele Rechenressourcen für das Problem aufgewendet werden? .  Das Gleiche sollte für die Sprachmodellierung gelten. Um genaue Vorhersageergebnisse zu erhalten, ist es nicht notwendig, für alle Token und Sequenzen die gleiche Zeit oder Ressourcen zu investieren. Das Transformer-Modell verbraucht jedoch für jeden Token in einem Vorwärtsdurchlauf den gleichen Rechenaufwand. Das lässt die Leute jammern: Die meisten Berechnungen sind Verschwendung! Wenn Sie unnötige Berechnungen nicht durchführen können, können Sie im Idealfall das Rechenbudget des Transformers reduzieren. Bedingte Berechnung ist eine Technik, die Berechnungen nur dann durchführt, wenn sie benötigt werden, wodurch die Gesamtzahl der Berechnungen reduziert wird. Viele Forscher haben bereits verschiedene Algorithmen vorgeschlagen, die auswerten können, wann Berechnungen durchgeführt werden und wie viele Berechnungen verwendet werden. Allerdings kommen häufig verwendete Lösungsformen für dieses anspruchsvolle Problem möglicherweise nicht gut mit bestehenden Hardwareeinschränkungen zurecht, da sie dazu neigen, dynamische Berechnungsdiagramme einzuführen. Stattdessen könnten die vielversprechendsten bedingten Berechnungsmethoden diejenigen sein, die konsequent den aktuellen Hardware-Stack nutzen und der Verwendung statischer Berechnungsgraphen und bekannten Tensorgrößen, die auf der Grundlage der maximalen Auslastung der Hardware ausgewählt werden, Vorrang einräumen. Kürzlich hat Google DeepMind dieses Problem untersucht. Sie hoffen, mit einem geringeren Rechenbudget den Rechenaufwand von Transformer zu reduzieren. Titel des Papiers: Mixture-of-Depths: Dynamische Zuordnung von Rechenleistung in transformatorbasierten Sprachmodellen
Das Gleiche sollte für die Sprachmodellierung gelten. Um genaue Vorhersageergebnisse zu erhalten, ist es nicht notwendig, für alle Token und Sequenzen die gleiche Zeit oder Ressourcen zu investieren. Das Transformer-Modell verbraucht jedoch für jeden Token in einem Vorwärtsdurchlauf den gleichen Rechenaufwand. Das lässt die Leute jammern: Die meisten Berechnungen sind Verschwendung! Wenn Sie unnötige Berechnungen nicht durchführen können, können Sie im Idealfall das Rechenbudget des Transformers reduzieren. Bedingte Berechnung ist eine Technik, die Berechnungen nur dann durchführt, wenn sie benötigt werden, wodurch die Gesamtzahl der Berechnungen reduziert wird. Viele Forscher haben bereits verschiedene Algorithmen vorgeschlagen, die auswerten können, wann Berechnungen durchgeführt werden und wie viele Berechnungen verwendet werden. Allerdings kommen häufig verwendete Lösungsformen für dieses anspruchsvolle Problem möglicherweise nicht gut mit bestehenden Hardwareeinschränkungen zurecht, da sie dazu neigen, dynamische Berechnungsdiagramme einzuführen. Stattdessen könnten die vielversprechendsten bedingten Berechnungsmethoden diejenigen sein, die konsequent den aktuellen Hardware-Stack nutzen und der Verwendung statischer Berechnungsgraphen und bekannten Tensorgrößen, die auf der Grundlage der maximalen Auslastung der Hardware ausgewählt werden, Vorrang einräumen. Kürzlich hat Google DeepMind dieses Problem untersucht. Sie hoffen, mit einem geringeren Rechenbudget den Rechenaufwand von Transformer zu reduzieren. Titel des Papiers: Mixture-of-Depths: Dynamische Zuordnung von Rechenleistung in transformatorbasierten Sprachmodellen
- Adresse des Papiers: https://arxiv.org/pdf/2404.02258.pdf
Sie stellen sich vor: In jeder Schicht muss das Netzwerk lernen, Entscheidungen für jeden Token zu treffen und dadurch das verfügbare Rechenbudget dynamisch zuzuweisen. In ihrer spezifischen Implementierung wird der gesamte Rechenaufwand vom Benutzer vor dem Training festgelegt und nie geändert, sondern ist eine Funktion der Entscheidungen, die während des Netzwerkbetriebs getroffen werden. Dadurch können Hardware-Effizienzgewinne (z. B. geringerer Speicherbedarf oder geringere FLOPs pro Vorwärtsdurchlauf) vorhergesehen und genutzt werden. Die Experimente des Teams zeigen, dass diese Gewinne erzielt werden können, ohne die Gesamtleistung des Netzwerks zu beeinträchtigen.
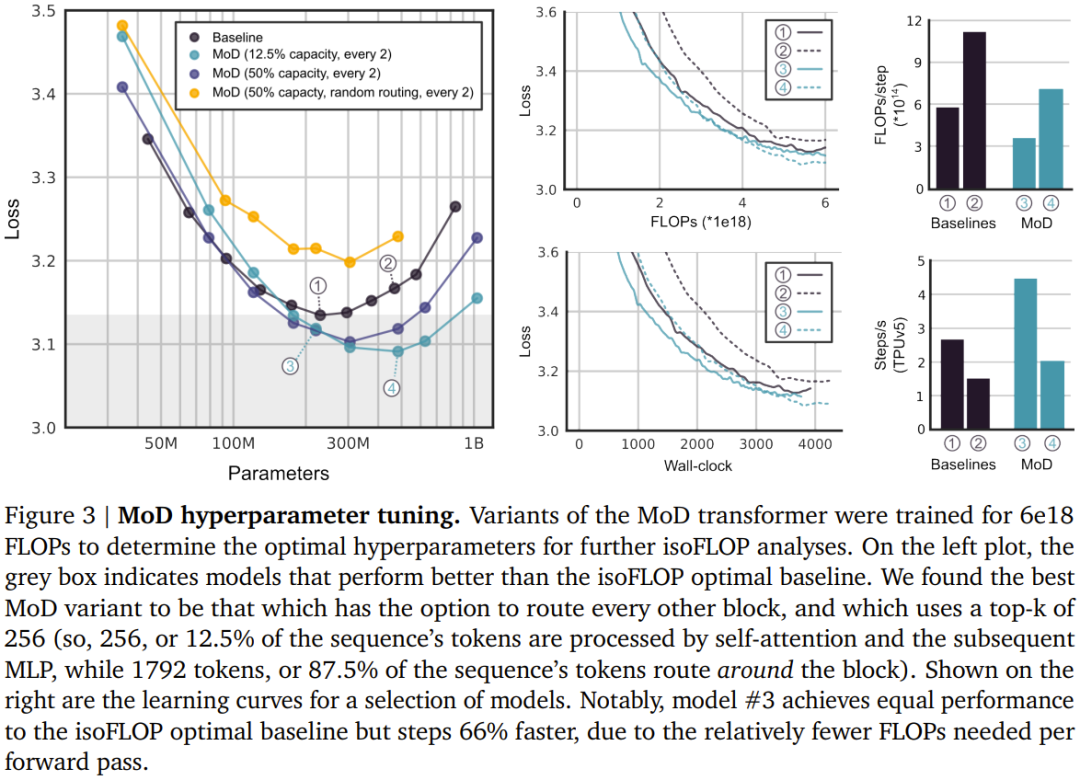
Dieses Team bei DeepMind verfolgt einen Ansatz ähnlich dem Mixed Expert (MoE) Transformer, bei dem dynamische Routing-Entscheidungen auf Token-Ebene über die gesamte Netzwerktiefe durchgeführt werden. Im Gegensatz zu MoE haben sie hier die Wahl: entweder die Berechnung auf den Token anwenden (wie beim Standard-Transformer) oder sie durch eine Restverbindung umgehen (gleich bleiben, Berechnung speichern). Ein weiterer Unterschied zu MoE besteht darin, dass dieser Routing-Mechanismus sowohl für MLP als auch für Multi-Head-Aufmerksamkeit verwendet wird. Daher wirkt sich dies auch auf die vom Netzwerk verarbeiteten Schlüssel und Abfragen aus, sodass die Route nicht nur entscheidet, welche Token aktualisiert werden, sondern auch, welche Token zur Bearbeitung verfügbar sind. DeepMind nannte diese Strategie Mixture-of-Depths (MoD), um die Tatsache hervorzuheben, dass jeder Token eine unterschiedliche Anzahl von Schichten oder Modulen in der Transformer-Tiefe durchläuft. Wir übersetzen es hier mit „Mischtiefe“, siehe Abbildung 1. MoD unterstützt Benutzer dabei, Leistung und Geschwindigkeit abzuwägen. Einerseits können Benutzer den MoD Transformer mit denselben Trainings-FLOPs wie einen regulären Transformer trainieren, was zu einer Verbesserung des endgültigen Trainingsziels für die Log-Wahrscheinlichkeit um bis zu 1,5 % führen kann.Der MoD Transformer hingegen benötigt weniger Rechenaufwand, um den gleichen Trainingsverlust wie der reguläre Transformer zu erzielen – bis zu 50 % weniger FLOPs pro Vorwärtsdurchlauf. Diese Ergebnisse zeigen, dass MoD Transformer lernen kann, intelligent zu routen (d. h. unnötige Berechnungen zu überspringen). Implementierung des Mixed Depth (MoD) Transformer Zusammenfassend lautet die Strategie wie folgt:
- Legen Sie ein statisches Rechenbudget fest, das niedriger ist als der entsprechende herkömmliche Betrag Die von Transformer benötigte Berechnung besteht darin, die Anzahl der Token in der Sequenz zu begrenzen, die an Modulberechnungen teilnehmen können (z. B. Selbstaufmerksamkeitsmodul und nachfolgendes MLP). Beispielsweise kann ein regulärer Transformer zulassen, dass alle Token in der Sequenz an Selbstaufmerksamkeitsberechnungen teilnehmen, der MoD-Transformer kann jedoch die Verwendung von nur 50 % der Token in der Sequenz beschränken.
- Für jeden Token gibt es in jedem Modul einen Routing-Algorithmus, der eine skalare Gewichtung angibt; diese Gewichtung stellt die Routing-Präferenz für jeden Token dar – ob er an der Berechnung des Moduls teilnimmt oder diese umgeht.
- Finden Sie in jedem Modul die obersten k größten Skalargewichte, und ihre entsprechenden Token nehmen an der Berechnung des Moduls teil. Da nur k Token an der Berechnung dieses Moduls teilnehmen müssen, sind sein Berechnungsdiagramm und seine Tensorgröße während des Trainingsprozesses statisch. Diese Token sind dynamische und kontextbezogene Token, die vom Routing-Algorithmus erkannt werden.
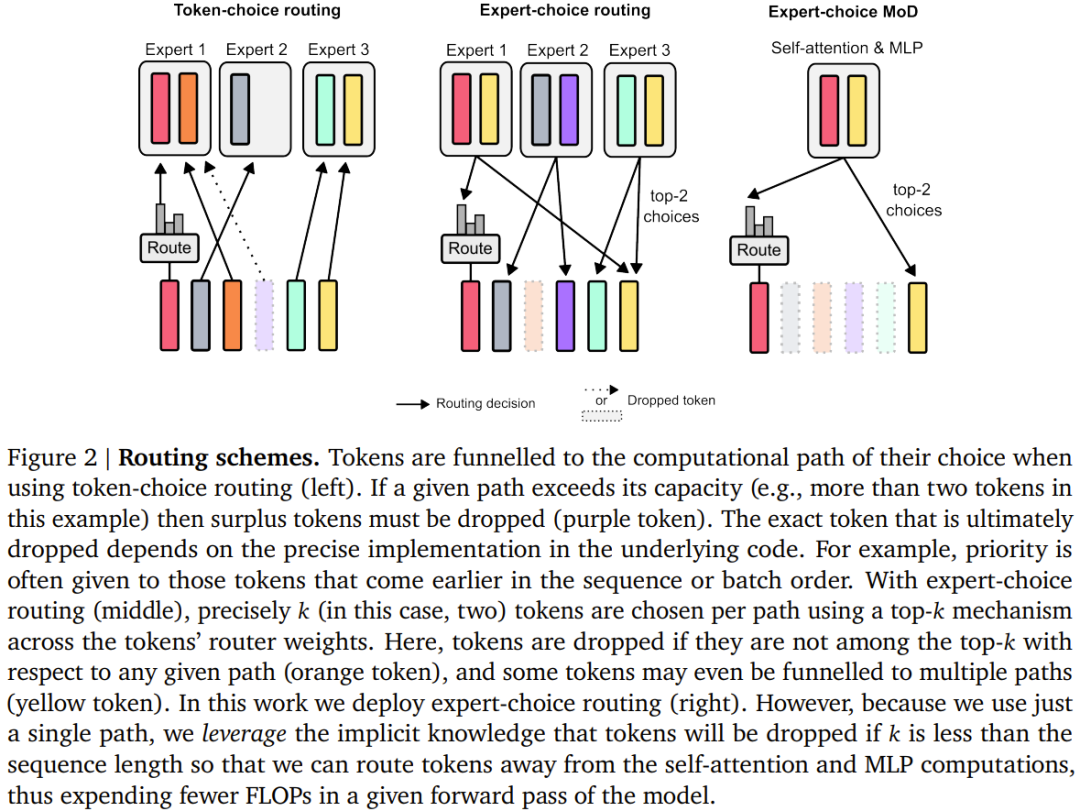
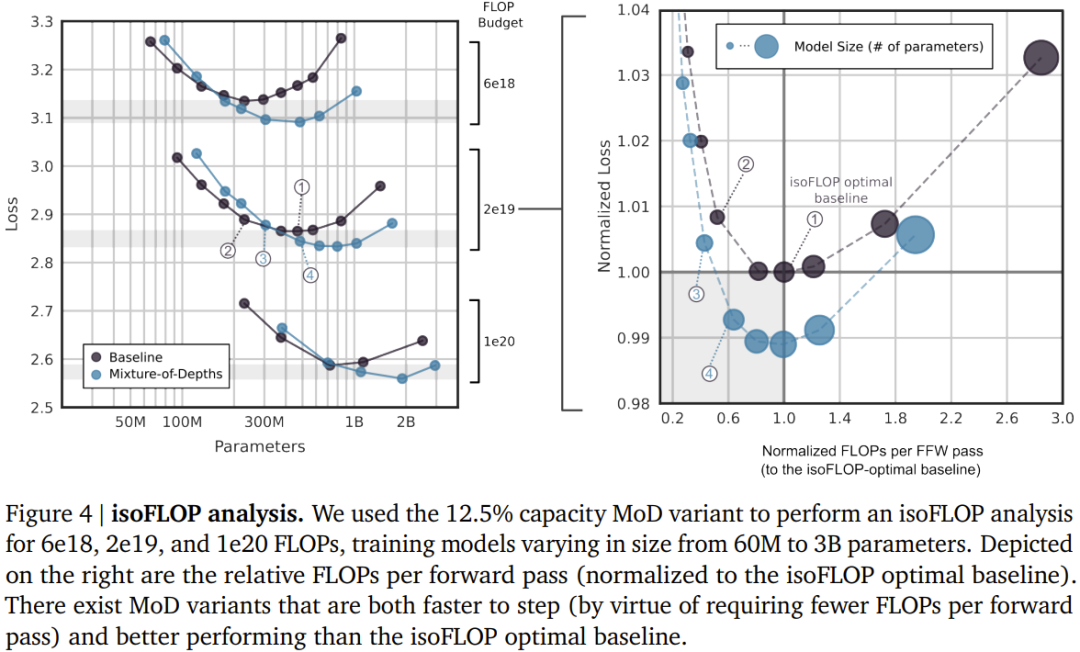
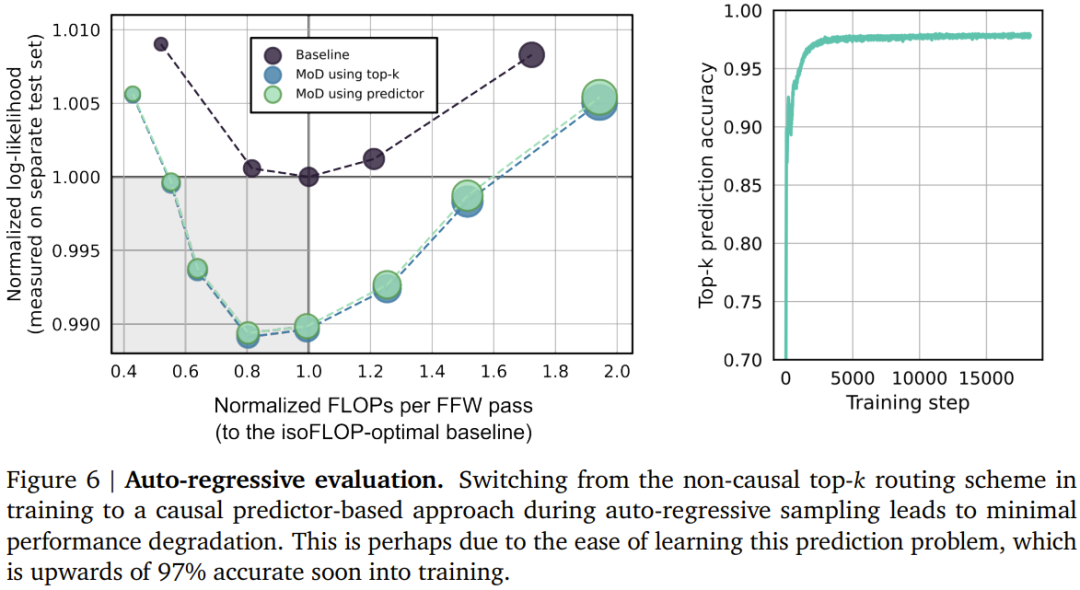
Das Team berücksichtigte zwei erlernte Routing-Schemata (siehe Abbildung 2): Token-Auswahl und Expertenauswahl. Im Token-selektiven Routing-Schema generiert der Routing-Algorithmus eine Wahrscheinlichkeitsverteilung für jedes Token über Rechenpfade hinweg (z. B. über Expertenidentitäten in MoE Transformer). Die Token werden dann an ihren bevorzugten Pfad gesendet (d. h. den Pfad mit der höchsten Wahrscheinlichkeit), und der Hilfsverlust stellt sicher, dass nicht alle Token auf demselben Pfad konvergieren. Beim Token-selektiven Routing kann es zu Lastausgleichsproblemen kommen, da nicht sichergestellt ist, dass die Token richtig auf die möglichen Pfade verteilt werden. Expert Selective Routing kehrt das obige Schema um: Anstatt Token ihre bevorzugten Pfade auswählen zu lassen, wählt jeder Pfad die obersten k Token (top-k) basierend auf den Token-Präferenzen aus. Dies gewährleistet einen perfekten Lastausgleich, da jedem Pfad immer k Token garantiert sind. Dies kann jedoch auch dazu führen, dass einige Token über- oder unterverarbeitet werden, da sich einige Token möglicherweise im obersten k mehrerer Pfade befinden und andere Token möglicherweise keinen entsprechenden Pfad haben. DeepMind hat sich aus drei Gründen für die Expertenauswahlweiterleitung entschieden. Erstens ist kein zusätzlicher Gleichgewichtsverlust erforderlich. Zweitens: Da die Auswahl des obersten k von der Größe des Routing-Gewichts abhängt, ermöglicht dieses Routing-Schema die Verwendung relativer Routing-Gewichte, wodurch ermittelt werden kann, welche Token für die aktuelle Modulberechnung am meisten benötigt werden Der Routing-Algorithmus kann die Gewichtung entsprechend festlegen, um sicherzustellen, dass der kritischste Token zu den obersten k gehört – das ist etwas, was das Token-selektive Routing-Schema nicht kann. Im konkreten Anwendungsfall gibt es einen Berechnungspfad, der im Wesentlichen eine Nulloperation ist, sodass die Weiterleitung wichtiger Token an Null vermieden werden sollte. Drittens kann eine einzelne Top-k-Operation das Token effizient in zwei sich gegenseitig ausschließende Sätze (einen Satz für jeden Berechnungspfad) aufteilen, da das Routing nur über zwei Pfade erfolgt. oder Unterverarbeitungsprobleme. Informationen zur konkreten Umsetzung dieses Routing-Schemas finden Sie im Originalpapier. Obwohl expertenselektives Routing viele Vorteile hat, weist es auch ein offensichtliches Problem auf: Top-k-Operationen sind akausal. Das heißt, ob die Routing-Gewichtung eines bestimmten Tokens im oberen k liegt, hängt vom Wert der Routing-Gewichtung danach ab, aber wir können diese Gewichte nicht erhalten, wenn wir eine autoregressive Stichprobe durchführen. Um dieses Problem zu lösen, testete das Team zwei Methoden. Die erste besteht darin, eine einfache Hilfsverlustpraxis einzuführen. Sie hat gezeigt, dass ihr Einfluss auf das Hauptziel der Sprachmodellierung 0,2 % bis 0,3 % beträgt, sie ermöglicht dem Modell jedoch eine autoregressive Stichprobe. Sie verwendeten einen binären Kreuzentropieverlust, bei dem die Ausgabe des Routing-Algorithmus den Logit liefert und durch Auswahl des Top-k dieser Logits das Ziel bereitgestellt werden kann (d. h. 1, wenn sich ein Token im Top-k befindet, andernfalls). 0).Die zweite Methode besteht darin, einen kleinen Hilfs-MLP-Prädiktor einzuführen (genau wie ein anderer Routing-Algorithmus), dessen Eingabe mit der des Routing-Algorithmus (mit Stoppgradienten) identisch ist, dessen Ausgabe jedoch ein Vorhersageergebnis ist: Token Ob es sich im Top-k der Sequenz befindet. Dieser Ansatz hat keinen Einfluss auf die Ziele der Sprachmodellierung und Experimente zeigen, dass er die Geschwindigkeit dieses Schritts nicht wesentlich beeinflusst. Mit diesen neuen Methoden ist es möglich, ein autoregressives Sampling durchzuführen, indem der Token ausgewählt wird, an den weitergeleitet werden soll, oder ein Modul basierend auf der Ausgabe des Routing-Algorithmus zu umgehen, ohne auf Informationen über zukünftige Token angewiesen zu sein. Experimentelle Ergebnisse zeigen, dass es sich hierbei um eine relativ einfache Hilfsaufgabe handelt, mit der schnell eine Genauigkeit von 99 % erreicht werden kann. ?? . Insgesamt können Sie sehen, dass der MoD Transformer die Basislinie der isoFLOP-Kurve nach rechts unten zieht. Mit anderen Worten: Der optimale MoD-Transformator hat einen geringeren Verlust als das optimale Basismodell und verfügt außerdem über mehr Parameter. Dieser Effekt hat eine glückliche Konsequenz: Es gibt MoD-Modelle, die genauso gut oder besser funktionieren als das optimale Basismodell (während sie in Schritten schneller sind), obwohl sie selbst unter ihren Hyperparametereinstellungen nicht isoFLOP-optimal sind. Beispielsweise ist eine MoD-Variante mit 220 Mio. Parametern (Modell Nr. 3 in Abbildung 3) etwas besser als das optimale Basislinienmodell von isoFLOP (ebenfalls 220 Mio. Parameter, Modell Nr. 1 in Abbildung 3), diese MoD-Variante weist jedoch Schritte während des Trainings auf über 60 % schneller. Abbildung 4 unten zeigt die isoFLOP-Analyse, wenn die gesamten FLOPs 6e18, 2e19 und 1e20 betragen. Wie man sieht, setzt sich der Trend fort, wenn das FLOP-Budget größer ist.
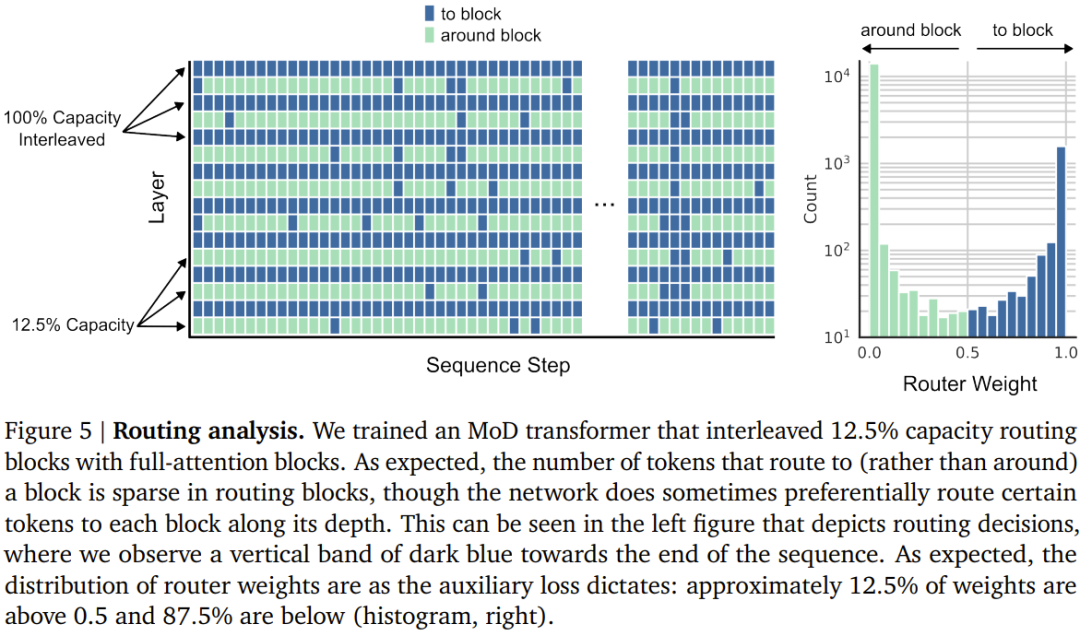
Abbildung 5 unten zeigt die Routing-Entscheidung eines MoD-Transformers, der mit dem Interleaved-Routing-Modul trainiert wurde. Trotz der großen Anzahl an Modulbypässen erreicht dieser MoD Transformer immer noch eine bessere Leistung als der reguläre Transformer.
 Autoregressive Bewertung
Autoregressive BewertungSie bewerteten auch die autoregressive Stichprobenleistung von MoD-Varianten. Die Ergebnisse sind in Abbildung 6 unten dargestellt. Diese Ergebnisse zeigen, dass die durch den MoD Transformer erzielten Recheneinsparungen nicht auf die Trainingsumgebung beschränkt sind.
Mixed Depth and Expertise (MoDE) MoD-Technologie kann auf natürliche Weise in MoE-Modelle integriert werden, um sogenannte MoDE-Modelle zu bilden. Abbildung 7 unten zeigt MoDE und die damit verbundenen Verbesserungen. MoDE gibt es in zwei Varianten: Staged MoDE und Integrated MoDE.
Das abgestufte MoDE dient dazu, Routing-Bypass- oder Reach-Token-Operationen vor dem Selbstaufmerksamkeitsschritt durchzuführen, während das integrierte MoDE das MoD-Routing durch die Integration von „No-Operation“-Experten zwischen regulären MLP-Experten implementiert. Der Vorteil des ersteren besteht darin, dass Token den Schritt der Selbstaufmerksamkeit überspringen können, während der Vorteil des letzteren darin besteht, dass der Routing-Mechanismus einfach ist.
Das Team stellte fest, dass die integrierte Implementierung von MoDE deutlich besser ist, als die Fähigkeit von Experten direkt zu reduzieren und sich auf das Verwerfen von Token zu verlassen, um Restrouting-Designs zu implementieren.
Das obige ist der detaillierte Inhalt vonDeepMind rüstet Transformer auf, Vorwärtspass-FLOPs können um bis zur Hälfte reduziert werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 So richten Sie die Domänennamenumleitung ein
So richten Sie die Domänennamenumleitung ein
 Welche Datenkonvertierungsmethoden gibt es in Golang?
Welche Datenkonvertierungsmethoden gibt es in Golang?
 Was ist LAN?
Was ist LAN?












