


Originaltitel: Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Link zum Papier: https://arxiv.org/pdf/2404.04804.pdf
Autorenzugehörigkeit: Cleveland State University University of Texas at Austin A*STAR New York University, University of California, Los Angeles

LightDiff ist eine Technologie, die die Effizienz und Skalierbarkeit des visuellen Zentrumswahrnehmungssystems des autonomen Fahrens verbessert. LiDAR-Systeme haben in letzter Zeit große Aufmerksamkeit erhalten. Allerdings treten bei diesen Systemen bei schlechten Lichtverhältnissen häufig Probleme auf, die möglicherweise ihre Leistung und Sicherheit beeinträchtigen. Um dieses Problem zu lösen, stellt dieser Artikel LightDiff vor, ein automatisiertes Framework, das die Bildqualität bei schlechten Lichtverhältnissen in autonomen Fahranwendungen verbessern soll. Insbesondere wird in diesem Artikel ein Modell mit kontrollierter Diffusion unter mehreren Bedingungen verwendet. LightDiff macht die manuelle Erfassung paarweiser Daten überflüssig und nutzt stattdessen einen dynamischen Datenverschlechterungsprozess. Es enthält einen neuartigen Multibedingungsadapter, der in der Lage ist, Eingabegewichte aus verschiedenen Modalitäten, einschließlich Tiefenkarten, RGB-Bildern und Textbeschriftungen, adaptiv zu steuern, um gleichzeitig die Inhaltskonsistenz bei schlechten Lichtverhältnissen und bei schlechten Lichtverhältnissen aufrechtzuerhalten. Um die erweiterten Bilder mit dem Wissen des Erkennungsmodells abzugleichen, verwendet LightDiff außerdem perzeptronspezifische Bewertungen als Belohnungen, um den Diffusionstrainingsprozess durch verstärkendes Lernen zu steuern. Umfangreiche Experimente mit dem nuScenes-Datensatz zeigen, dass LightDiff die Leistung mehrerer hochmoderner 3D-Detektoren bei Nachtbedingungen deutlich verbessern und gleichzeitig hohe visuelle Qualitätswerte erzielen kann, was sein Potenzial zur Gewährleistung der Sicherheit beim autonomen Fahren unterstreicht.
In diesem Artikel wird das Lighting Diffusion (LightDiff)-Modell vorgeschlagen, um Kamerabilder bei schlechten Lichtverhältnissen beim autonomen Fahren zu verbessern, wodurch die Notwendigkeit einer umfangreichen Datenerfassung bei Nacht verringert und die Leistungsfähigkeit bei Tag aufrechterhalten wird.
Dieses Papier integriert mehrere Eingabemodi, einschließlich Tiefenkarten und Bildunterschriften, und schlägt einen Adapter mit mehreren Bedingungen vor, um die semantische Integrität bei der Bildkonvertierung sicherzustellen und gleichzeitig eine hohe visuelle Qualität beizubehalten. In diesem Artikel wird ein praktischer Prozess zur Generierung von Tag- und Nachtbildpaaren aus Tagesdaten angewendet, um ein effizientes Modelltraining zu erreichen.
In diesem Artikel wird ein Feinabstimmungsmechanismus vorgestellt, der Verstärkungslernen verwendet und mit wahrnehmungsbezogen angepasstem Domänenwissen (glaubwürdiges LIDAR und Konsistenz statistischer Verteilungen) kombiniert wird, um sicherzustellen, dass der Diffusionsprozess eine Stärke aufweist, die der visuellen Wahrnehmung des Menschen förderlich ist und die Wahrnehmungsleistung des Modells nutzt Wahrnehmungsmodellierung. Diese Methode hat erhebliche Vorteile für die visuelle Wahrnehmung des Menschen und verfügt auch über die Vorteile von Wahrnehmungsmodellen.
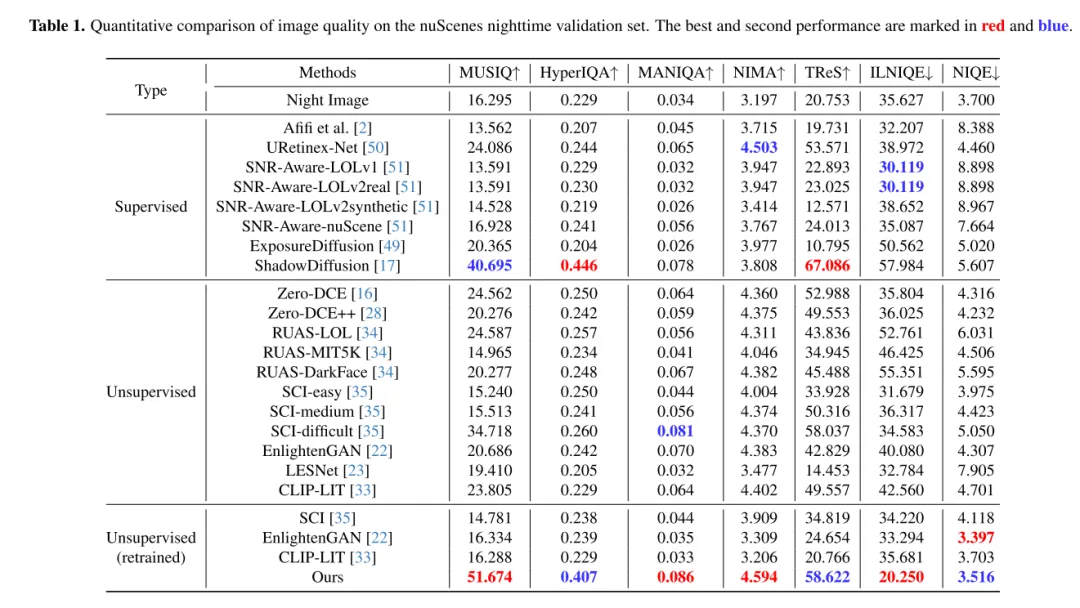
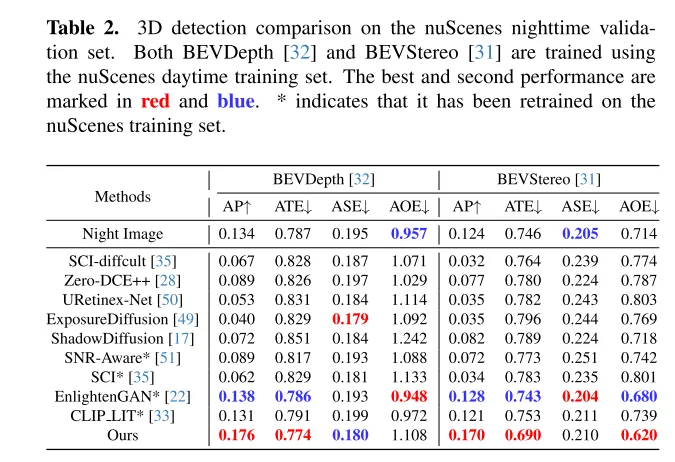
Umfangreiche Experimente mit dem nuScenes-Datensatz zeigen, dass LightDiff die Leistung der 3D-Fahrzeugerkennung bei Nacht erheblich verbessert und andere generative Modelle bei mehreren Betrachtungswinkelmetriken übertrifft.
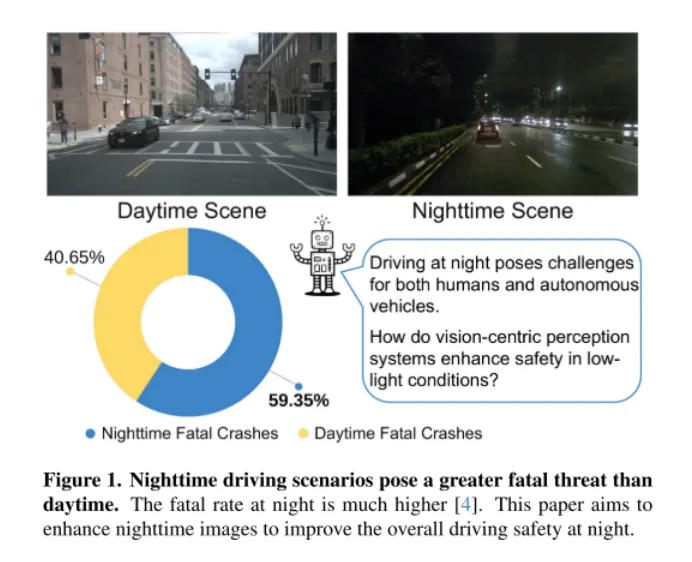
Abbildung 1. Nachtfahrten sind tödlicher als tagsüber. Nachts ist die Todesrate deutlich höher [4]. Ziel dieses Artikels ist es, Nachtbilder zu verbessern, um die allgemeine Sicherheit beim Nachtfahren zu verbessern.
Wie in Abbildung 1 dargestellt, ist Nachtfahren eine Herausforderung für Menschen, insbesondere für selbstfahrende Autos. Diese Herausforderung wurde durch einen katastrophalen Vorfall am 18. März 2018 deutlich, als ein selbstfahrendes Auto der Uber Advanced Technologies Group in Arizona einen Fußgänger anfuhr und tötete [37]. Der Vorfall, der dadurch verursacht wurde, dass das Fahrzeug einen Fußgänger bei schlechten Lichtverhältnissen nicht genau erkannte, hat Sicherheitsfragen für autonome Fahrzeuge in den Vordergrund gerückt, insbesondere in solch anspruchsvollen Umgebungen. Da visionszentrierte autonome Fahrsysteme zunehmend auf Kamerasensoren angewiesen sind, wird die Berücksichtigung von Sicherheitsbedenken bei schlechten Lichtverhältnissen immer wichtiger, um die Gesamtsicherheit dieser Fahrzeuge zu gewährleisten.
Eine intuitive Lösung besteht darin, große Mengen an Nachtfahrdaten zu sammeln. Diese Methode ist jedoch nicht nur arbeitsintensiv und kostspielig, sondern kann aufgrund der unterschiedlichen Bildverteilung zwischen Nacht und Tag auch die Leistung des Tagesmodells beeinträchtigen. Um diese Herausforderungen anzugehen, schlägt dieses Papier das Lighting Diffusion (LightDiff)-Modell vor, einen neuartigen Ansatz, der die manuelle Datenerfassung überflüssig macht und die Leistung des Modells tagsüber aufrechterhält.
Das Ziel vonLightDiff besteht darin, Kamerabilder bei schlechten Lichtverhältnissen zu verbessern und die Leistung von Wahrnehmungsmodellen zu verbessern. Mithilfe eines dynamischen Dämpfungsprozesses bei schwachem Licht generiert LightDiff synthetische Tag-Nacht-Bildpaare für das Training aus vorhandenen Tagesdaten. Als nächstes wird in diesem Artikel die Stable Diffusion-Technologie [44] verwendet, da sie in der Lage ist, hochwertige visuelle Effekte zu erzeugen, die Nachtszenen effektiv in Tagesäquivalente umwandeln. Allerdings ist die Aufrechterhaltung der semantischen Konsistenz beim autonomen Fahren von entscheidender Bedeutung, was eine Herausforderung für das ursprüngliche Stable Diffusion-Modell darstellte. Um dieses Problem zu lösen, kombiniert LightDiff mehrere Eingabemodalitäten, wie geschätzte Tiefenkarten und Kamerabildunterschriften, mit einem Multi-Bedingungs-Adapter. Dieser Adapter bestimmt auf intelligente Weise die Gewichtung jeder Eingabemodalität und gewährleistet so die semantische Integrität des konvertierten Bildes bei gleichzeitiger Beibehaltung einer hohen visuellen Qualität. Um den Diffusionsprozess nicht nur in Richtung einer höheren Helligkeit für das menschliche Sehvermögen, sondern auch für Wahrnehmungsmodelle zu lenken, verwendet dieser Artikel zusätzlich Verstärkungslernen, um den LightDiff dieses Artikels zu verfeinern, und fügt der Schleife Domänenwissen hinzu, das auf die Wahrnehmung zugeschnitten ist. In diesem Artikel werden umfangreiche Experimente mit dem autonomen Fahrdatensatz nuScenes [7] durchgeführt und gezeigt, dass unser LightDiff die durchschnittliche Genauigkeit (AP) der nächtlichen 3D-Fahrzeugerkennung für zwei hochmoderne Modelle, BEVDepth [32] und BEVStereo, erheblich verbessern kann . [31] verbesserte sich um 4,2 % bzw. 4,6 %.
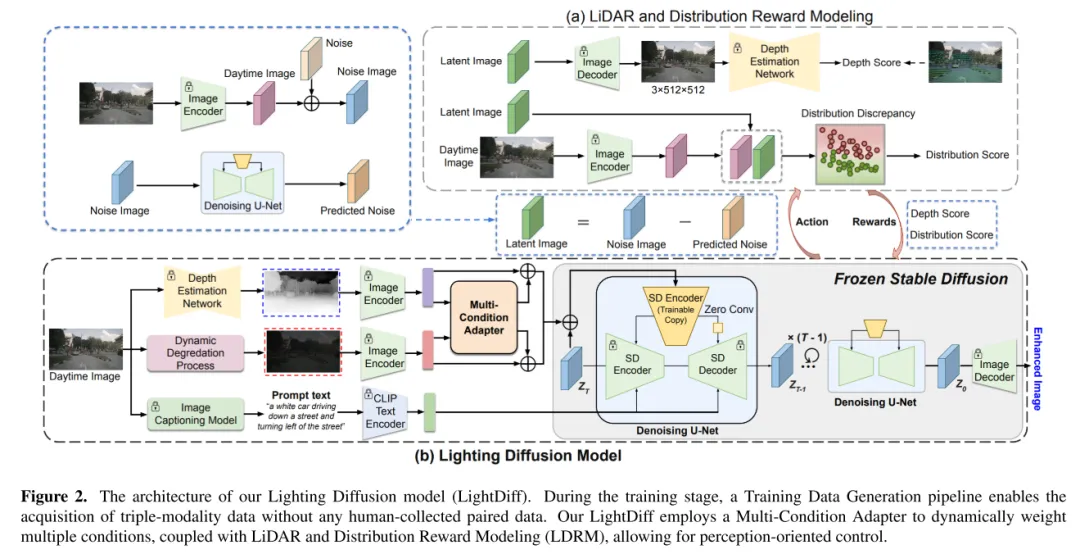
Abbildung 2. Die Architektur des Lighting Diffusion-Modells (LightDiff) in diesem Artikel. Während der Trainingsphase ermöglicht ein Trainingsdatengenerierungsprozess die Erfassung trimodaler Daten ohne manuelle Erfassung gepaarter Daten. LightDiff in diesem Artikel verwendet einen Multi-Bedingungs-Adapter, um mehrere Bedingungen dynamisch zu gewichten, kombiniert mit Lidar und Distributed Reward Modeling (LDRM), was eine wahrnehmungsorientierte Steuerung ermöglicht.
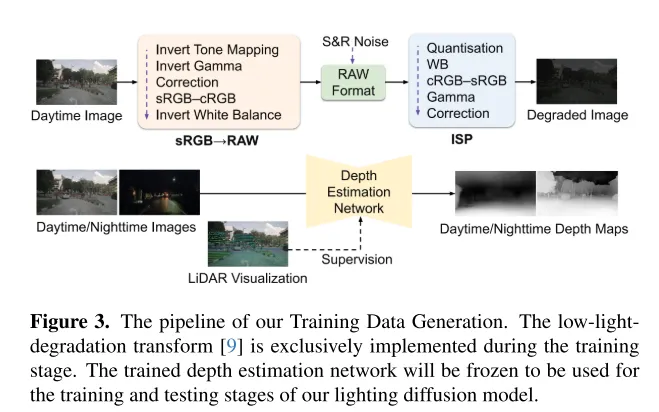
Abbildung 3. Der Prozess zur Generierung von Trainingsdaten in diesem Artikel. Die Degradationstransformation bei schwachem Licht [9] wird nur während der Trainingsphase implementiert. Das trainierte Tiefenschätzungsnetzwerk wird eingefroren und für die Trainings- und Testphasen des Lighting Diffusion-Modells in diesem Artikel verwendet.
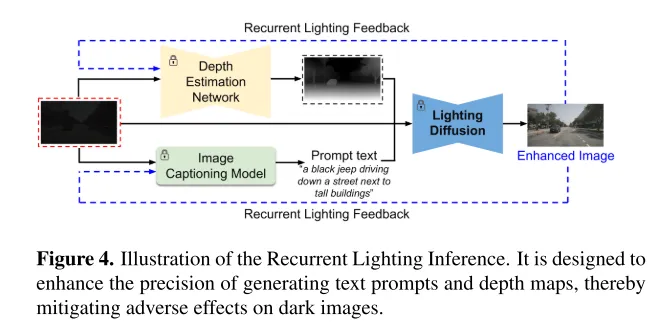
Abbildung 4. Schematische Darstellung der Inferenz wiederkehrender Beleuchtung. Es soll die Genauigkeit der Generierung von Texthinweisen und Tiefenkarten verbessern und so die nachteiligen Auswirkungen dunkler Bilder abmildern.

Abbildung 5. Visueller Vergleich einer Stichprobe von Nachtbildern im nuScenes-Validierungssatz.

Abbildung 6. Visualisierung der 3D-Erkennungsergebnisse auf einem Beispielnachtbild im nuScenes-Validierungssatz. Dieser Artikel verwendet BEVDepth [32] als dreidimensionalen Detektor und visualisiert die Vorderansicht und die Vogelperspektive der Kamera.

Abbildung 7. Zeigt den visuellen Effekt des LightDiff dieses Artikels mit oder ohne MultiCondition-Adapter. Die Eingabe in ControlNet [55] bleibt konsistent, einschließlich der gleichen Texthinweise und Tiefenkarten. Multi-Condition-Adapter ermöglichen einen besseren Farbkontrast und reichere Details während der Verbesserung.
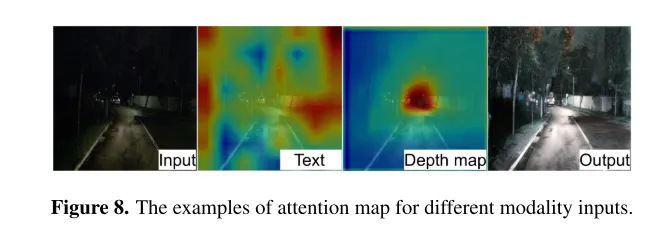
Abbildung 8. Beispiele für Aufmerksamkeitskarten für verschiedene modale Eingaben.

Abbildung 9. Schematische Darstellung der verbesserten multimodalen Generierung durch Recurrent Lighting Inference (ReLI). Durch den einmaligen Aufruf von ReLI wird die Genauigkeit von Texthinweisen und Tiefenkartenvorhersagen verbessert.
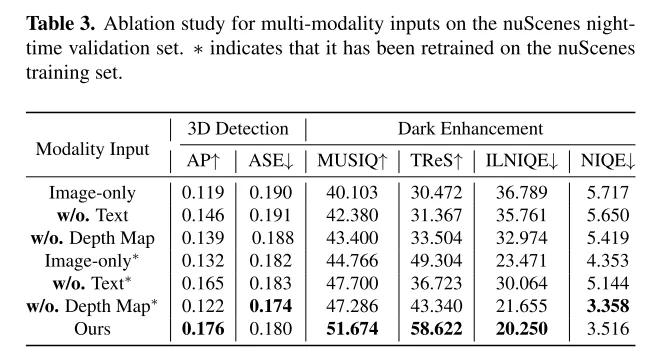
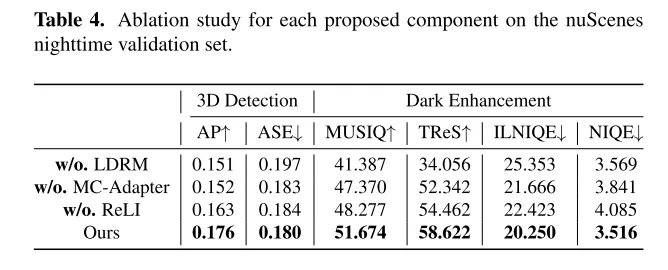
In diesem Artikel wird LightDiff vorgestellt, ein domänenspezifisches Framework, das für autonome Fahranwendungen entwickelt wurde und darauf abzielt, die Qualität von Bildern in Umgebungen mit wenig Licht zu verbessern und visionsorientierte Herausforderungen bei der Wahrnehmung zu lindern Systeme. Durch die Nutzung eines dynamischen Datenverschlechterungsprozesses, Multibedingungsadaptern für verschiedene Eingabemodalitäten und einer wahrnehmungsspezifischen, bewertungsgesteuerten Belohnungsmodellierung mithilfe von Reinforcement Learning verbessert LightDiff die Bildqualität bei Nacht und die 3D-Leistung der Fahrzeugerkennungsleistung des nuScenes-Datensatzes erheblich. Diese Innovation macht nicht nur große Mengen an Nachtdaten überflüssig, sondern stellt auch die semantische Integrität bei der Bildtransformation sicher und demonstriert damit ihr Potenzial zur Verbesserung der Sicherheit und Zuverlässigkeit in autonomen Fahrszenarien. In Ermangelung realistischer gepaarter Tag-Nacht-Bilder ist es ziemlich schwierig, schwache Fahrbilder mit Autolichtern zu synthetisieren, was die Forschung auf diesem Gebiet einschränkt. Zukünftige Forschung könnte sich auf eine bessere Sammlung oder Generierung hochwertiger Trainingsdaten konzentrieren.
@ARTICLE{2024arXiv240404804L,
Autor = {{Li}, Jinlong und {Li}, Baolu und {Tu}, Zhengzhong und {Liu}, Xinyu und {Guo}, Qing und {Juefei- Xu}, Felix und {Xu}, Runsheng und {Yu}, Hongkai},
title = "{Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving}",
journal = {arXiv E-Prints},
keywords = {Informatik – Computer Vision und Mustererkennung},
Jahr = 2024,
Monat = April,
eid = {arXiv:2404.04804},
pages = {arXiv:2404.04804},
doi = {10.48550/arxiv.2404.04804},
archiveprefix = {arxiv},
print = {2404.04804,
primaryClass = {cs.cv},
adsurl = {https://iiGr 4l },
adsnote = {Bereitgestellt vom SAO/NASA Astrophysics Data System}
}
Das obige ist der detaillierte Inhalt vonCVPR\'24 |. LightDiff: Diffusionsmodell in Szenen mit wenig Licht, das die Nacht direkt beleuchtet!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



