


Anstatt den üblichen Weg von Transformer einzuschlagen, haben wir die neue inländische Architektur RWKV von RNN modifiziert und neue Fortschritte gemacht:
zwei neue RWKV-Architekturen vorgeschlagen, nämlich Eagle (RWKV-5) und Finch ( RWKV-6).
Diese beiden Sequenzmodelle basieren auf der RWKV-4-Architektur und wurden anschließend verbessert.
Zu den Designfortschritten in der neuen Architektur gehören mehrköpfige Matrixwertzustände(mehrköpfige Matrixwertzustände) und dynamischer Wiederholungsmechanismus(dynamischer Wiederholungsmechanismus). Diese Verbesserungen verbessern die Ausdrucksfähigkeit von das RWKV-Modell, während die Inferenzeffizienzeigenschaften von RNN beibehalten werden.
Gleichzeitig führt die neue Architektur einen neuen mehrsprachigen Korpus mit 1,12 Billionen Token ein.
Das Team hat außerdem einen schnellen Tokenizer entwickelt, der auf Greedy Matching basiert, um die Mehrsprachigkeit von RWKV zu verbessern.
Derzeit sind 4 Eagle-Modelle und 2 Finch-Modelle auf Huo Hua Face erschienen~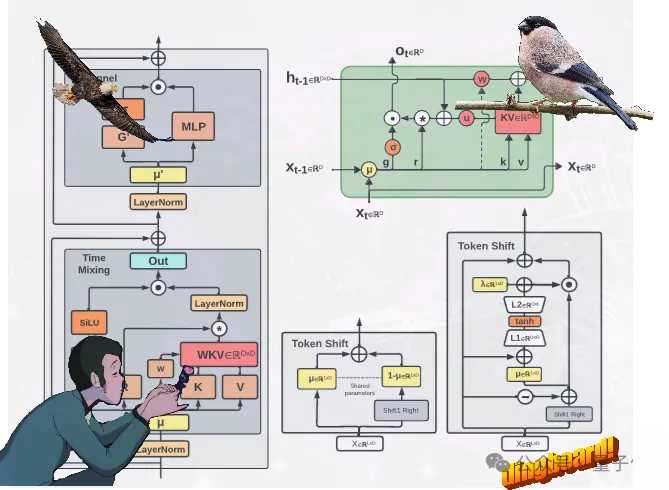
4 Eagle (RWKV-5)Modell: 0,4B, 1,5B, 3B, 7B Parametergrößen;
2 Finch(RWKV-6)Modell: Die Parametergrößen sind 1,6B bzw. 3B.
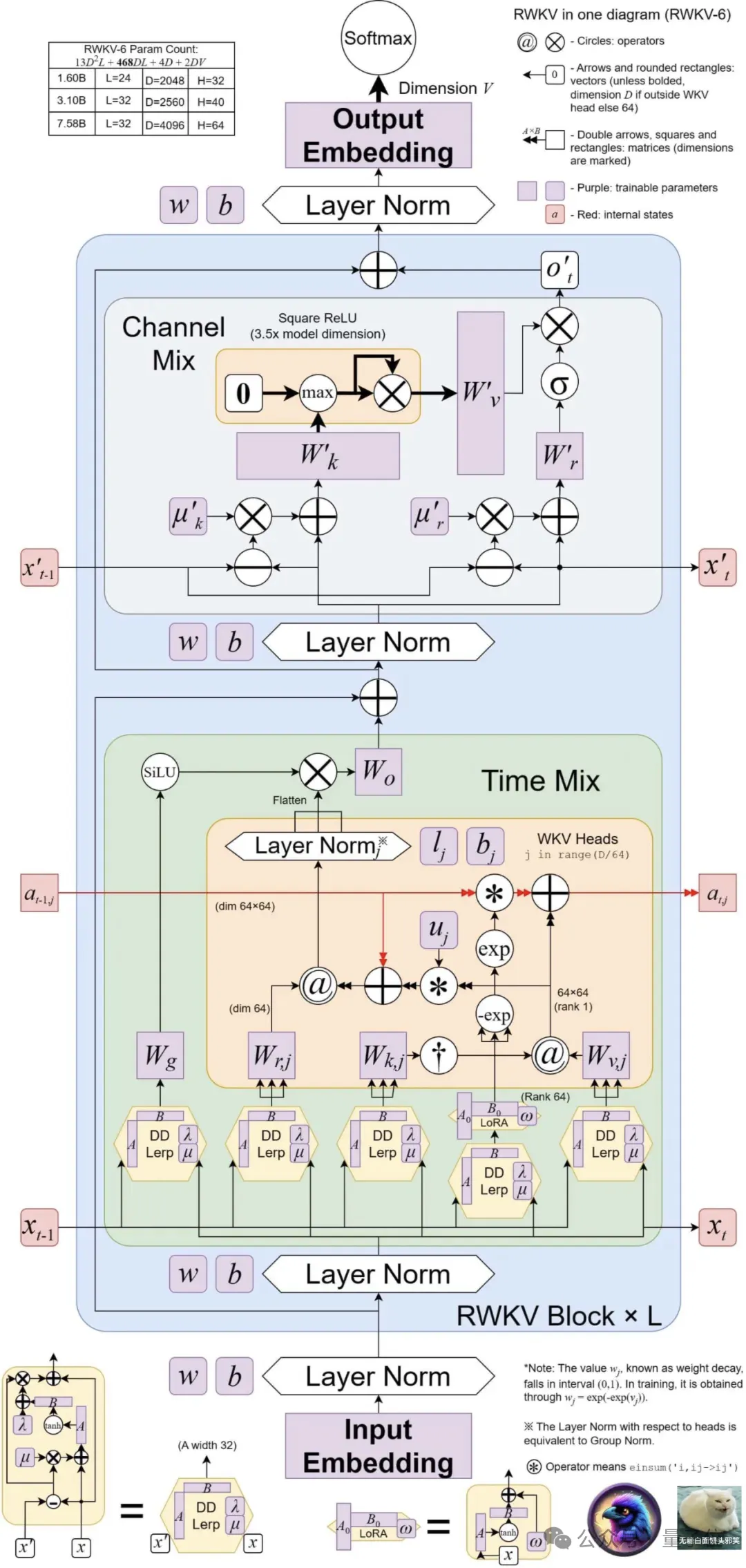
mehrköpfige Matrixwertzustände (anstelle von Vektorwertzuständen), neu strukturierte Akzeptanzzustände und einen zusätzlichen Zeitplan für Gating-Mechanismen verwendet.
Finch verbessert die Leistungsfähigkeit und Flexibilität der Architektur weiter durch die Einführung vonneuen datenbezogenen Funktionen für Zeitmischungs- und Token-Shift-Module, einschließlich parametrisierter linearer Interpolation.
Darüber hinaus schlägt Finch eine neue Verwendung von adaptiven Funktionen mit niedrigem Rang vor, um trainierbare Gewichtsmatrizen zu ermöglichen, die erlernten Datenzerfallsvektoren kontextsensitiv effektiv zu erweitern. Schließlich führt die neue RWKV-Architektureinen neuen Tokenizer RWKV World Tokenizer und einen neuen Datensatz RWKV World v2 ein, die beide zur Verbesserung des RWKV-Modells in Bezug auf Mehrsprachen- und Codedatenleistung verwendet werden .
Der neue Tokenizer RWKV World Tokenizer enthält Wörter aus ungewöhnlichen Sprachen und führt eine schnelle Tokenisierung durch Trie-basiertes Greedy-Matching(Greedy-Matching) durch.
Der neue Datensatz RWKV World v2 ist ein neuer mehrsprachiger 1.12T-Token-Datensatz, der aus verschiedenen handverlesenen öffentlich verfügbaren Datenquellen stammt. In seiner Datenzusammensetzung sind etwa 70 % englische Daten, 15 % mehrsprachige Daten und 15 % Codedaten. Was waren die Benchmark-Ergebnisse? Architektonische Innovation allein reicht nicht aus, der Schlüssel liegt in der tatsächlichen Leistung des Modells. Werfen wir einen Blick auf die Ergebnisse des neuen Modells auf den wichtigsten maßgeblichen Bewertungslisten – MQAR-TestergebnisseMQAR(Multiple Query Associative Recall)Die Aufgabe ist eine Aufgabe zur Bewertung von Sprachmodellen , entworfen, um die assoziative Speicherfähigkeit des Modells unter mehreren Abfragen zu testen.
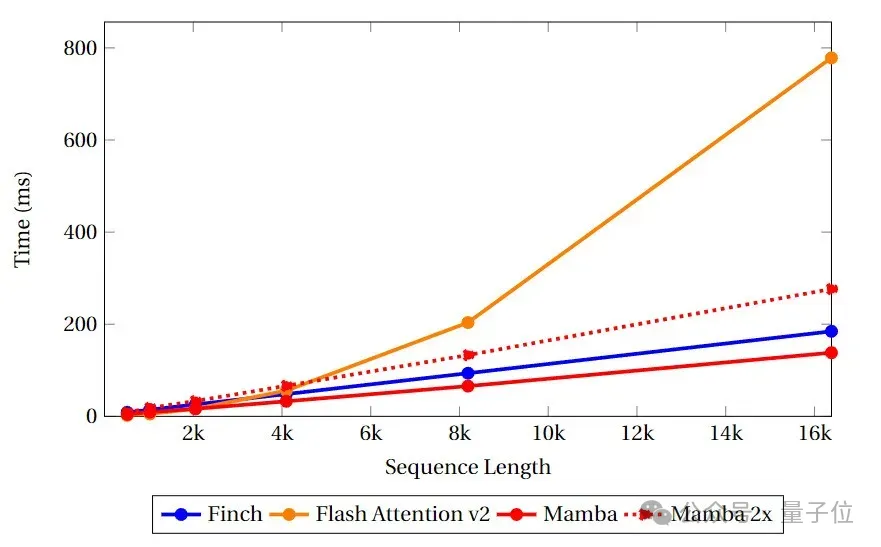
Bei dieser Art von Aufgabe muss das Modell bei mehreren Abfragen relevante Informationen abrufen. Das Ziel der MQAR-Aufgabe besteht darin, die Fähigkeit des Modells zu messen, Informationen unter mehreren Abfragen abzurufen, sowie seine Anpassungsfähigkeit und Genauigkeit an verschiedene Abfragen. Das Bild unten zeigt die MQAR-Task-Testergebnisse von RWKV-4, Eagle, Finch und anderen Nicht-Transformer-Architekturen.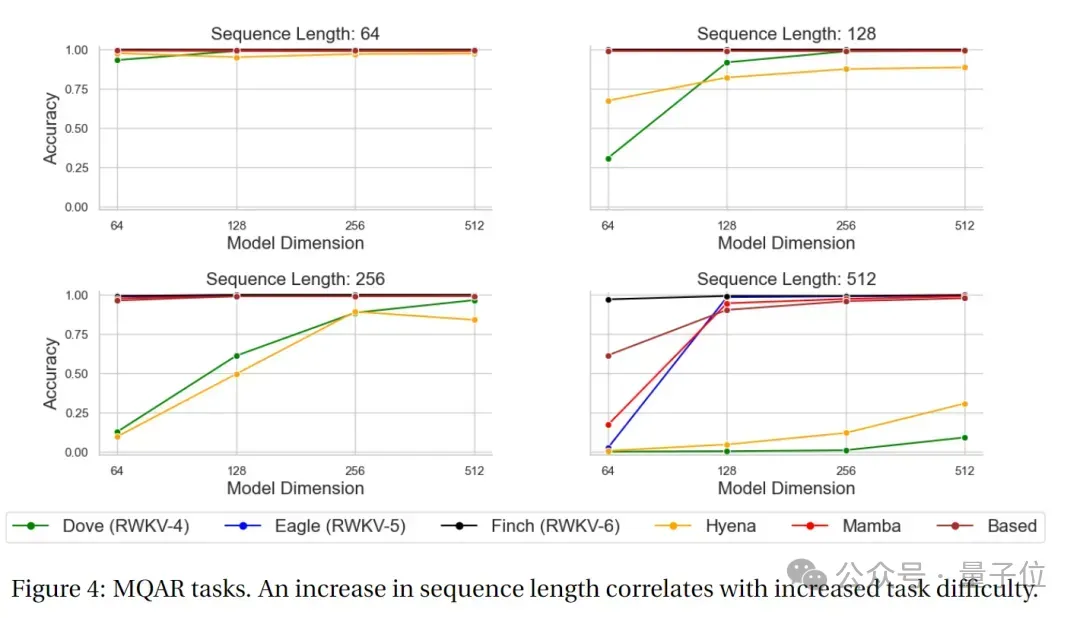
(Alle Modelle sind basierend auf der Kontextlänge 4096 vorab trainiert) .
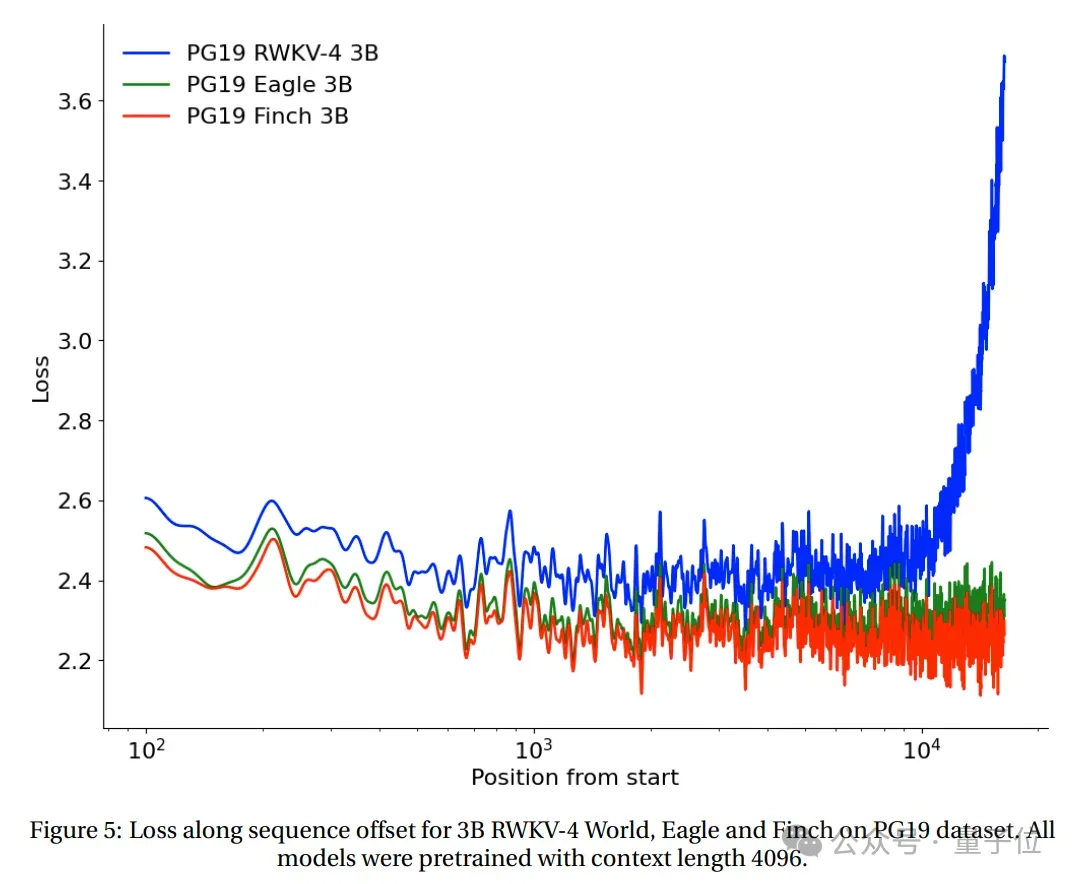
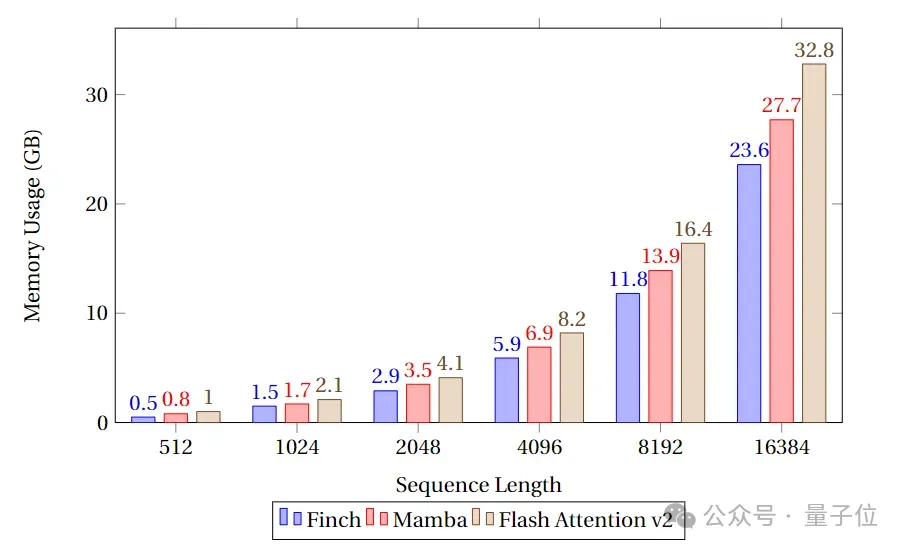
Es ist ersichtlich, dass Finch in Bezug auf die Speichernutzung immer besser ist als Mamba und Flash Attention, und die Speichernutzung ist 40 % bzw. 17 % geringer als bei Flash Attention und Mamba.




Über Forschungsinhalte, veröffentlicht von der RWKV-Stiftung Das neueste Papier "Eagle and Finch: RWKV mit Matrixwertzuständen und dynamischer Wiederholung".
Das Papier wurde gemeinsam vom RWKV-Gründer Bo PENG (Bloomberg) und Mitgliedern der RWKV-Open-Source-Community erstellt.

Co-Autor von Bloomberg, Absolvent der Hong Kong UniversityDepartment of Physics, mit mehr als 20 Jahren Programmiererfahrung. Er arbeitete einst bei Ortus Capital, einem der weltweit größten Devisen-Hedgefonds, und war verantwortlich für den hochfrequenten quantitativen Handel.
Außerdem wurde ein Buch über Deep Convolutional Networks „Deep Convolutional Networks·Principles and Practice“ veröffentlicht.
Sein Hauptschwerpunkt und Interesse liegt in der Software- und Hardwareentwicklung. In früheren öffentlichen Interviews hat er deutlich gemacht, dass AIGC sein Interesse ist, insbesondere die neuartige Generation.
Derzeit hat Bloomberg 2,1.000 Follower auf Github.
Aber seine wichtigste öffentliche Identität ist die des Mitbegründers eines Beleuchtungsunternehmens, Xinlin Technology, das hauptsächlich Sonnenlampen, Deckenlampen, tragbare Schreibtischlampen usw. herstellt.
Und er sollte ein älterer Katzenliebhaber sein. Es gibt eine orangefarbene Katze auf Github-, Zhihu- und WeChat-Avataren sowie auf der offiziellen Website-Homepage des Beleuchtungsunternehmens und auf Weibo.

Qubit erfuhr, dass die aktuelle multimodale Arbeit von RWKV RWKV Music (Musikregie) und VisualRWKV (Bildregie) umfasst.
Als nächstes wird sich RWKV auf die folgenden Richtungen konzentrieren:
Papierlink:
https://arxiv.org/pdf/2404.05892.pdf
Das obige ist der detaillierte Inhalt vonMagisch modifiziertes RNN fordert Transformer heraus, RWKV ist neu: Einführung von zwei neuen Architekturmodellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 So verwenden Sie den Befehl „find', um Dateien unter Linux zu finden
So verwenden Sie den Befehl „find', um Dateien unter Linux zu finden
 Was sind die Marquee-Parameter?
Was sind die Marquee-Parameter?
 Was ist ^quxjg$c
Was ist ^quxjg$c












