


Kann das „Diffusionsmodell“ auch algorithmische Probleme überwinden?
 Bilder
Bilder
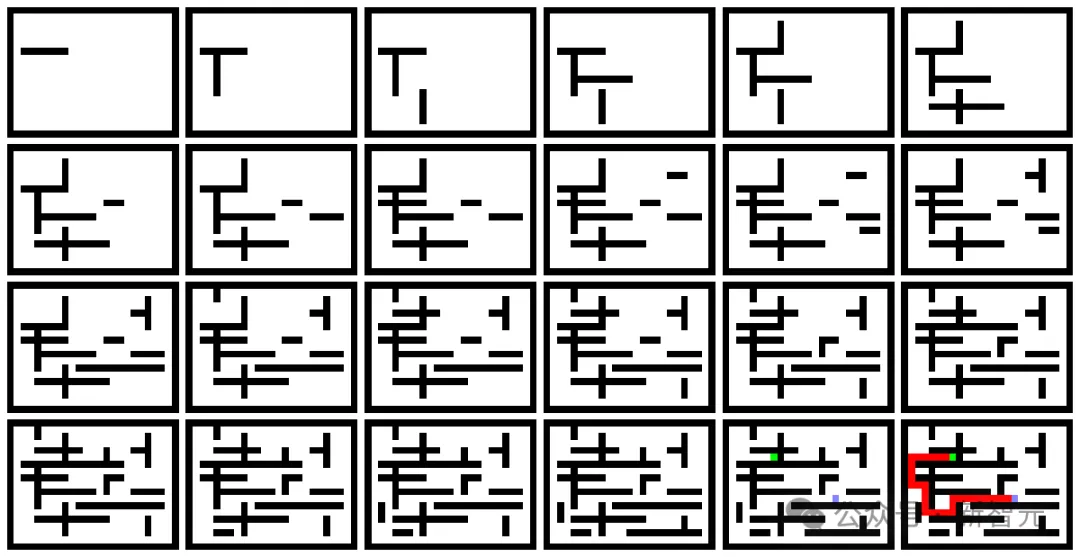
Ein Doktorand hat ein interessantes Experiment durchgeführt, bei dem er „diskrete Diffusion“ nutzte, um den kürzesten Weg in einem Labyrinth zu finden, das durch ein Bild dargestellt wird.
 Bilder
Bilder
Nach Angaben des Autors entsteht jedes Labyrinth durch wiederholtes Hinzufügen horizontaler und vertikaler Wände.
Unter diesen werden der Startpunkt und der Zielpunkt zufällig ausgewählt.
Probieren Sie zufällig einen Pfad als Lösung aus, vom kürzesten Weg vom Startpunkt zum Zielpunkt. Der kürzeste Weg wird mithilfe eines exakten Algorithmus berechnet.
 Bilder
Bilder
Dann verwenden Sie das diskrete Diffusionsmodell und U-Net.
Der Startpunkt und das Ziellabyrinth werden in einem Kanal codiert, und das Modell verwendet die Lösung in einem anderen Kanal, um das Rauschen des Labyrinths zu eliminieren.
 Bilder
Bilder
Auch wenn das Labyrinth etwas schwieriger ist, kann man es trotzdem gut schaffen.
 Bilder
Bilder
Um den Entrauschungsschritt p(x_{t-1} | x_t) abzuschätzen, schätzt der Algorithmus p(x_0 | x_t). Die Visualisierung dieser Schätzung (untere Zeile) während des Prozesses zeigt die „aktuellen Annahmen“ und konzentriert sich letztendlich auf die Ergebnisse.
 Bilder
Bilder
Der leitende Wissenschaftler von NVIDIA, Jim Fan, sagte, dass dies ein interessantes Experiment sei und das Diffusionsmodell den Algorithmus „rendern“ könne. Es kann Labyrinthdurchquerungen nur aus Pixeln implementieren, sogar mit U-Net, das viel schwächer als Transforme ist.
Ich dachte immer, dass das Diffusionsmodell der Renderer und der Transformer die Inferenz-Engine ist. Es scheint, dass der Renderer selbst auch sehr komplexe sequentielle Algorithmen kodieren kann.
 Bild
Bild
Dieses Experiment schockierte die Internetnutzer einfach: „Was kann das Diffusionsmodell sonst noch?!“ Durch das Training des Diffusionstransformators wird AGI das Problem lösen.
 Bilder
Bilder
Diese Studie wurde jedoch noch nicht offiziell veröffentlicht und der Autor sagte, dass sie später auf arxiv aktualisiert wird.
 Es ist erwähnenswert, dass sie in diesem Experiment das vom Google Brain-Team im Jahr 2021 vorgeschlagene diskrete Diffusionsmodell verwendet haben.
Es ist erwähnenswert, dass sie in diesem Experiment das vom Google Brain-Team im Jahr 2021 vorgeschlagene diskrete Diffusionsmodell verwendet haben.
Bilder
Erst kürzlich wurde diese Studie für eine Neuauflage aktualisiert.
 Diskretes Diffusionsmodell
Diskretes Diffusionsmodell
„Generatives Modell“ ist das Kernproblem beim maschinellen Lernen.
GAN, VAE, große autoregressive neuronale Netzwerkmodelle, normalisierter Fluss und andere Methoden haben ihre eigenen Vorteile in Bezug auf Probenqualität, Abtastgeschwindigkeit, Protokollwahrscheinlichkeit und Trainingsstabilität.
In letzter Zeit ist das „Diffusionsmodell“ zur beliebtesten Alternative für die Bild- und Audioerzeugung geworden.
Es kann eine mit GAN vergleichbare Stichprobenqualität und eine mit autoregressiven Modellen vergleichbare Log-Likelihood mit weniger Inferenzschritten erreicht werden.
 Bilder
Bilder
Papieradresse: //m.sbmmt.com/link/46994a3cd8d943d03b44b8fc9792d435
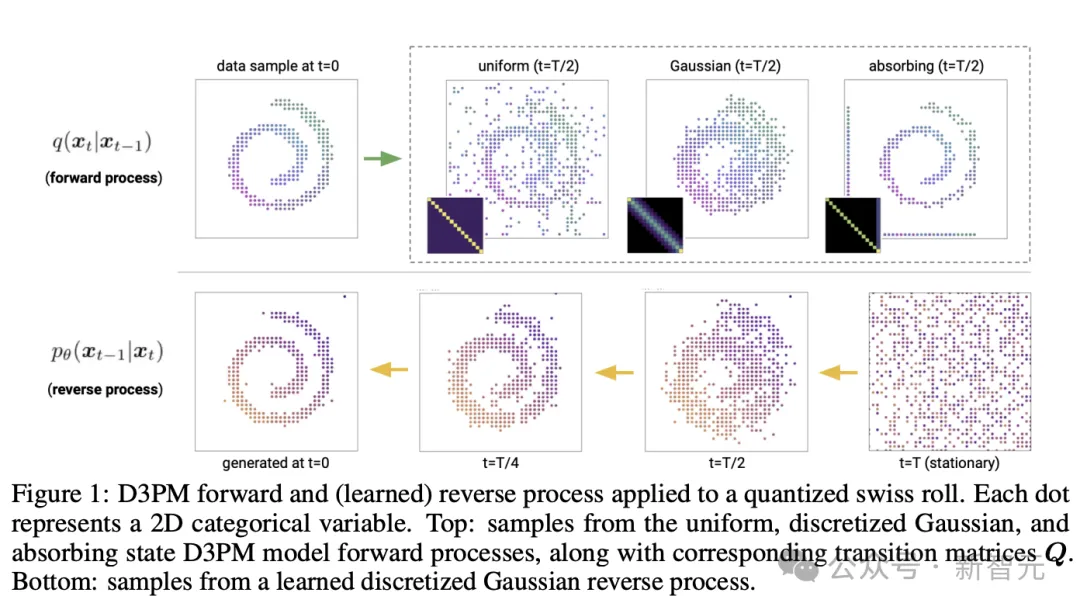
Obwohl einige Leute kürzlich Diffusionsmodelle für diskrete und kontinuierliche Zustandsräume vorgeschlagen haben Die Forschung konzentrierte sich hauptsächlich auf Gaußsche Diffusionsprozesse, die im kontinuierlichen Zustandsraum ablaufen (z. B. reelle Bilder und Wellenformdaten).
Diffusionsmodelle diskreter Zustandsräume wurden in den Bereichen Text- und Bildsegmentierung untersucht, haben sich jedoch bei umfangreichen Text- und Bildgenerierungsaufgaben noch nicht als wettbewerbsfähiges Modell erwiesen.
Das Google-Forschungsteam schlug ein neues diskretes Entrauschungs-Diffusionswahrscheinlichkeitsmodell (D3PM) vor.
In der Studie zeigten die Autoren, dass die Wahl der Übermatrix eine wichtige Designentscheidung ist, die die Ergebnisse sowohl im Bild- als auch im Textbereich verbessern kann.
Darüber hinaus schlugen sie eine neue Verlustfunktion vor, die eine Variationsuntergrenze und einen zusätzlichen Kreuzentropieverlust kombiniert.
In Bezug auf Text erzielt dieses Modell gute Ergebnisse bei der Textgenerierung auf Zeichenebene und ist gleichzeitig auf den großen Vokabular-LM1B-Datensatz skalierbar.
Auf dem CIFAR-10-Bilddatensatz nähert sich das neueste Modell der Stichprobenqualität des kontinuierlichen raumbezogenen DDPM-Modells an und übertrifft die Log-Likelihood des kontinuierlichen raumbezogenen DDPM-Modells.
 Bilder
Bilder
Arnaud Pannatier

Arnaud Pannatier ab März 2020 unter Mentor François Fleur et Die Gruppe für maschinelles Lernen beginnt ein Ph.D.
Er hat kürzlich HyperMixer entwickelt und dabei ein Supernetzwerk verwendet, um MLPMixer die Verarbeitung von Eingaben unterschiedlicher Länge zu ermöglichen. Dadurch kann das Modell die Eingabe auf permutationsinvariante Weise verarbeiten und verleiht dem Modell nachweislich ein Aufmerksamkeitsverhalten, das linear mit der Länge der Eingabe skaliert.
An der EPFL erhielt er einen Bachelor-Abschluss in Physik und einen Master-Abschluss in Informatik und Ingenieurwesen (CSE-MASH).
Das obige ist der detaillierte Inhalt vonDas Diffusionsmodell überwindet algorithmische Probleme, AGI ist nicht mehr weit! Google Brain findet den kürzesten Weg in einem Labyrinth. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 Rangliste der zehn besten Software-Apps für den Devisenhandel
Rangliste der zehn besten Software-Apps für den Devisenhandel
 So erstellen Sie einen Index in Word
So erstellen Sie einen Index in Word
 Die neuesten Preise der zehn wichtigsten virtuellen Währungen
Die neuesten Preise der zehn wichtigsten virtuellen Währungen
 Was sind die ERP-Systeme für Unternehmen?
Was sind die ERP-Systeme für Unternehmen?
 So installieren Sie Pycharm
So installieren Sie Pycharm
 So öffnen Sie eine APK-Datei
So öffnen Sie eine APK-Datei
 So öffnen Sie eine Mobi-Datei
So öffnen Sie eine Mobi-Datei












