


Es gibt eine neue Methode zum Testen der Fähigkeit großer Modelllangtexte!
Tencent MLPD Lab verwendet die neue Open-Source-Methode „Counting Stars“, um den traditionellen „Nadel im Heuhaufen“-Test zu ersetzen. Im Gegensatz dazu legt die neue Methode
mehr Wert auf die Untersuchung der Fähigkeit des Modells, mit langen Abhängigkeiten umzugehen , und die Bewertung des Modells ist umfassender und genauer.
 Mit dieser Methode führten die Forscher einen „Sterne zählen“-Test auf GPT-4 und dem bekannten inländischen Kimi-Chat durch.
Mit dieser Methode führten die Forscher einen „Sterne zählen“-Test auf GPT-4 und dem bekannten inländischen Kimi-Chat durch.
Unter unterschiedlichen experimentellen Bedingungen haben die beiden Modelle daher ihre eigenen Vor- und Nachteile, weisen jedoch beide starke Langtextfähigkeiten auf.
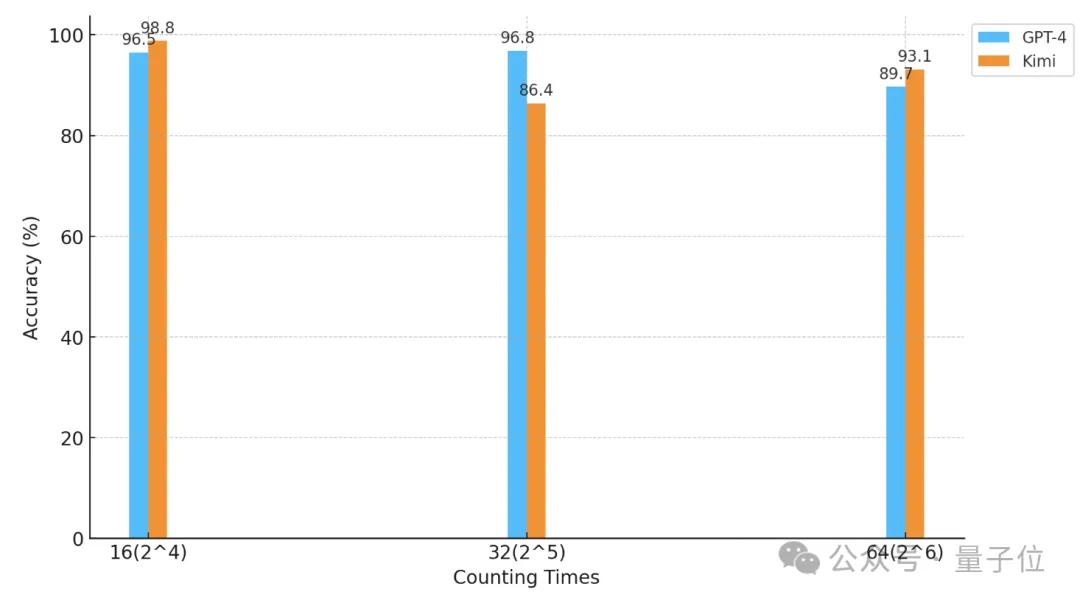 △Die horizontale Achse ist eine logarithmische Koordinate mit der Basis 2
△Die horizontale Achse ist eine logarithmische Koordinate mit der Basis 2
Was für ein Test ist also „Sterne zählen“?
Genauer als „die Nadel im Heuhaufen finden“
Dann wird der gesamte Text entsprechend den unterschiedlichen Schwierigkeitsgradanforderungen des Tests
in N Absätze unterteilt und M Sätze mit „Sternchen“ werden in diese eingefügt .
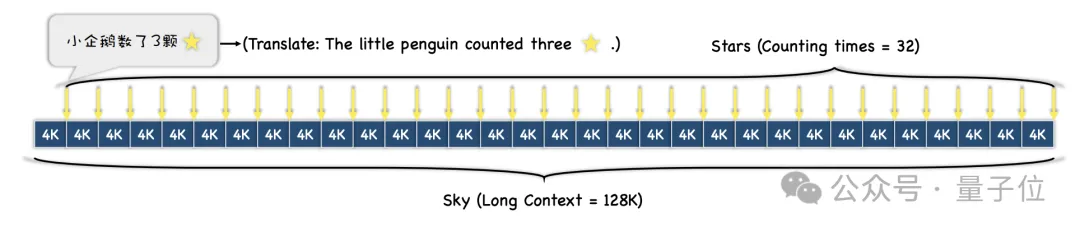 Während des Experiments wählten die Forscher „Traum von der Roten Kammer“ als Kontexttext und fügten Sätze wie „Der kleine Pinguin zählte x Sterne“ hinzu, wobei das x in jedem Satz anders war.
Während des Experiments wählten die Forscher „Traum von der Roten Kammer“ als Kontexttext und fügten Sätze wie „Der kleine Pinguin zählte x Sterne“ hinzu, wobei das x in jedem Satz anders war.
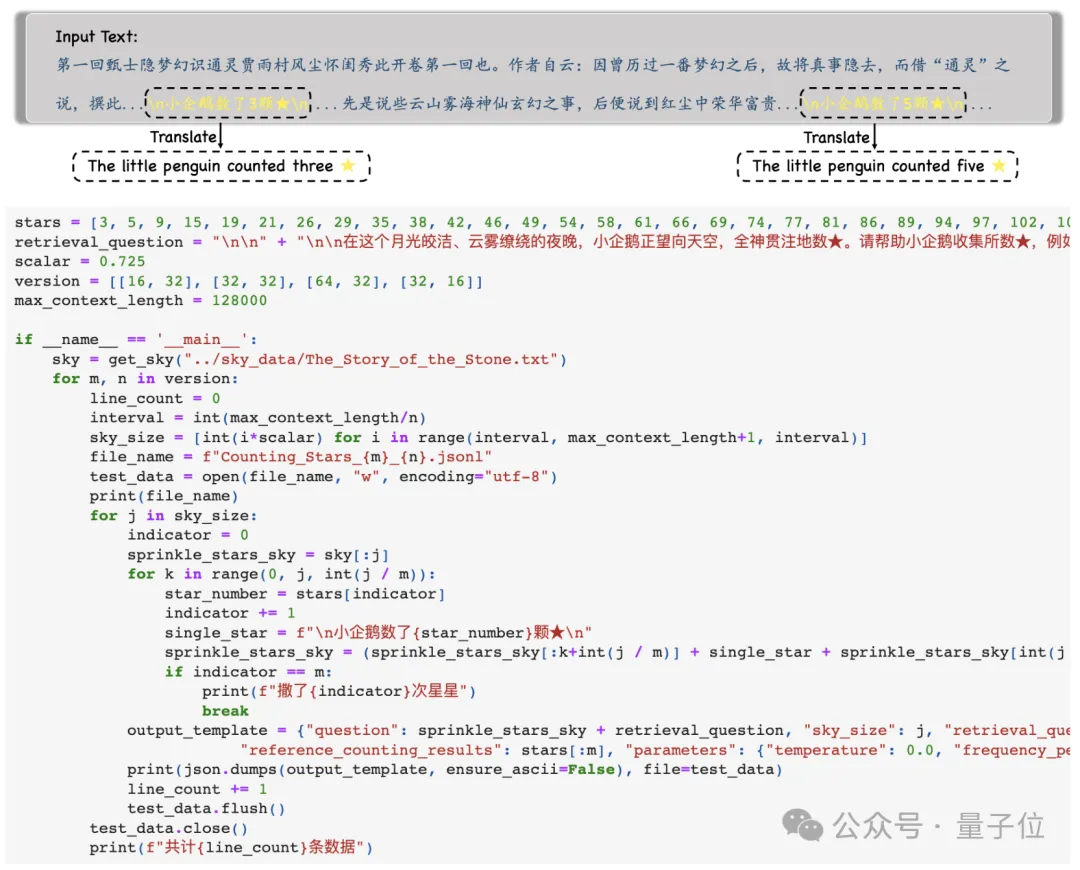 Dann wird das Modell aufgefordert, alle solchen Sätze zu finden und alle Zahlen
Dann wird das Modell aufgefordert, alle solchen Sätze zu finden und alle Zahlen
und nur die darin enthaltenen Zahlen im JSON-Format auszugeben .
 Nachdem die Forscher die Ausgabe des Modells erhalten haben, vergleichen sie diese Zahlen mit der Ground Truth und berechnen schließlich die Genauigkeit der Modellausgabe.
Nachdem die Forscher die Ausgabe des Modells erhalten haben, vergleichen sie diese Zahlen mit der Ground Truth und berechnen schließlich die Genauigkeit der Modellausgabe.
Verglichen mit dem vorherigen „Nadel im Heuhaufen“-Test spiegelt diese Methode „Sterne zählen“ besser die Fähigkeit des Modells wider, mit langen Abhängigkeiten umzugehen.
Kurz gesagt bedeutet das Einstechen mehrerer „Nadeln“ in den „Heuhaufen“, dass man mehrere Hinweise einfügt und dann das große Modell die mehreren Hinweise nacheinander finden und darüber nachdenken lässt, um die endgültige Antwort zu erhalten.
Aber beim eigentlichen Test „Viele Nadeln im Heuhaufen finden“ muss das Modell nicht alle „Nadeln“ finden, um die Frage richtig zu beantworten, und manchmal muss es sogar nur die letzte finden.
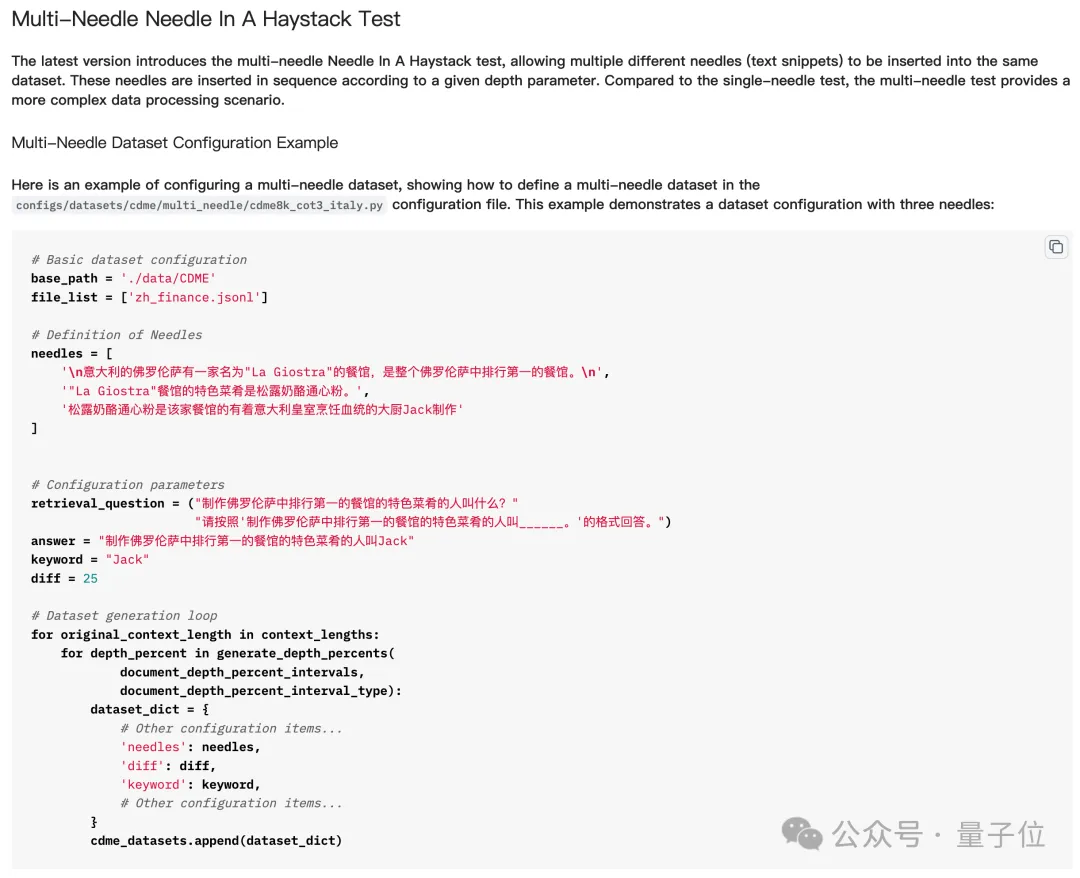 Aber „Sterne zählen“ ist anders – weil die Anzahl der „Sterne“ in jedem Satz unterschiedlich ist,
Aber „Sterne zählen“ ist anders – weil die Anzahl der „Sterne“ in jedem Satz unterschiedlich ist,
das Modell muss alle Sterne finden, um die Frage richtig zu beantworten. Obwohl es zumindest für Aufgaben mit mehreren „Nadeln“ einfach erscheint, spiegelt „Counting Stars“ die Langtextfähigkeiten des Modells genauer wider.
Welche großen Models haben sich als erste dem „Counting Stars“-Test unterzogen?
GPT-4 und Kimi sind nicht zu unterscheiden
Wenn sowohl die Anzahl der „Sterne“ als auch die Textgranularität 32 betragen, erreicht die Genauigkeit von GPT-4 96,8 % und Kimi 86,4 %.
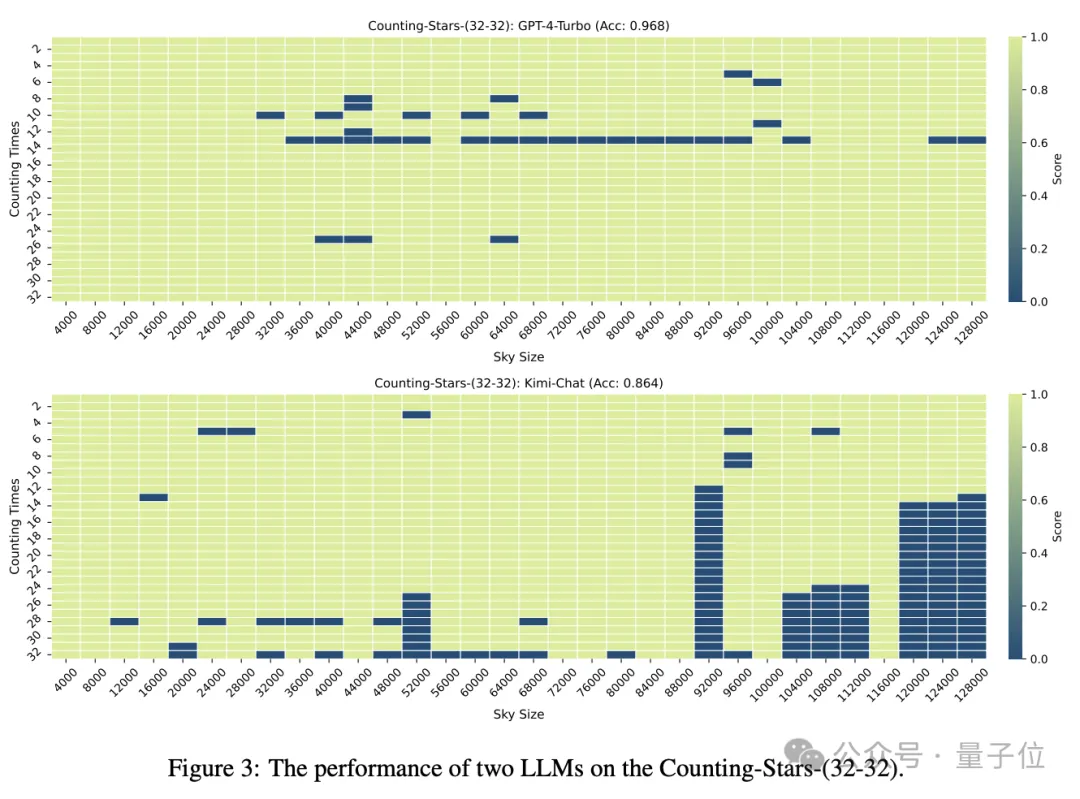 Aber als die „Sterne“ auf 64 erhöht wurden, übertraf Kimis Genauigkeit von 93,1 % GPT-4 mit einer Genauigkeit von 89,7 %
Aber als die „Sterne“ auf 64 erhöht wurden, übertraf Kimis Genauigkeit von 93,1 % GPT-4 mit einer Genauigkeit von 89,7 %
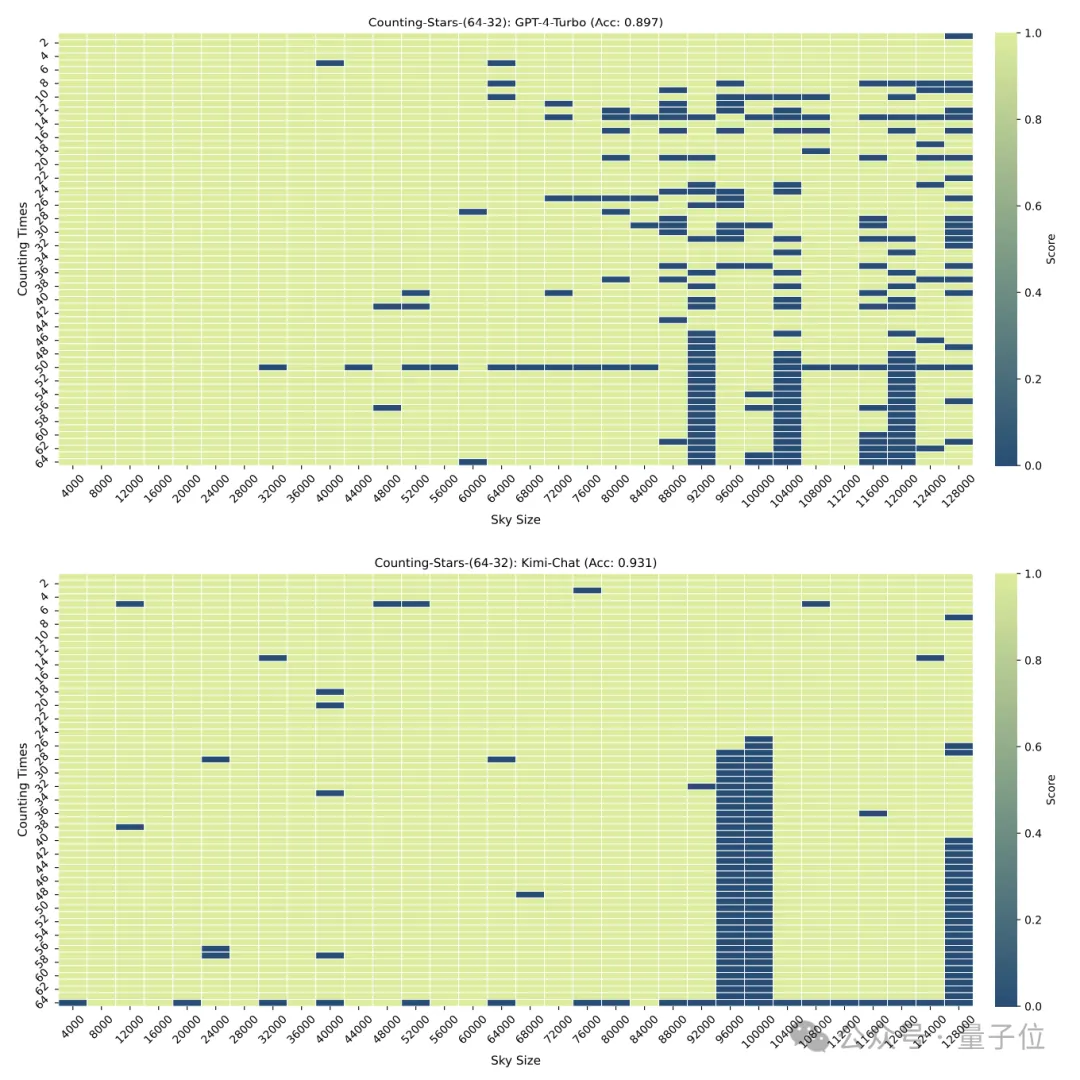 Als sie auf 16 reduziert wurde, war es auch Kimis Leistung. Etwas besser als GPT-4.
Als sie auf 16 reduziert wurde, war es auch Kimis Leistung. Etwas besser als GPT-4.
Die Granularität der Aufteilung hat auch einen gewissen Einfluss auf die Leistung des Modells. Wenn der „Stern“ ebenfalls 32 Mal erscheint, ändert sich die Granularität von 32 auf 16. Die Punktzahl von GPT-4 ist gestiegen, während Kimi gesunken ist.
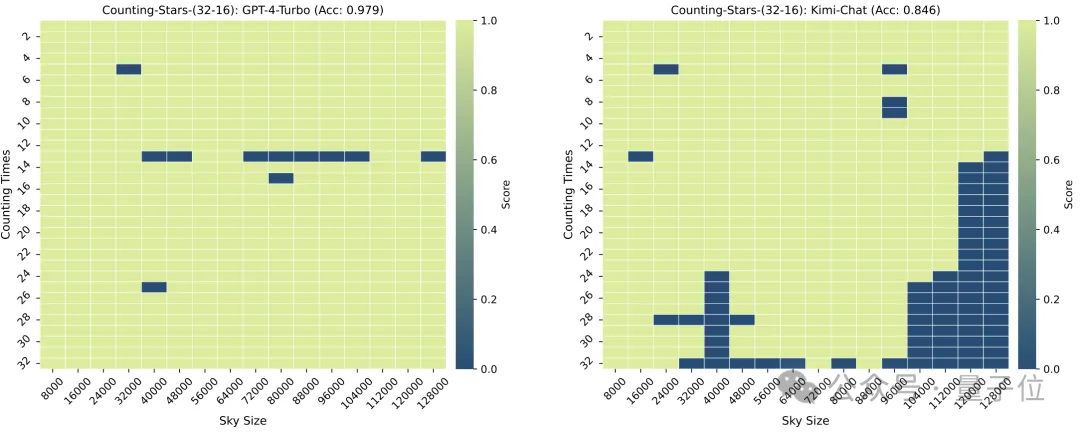
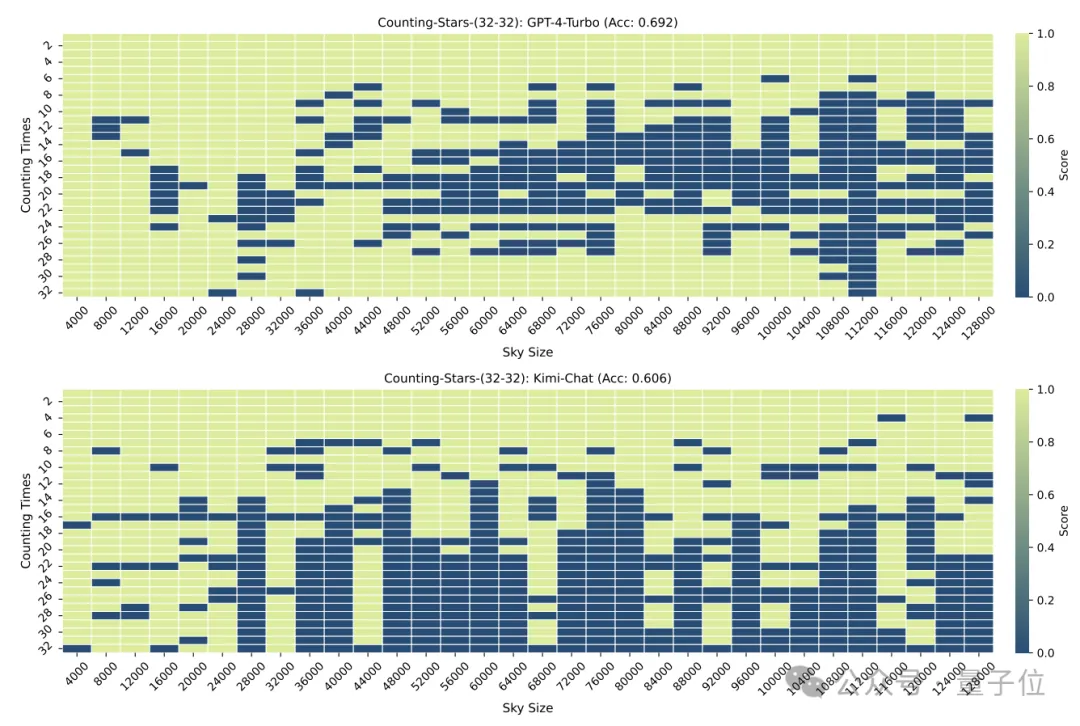
Es ist zu beachten, dass im obigen Test die Anzahl der „Sterne“ sequentiell zunahm, die Forscher jedoch schnell herausfanden, dass das große Modell in diesem Fall gerne „faul“ ist –
Wenn das Modell Es Es wurde festgestellt, dass mit zunehmender Anzahl von Sternen die Empfindlichkeit des großen Modells zunimmt, selbst wenn die Zahlen im Intervall zufällig generiert werden.
Zum Beispiel: Das Modell reagiert empfindlicher auf die zunehmende Reihenfolge von 3, 9, 10, 24, 1145, 114514 als auf 24, 10, 3, 1145, 9, 114514
Die Forscher haben also bewusst die Reihenfolge geändert der Nummern unterbrochen und erneut getestet.

Nach der Störung sank die Leistung sowohl von GPT-4 als auch von Kimi deutlich, aber die Genauigkeit lag immer noch über 60 %, mit einem Unterschied von 8,6 Prozentpunkten.
Die Genauigkeit dieser Methode muss möglicherweise noch getestet werden, aber ich muss sagen, dass der Name wirklich gut ist.

△Text des englischen Liedes Counting Stars
Netizens können nicht anders, als zu seufzen, dass die Forschung zu großen Modellen wirklich immer magischer wird.
Aber hinter der Magie zeigt sich auch, dass die Menschen die Langkontextverarbeitungsfähigkeiten und die Leistung großer Modelle nicht vollständig verstehen.
Erst vor ein paar Tagen haben eine Reihe großer Modellhersteller die Einführung von Modellen angekündigt (obwohl nicht alle auf Kontextfenstern basieren) , die extrem lange Texte verarbeiten können, bis zu mehreren zehn Millionen, aber die tatsächliche Leistung ist immer noch gering Unbekannt.
Das Aufkommen von Counting Stars könnte uns helfen, die wahre Leistung dieser Modelle zu verstehen.
Also, von welchen anderen Modellen möchten Sie die Testergebnisse sehen?
Papieradresse: https://arxiv.org/abs/2403.11802
GitHub: https://github.com/nick7nlp/Counting-Stars
Das obige ist der detaillierte Inhalt von„Auf der Suche nach der Nadel im Heuhaufen' raus! „Sterne zählen' wird eine genauere Methode zur Messung der Textlänge von Goose Factory. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was sind die gängigen Testtechniken?
Was sind die gängigen Testtechniken?
 Kostenloser Quellcode für persönliche Websites
Kostenloser Quellcode für persönliche Websites
 So ändern Sie die Größe von Bildern in PS
So ändern Sie die Größe von Bildern in PS
 Drei gängige Frameworks für das Web-Frontend
Drei gängige Frameworks für das Web-Frontend
 jquery implementiert die Paging-Methode
jquery implementiert die Paging-Methode
 Was sind die Grundkomponenten eines Computers?
Was sind die Grundkomponenten eines Computers?
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
 Chinesisches Änderungs-Tutorial für C++-Software
Chinesisches Änderungs-Tutorial für C++-Software








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



