



Nachrichten vom 28. März: Laut dem neuesten Benchmark-Bericht von LMSYS Org übertraf Claude-3 GPT-4 knapp und wurde zum „besten“ großen Sprachmodell auf der Plattform.
Auf dieser Website wird zunächst LMSYS Org vorgestellt, eine Forschungsorganisation, die gemeinsam von der University of California, Berkeley, der University of California, San Diego und der Carnegie Mellon University gegründet wurde.
Das System startet Chatbot Arena, eine Benchmark-Plattform für große Sprachmodelle (LLM), die Crowdsourcing nutzt, um große Modellprodukte anonym und zufällig zu testen. Ihre Bewertungen basieren auf dem Elo-Bewertungssystem, das in Wettbewerbsspielen wie Schach weit verbreitet ist.
Anhand der durch Benutzerabstimmung generierten Bewertungsergebnisse wählt das System jedes Mal zufällig zwei verschiedene große Modellroboter aus, um mit Benutzern zu chatten, und ermöglicht Benutzern, anonym auszuwählen, welches große Modellprodukt insgesamt eine bessere Leistung erbringt.
Chatbot Arena Seit seiner Einführung im letzten Jahr liegt GPT-4 fest an der Spitze und hat sich sogar zum Goldstandard für die Bewertung großer Modelle entwickelt.
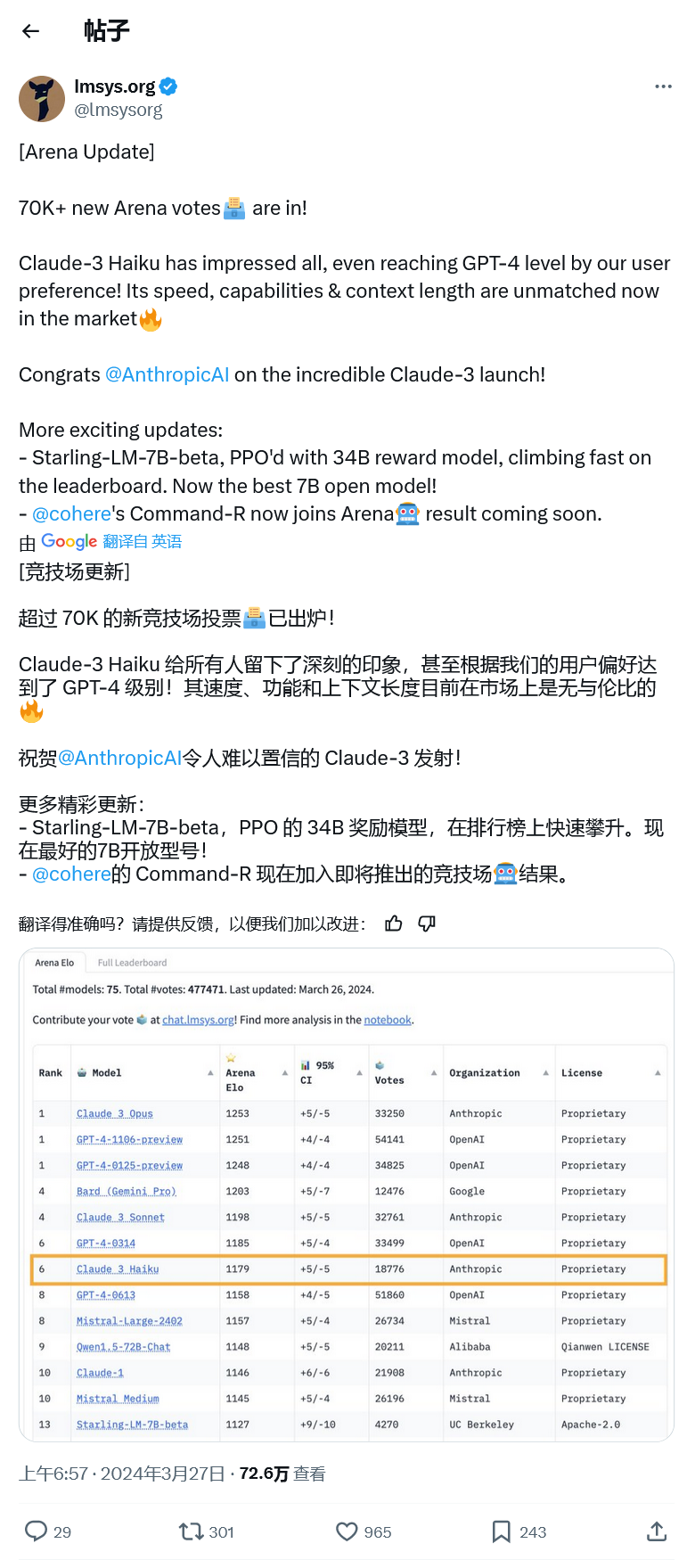
Aber gestern besiegte Claude 3 Opus von Anthropic GPT-4 mit einem knappen Vorsprung von 1253 zu 1251 und LLM von OpenAI wurde von der Spitzenposition verdrängt. Da die Punktzahl zu knapp ausfiel, ließ die Agentur aus Gründen der Fehlerrate Claude 3 und GPT-4 den ersten Platz teilen, und eine weitere Vorschauversion von GPT-4 belegte ebenfalls den ersten Platz.
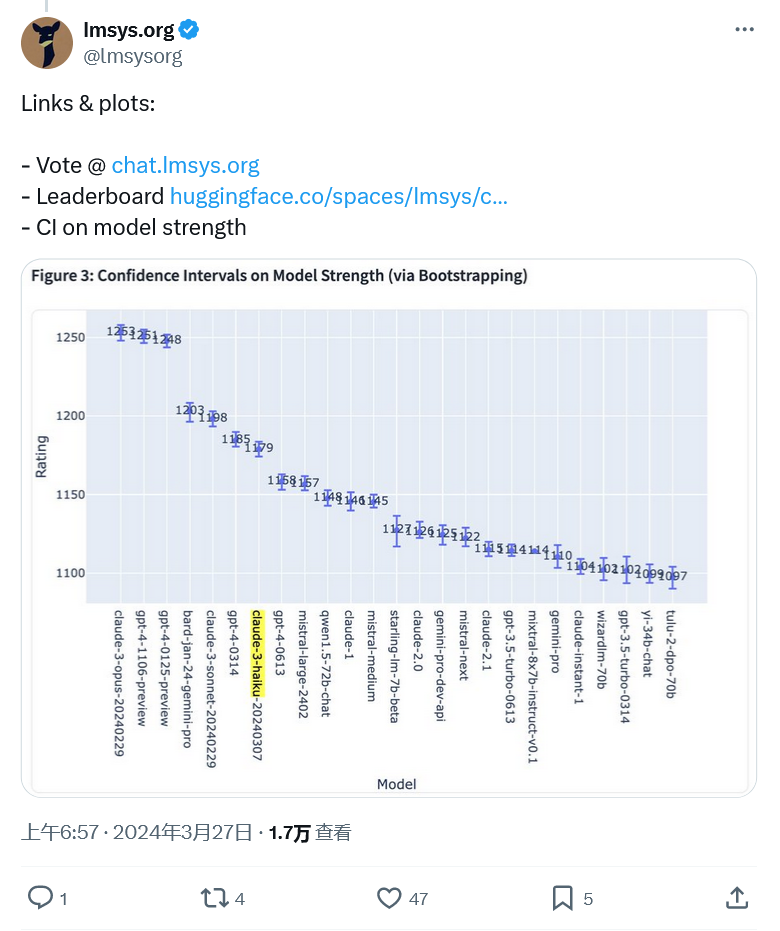
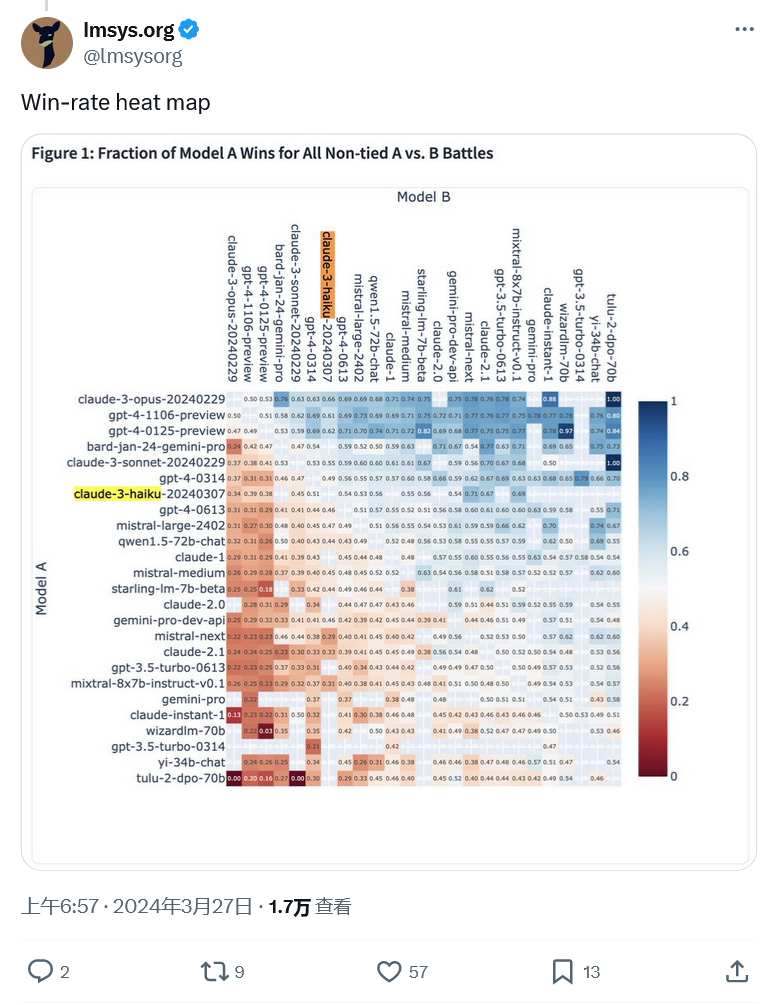
Das obige ist der detaillierte Inhalt vonDer LMSYS-Benchmark, der mit GPT-4 den ersten Platz belegt, zeigt, dass das Claude-3-Modell eine gute Leistung erbringt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Was bedeutet der Aufforderungston „Douyin sw'?
Was bedeutet der Aufforderungston „Douyin sw'?
 Was bedeutet Kol?
Was bedeutet Kol?
 So lösen Sie die Ausnahme beim Lesen großer Java-Dateien
So lösen Sie die Ausnahme beim Lesen großer Java-Dateien
 So verwenden Sie dc.rectangle
So verwenden Sie dc.rectangle
 Array-Initialisierungsmethode
Array-Initialisierungsmethode
 So verwenden Sie die Python-Bibliothek
So verwenden Sie die Python-Bibliothek








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



