


Das Training großer Sprachmodelle (LLM) ist eine rechenintensive Aufgabe, selbst solche mit „nur“ 7 Milliarden Parametern. Dieses Ausbildungsniveau erfordert Ressourcen, die über die Fähigkeiten der meisten einzelnen Enthusiasten hinausgehen. Um diese Lücke zu schließen, wurden parametereffiziente Methoden wie Low-Rank-Adaption (LoRA) entwickelt, die die Feinabstimmung einer großen Anzahl von Modellen auf GPUs der Verbraucherklasse ermöglichen.
GaLore ist eine innovative Methode, die durch optimiertes Parametertraining den VRAM-Bedarf reduziert, anstatt einfach nur die Anzahl der Parameter zu reduzieren. Dies bedeutet, dass es sich bei GaLore um eine neue Modelltrainingsstrategie handelt, die es dem Modell ermöglicht, alle Lernparameter vollständig zu nutzen und Speicher effizienter zu speichern als LoRA.
GaLore reduziert effektiv den Rechenaufwand, indem es diese Gradienten in einem niedrigdimensionalen Raum abbildet und gleichzeitig wichtige Trainingsinformationen beibehält. Im Gegensatz zu herkömmlichen Optimierern, die während der Backpropagation alle Ebenen gleichzeitig aktualisieren, verwendet GaLore für die Backpropagation eine Schicht-für-Schicht-Aktualisierungsmethode. Diese Strategie reduziert den Speicherbedarf während des Trainings erheblich und optimiert die Leistung weiter.
Genau wie LoRA ermöglicht uns GaLore die Feinabstimmung des 7B-Modells auf einer Consumer-GPU mit bis zu 24 GB VRAM. Die Ergebnisse zeigen, dass die Leistung des Modells mit der Feinabstimmung aller Parameter vergleichbar ist und sogar besser zu sein scheint als die von LoRA.
ist besser als Hugging Face. Es gibt derzeit keinen offiziellen Code für das Training und vergleicht ihn mit LoRA. Zunächst müssen wir ihn installieren GaLore Modellgewichtshaken. Da wir Hugging Face Trainer verwenden, müssen wir auch selbst eine abstrakte Klasse von Optimierern und Planern implementieren. Die Strukturen dieser Klassen führen keine Operationen aus.
pip install galore-torch
GaLore-Optimierer laden
Der GaLore-Optimierer zielt auf bestimmte Parameter ab, hauptsächlich auf solche, die mit attn oder mlp in linearen Ebenen benannt sind. Durch die systematische Verknüpfung von Funktionen mit diesen Zielparametern macht sich der GaLore 8-Bit-Optimierer an die Arbeit.
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrsDer GaLore-Optimierer verfügt über einige Hyperparameter, die wie folgt eingestellt werden müssen:
target_modules_list: Geben Sie die Ebene an, auf die GaLore abzielt.
rank: Der Rang der Projektionsmatrix. Ähnlich wie bei LoRA gilt: Je höher der Rang, desto näher kommt die Feinabstimmung der Feinabstimmung aller Parameter. Der Autor von GaLore empfiehlt 7B zur Verwendung von 1024
update_proj_gap: Die Anzahl der Schritte zum Aktualisieren der Projektion. Dies ist ein teurer Schritt und dauert für 7B etwa 15 Minuten. Definiert das Intervall für die Aktualisierung der Projektion, der empfohlene Bereich liegt zwischen 50 und 1000 Schritten.
scale: Ein Skalierungsfaktor ähnlich dem Alpha von LoRA, der zum Anpassen der Aktualisierungsintensität verwendet wird. Nachdem ich mehrere Werte ausprobiert hatte, stellte ich fest, dass „scale=2“ der klassischen Feinabstimmung mit vollständigen Parametern am nächsten kommt.
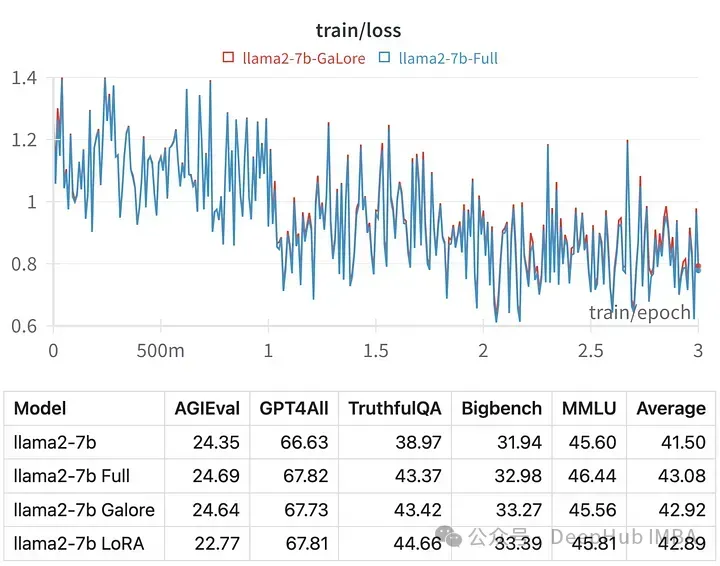
Der Trainingsverlust für einen bestimmten Hyperparameter ist dem Verlauf der vollständigen Parameteroptimierung sehr ähnlich, was darauf hinweist, dass die GaLore-Schichtenmethode tatsächlich gleichwertig ist.
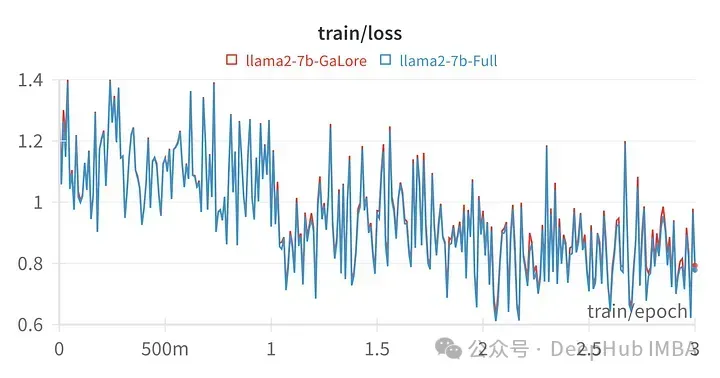
Die Ergebnisse der mit GaLore trainierten Modelle sind der vollständigen Parameter-Feinabstimmung sehr ähnlich.
GaLore kann etwa 15 GB VRAM einsparen, das Training dauert jedoch aufgrund regelmäßiger Projektionsaktualisierungen länger.
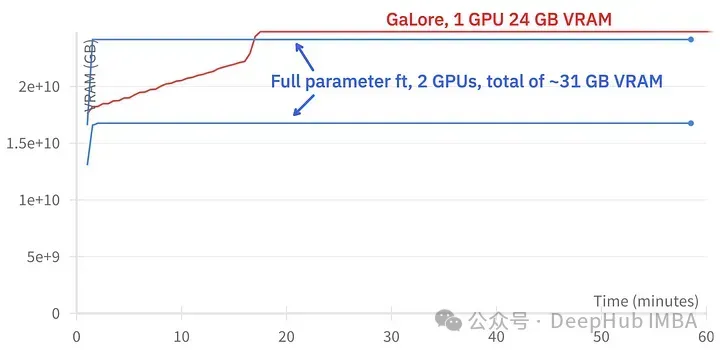
Das Bild oben zeigt den Vergleich der Speichernutzung zweier 3090
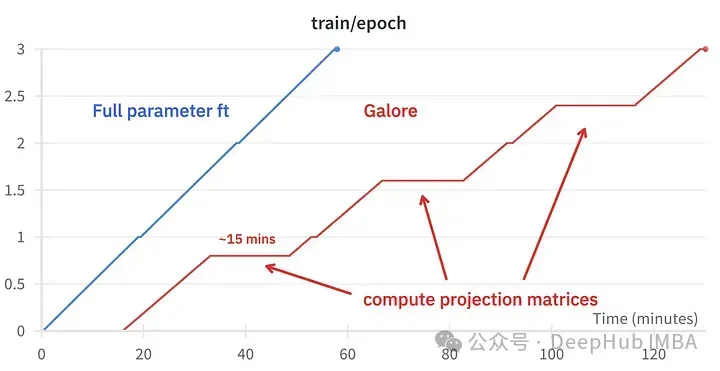
Vergleich der Trainingsereignisse, Feinabstimmung: ~58 Minuten. GaLore: Ungefähr 130 Minuten
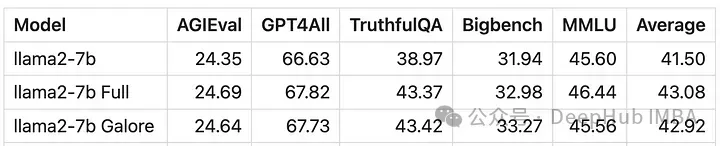
Schließlich werfen wir einen Blick auf den Vergleich zwischen GaLore und LoRA
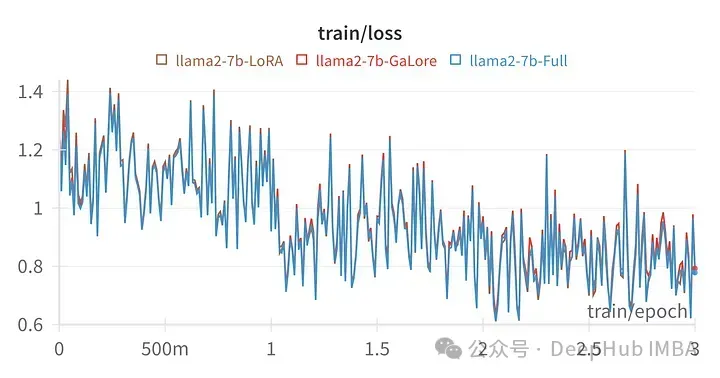
Das Bild oben ist das Verlustdiagramm von LoRA bei der Feinabstimmung aller linearen Ebenen, Rang 64, Alpha 16
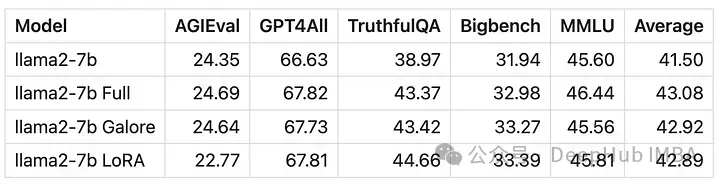
Aus numerischer Sicht ist ersichtlich, dass GaLore eine neue Methode ist, die sich dem Training mit vollständigen Parametern annähert, und deren Leistung einer Feinabstimmung entspricht und viel besser als LoRA ist.
GaLore spart VRAM und ermöglicht das Training von 7B-Modellen auf Consumer-GPUs, ist aber langsamer und dauert fast doppelt so lange wie Feinabstimmung und LoRA.
Das obige ist der detaillierte Inhalt vonEffizientes LLM-Tuning auf der lokalen GPU mit GaLore. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So zeigen Sie Prozesse unter Linux an
So zeigen Sie Prozesse unter Linux an
 Handelsplattform für digitale Währungen
Handelsplattform für digitale Währungen
 So beginnen Sie mit dem Kauf von Kryptowährungen
So beginnen Sie mit dem Kauf von Kryptowährungen
 Kann pagefile.sys gelöscht werden?
Kann pagefile.sys gelöscht werden?
 Was sind die häufig verwendeten Tastenkombinationen in WPS?
Was sind die häufig verwendeten Tastenkombinationen in WPS?
 Was sind Endgeräte?
Was sind Endgeräte?
 Verhindern Sie die Verwendung von default()
Verhindern Sie die Verwendung von default()
 Eine vollständige Liste der Tastenkombinationen für Ideen
Eine vollständige Liste der Tastenkombinationen für Ideen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



