


Google hat ein neues Video-Framework veröffentlicht:
Sie benötigen lediglich ein Bild Ihres Gesichts und eine Aufzeichnung Ihrer Rede, um ein lebensechtes Video Ihrer Rede zu erhalten.
Die Länge des Videos ist variabel und beträgt im aktuell angezeigten Beispiel bis zu 10 Sekunden.
Man sieht, dass sowohl die Mundform als auch der Gesichtsausdruck sehr natürlich sind.
Wenn das Eingabebild den gesamten Oberkörper abdeckt, kann es auch mit verschiedenen Gesten verwendet werden:

Nachdem es gelesen wurde, sagten Internetnutzer:
Damit müssen wir unsere Haare und Kleidung nicht mehr organisieren für Online-Videokonferenzen in der Zukunft.
Nun, machen Sie einfach ein Porträt und zeichnen Sie das Sprachaudio auf (manueller Hundekopf)
Verwenden Sie Ihre Stimme, um das Porträt zu steuern und ein Video zu erstellen
Dieses Framework heißt VLOGGER.
Es basiert hauptsächlich auf dem Diffusionsmodell und besteht aus zwei Teilen:
Einer ist ein zufälliges Diffusionsmodell von Mensch zu 3D-Bewegung.
Das andere ist eine neue Diffusionsarchitektur zur Verbesserung von Text-zu-Bild-Modellen.
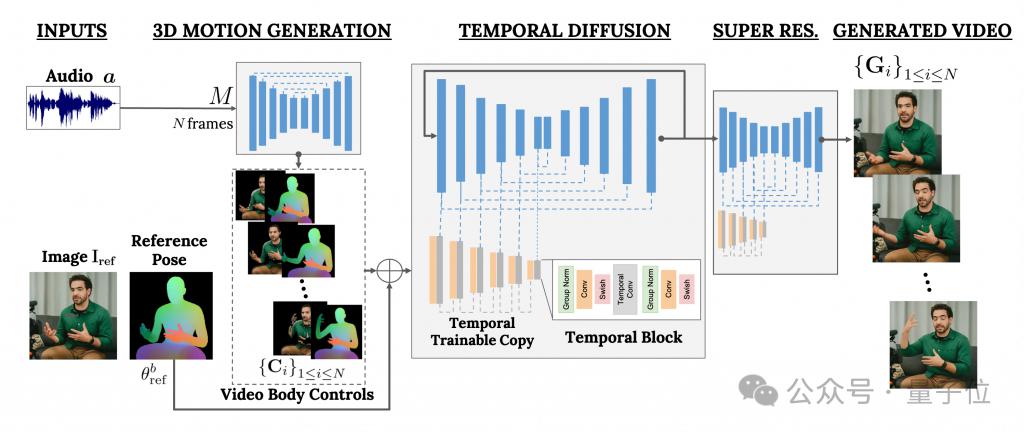
Unter ihnen ist ersterer dafür verantwortlich, die Audiowellenform als Eingabe zu verwenden, um die Körperkontrollaktionen des Charakters zu generieren, einschließlich Augen, Ausdrücke und Gesten, allgemeine Körperhaltung usw.
Letzteres ist ein Bild-zu-Bild-Modell mit zeitlicher Dimension, das verwendet wird, um das groß angelegte Bilddiffusionsmodell zu erweitern und die gerade vorhergesagten Aktionen zu verwenden, um entsprechende Frames zu generieren.
Um die Ergebnisse an ein bestimmtes Charakterbild anzupassen, verwendet VLOGGER auch die Posenkarte des Parameterbilds als Eingabe.
Das Training von VLOGGER wird an einem sehr großen Datensatz (mit dem Namen MENTOR) durchgeführt.
Wie groß ist es? Es ist 2.200 Stunden lang und enthält insgesamt 800.000 Charaktervideos.
Unter anderem beträgt die Videodauer des Testsets ebenfalls 120 Stunden mit insgesamt 4.000 Zeichen.
Google stellte fest, dass die herausragendste Leistung von VLOGGER seine Vielfalt ist:
Wie im Bild unten gezeigt, sind die Aktionen umso reichhaltiger, je dunkler (rot) die Farbe des endgültigen Pixelbilds ist.

Im Vergleich zu früheren ähnlichen Methoden in der Branche besteht der größte Vorteil von VLOGGER darin, dass nicht jeder geschult werden muss, nicht auf Gesichtserkennung und -zuschnitt angewiesen ist und das generierte Video vollständig ist (einschließlich Gesicht und Lippen). , einschließlich Körperbewegungen) usw.

Im Einzelnen, wie in der folgenden Tabelle gezeigt:
Die Gesichtsnachstellungsmethode kann eine solche Videogenerierung mit Audio und Text nicht steuern.
Audio-to-Motion kann Audio erzeugen, indem Audio in 3D-Gesichtsbewegungen kodiert wird, aber der dadurch erzeugte Effekt ist nicht realistisch genug.
Lip Sync kann Videos zu unterschiedlichen Themen verarbeiten, aber nur Mundbewegungen simulieren.
Im Vergleich schneiden die beiden letztgenannten Methoden, SadTaker und Styletalk, am ehesten mit Google VLOGGER ab, haben aber auch den Nachteil, dass sie den Körper nicht kontrollieren und das Video weiter bearbeiten können.

Apropos Videobearbeitung: Wie im Bild unten gezeigt, ist eine der Anwendungen des VLOGGER-Modells folgende: Es kann dazu führen, dass der Charakter den Mund hält, die Augen schließt, nur das linke Auge schließt oder das ganze Auge öffnet mit einem Klick:

Eine weitere Anwendung ist die Videoübersetzung:
Zum Beispiel das Ändern der englischen Sprache im Originalvideo ins Spanische mit der gleichen Mundform.
Internetnutzer haben sich beschwert
Schließlich hat Google das Modell nach der „alten Regel“ nicht veröffentlicht, und jetzt können wir nur noch mehr Effekte und Papiere sehen.
Nun, es gibt viele Beschwerden:
Die Bildqualität des Modells, die Lippensynchronisation stimmt nicht überein, es sieht immer noch sehr roboterhaft aus usw.
Daher haben einige Leute nicht gezögert, negative Bewertungen zu hinterlassen:
Ist das das Niveau von Google?

Entschuldigung für den Namen „VLOGGER“.

——Verglichen mit Sora von OpenAI ist die Aussage des Internetnutzers tatsächlich nicht unvernünftig. .
Was meint ihr?
Mehr Effekte:
https://enriccorona.github.io/vlogger/
Vollständiges Paper:
https://enriccorona.github.io/vlogger/paper.pdf
Das obige ist der detaillierte Inhalt vonGoogle veröffentlicht „Vlogger'-Modell: Ein einzelnes Bild erzeugt ein 10-Sekunden-Video. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































