


In letzter Zeit wurden große Fortschritte in Richtung verkörperter Intelligenz gemacht. Von Googles RT-H bis hin zu Figure 01, das gemeinsam von OpenAI und Figure entwickelt wurde: Roboter werden immer interaktiver und vielseitiger.
Wenn Roboter in Zukunft zu Assistenten im täglichen Leben der Menschen werden, welche Aufgaben erwarten Sie von ihnen? Bereiten Sie eine dampfende Tasse handgebrühten Kaffee zu, räumen Sie den Schreibtisch auf und helfen Sie sogar bei der Organisation eines romantischen Dates. Tsinghuas neues verkörpertes Intelligenz-Framework „CoPa“ kann diese Aufgaben mit nur einem Befehl erledigen.
CoPa (Robotic Manipulation through Spatial Constraints of Parts) ist das neueste intelligente Framework, das vom Robotik-Forschungsteam der Tsinghua-Universität unter der Leitung von Professor Gao Yang vorgeschlagen wurde. Dieses Framework erreicht zum ersten Mal die Generalisierungsfähigkeit des Roboters bei der Bewältigung von Langstreckenaufgaben und komplexen 3D-Verhaltensweisen in einer Vielzahl von Szenarien.

Papieradresse: https://arxiv.org/abs/2403.08248
Projekthomepage: https://copa-2024.github.io/
Aufgrund des Bedarfs an großen Visuelle Sprachmodelle CoPa ist eine einzigartige Anwendung von (VLMs). CoPa kann in offenen Szenarien ohne spezielle Schulung verallgemeinern und komplexe Anweisungen verarbeiten. Was an CoPa am meisten auffällt, ist seine Fähigkeit, ein tiefes Verständnis der physikalischen Eigenschaften von Objekten in der Szene zu demonstrieren, sowie seine präzisen Planungs- und Manipulationsfähigkeiten.
CoPa kann Forschern beispielsweise dabei helfen, eine Tasse handgebrühten Kaffee zuzubereiten:
Bei dieser Aufgabe kann CoPa nicht nur die Rolle jedes Objekts in einer komplexen Tischpräsentation verstehen, sondern auch deren Steuerung durch Präzision vervollständigen Kontrolle. Physische Operationen. Bei der Aufgabe „Wasser aus dem Wasserkocher in den Trichter gießen“ bewegt der Roboter beispielsweise den Wasserkocher über den Trichter und dreht ihn präzise in den entsprechenden Winkel, damit das Wasser aus der Öffnung des Wasserkochers in den Trichter fließen kann.
CoPa kann auch ein romantisches Date sorgfältig arrangieren. Nachdem CoPa die Dating-Bedürfnisse des Forschers verstanden hatte, half er ihm, einen schönen westlichen Esstisch aufzustellen.
Obwohl CoPa die Bedürfnisse der Benutzer genau versteht, demonstriert es auch die Fähigkeit, Objekte präzise zu manipulieren. Bei der Aufgabe „Eine Blume in eine Vase einsetzen“ beispielsweise greift der Roboter zunächst den Stiel der Blume, dreht ihn, bis er zur Vase zeigt, und setzt ihn schließlich ein.

Einführung in die Methode
Algorithmusablauf
Die meisten Betriebsaufgaben können in zwei Phasen unterteilt werden: das Ergreifen des Objekts und die nachfolgenden Aktionen, die zum Abschließen der Aufgabe erforderlich sind. Wenn wir beispielsweise eine Schublade öffnen, müssen wir zuerst den Griff der Schublade greifen und dann die Schublade entlang einer geraden Linie herausziehen. Auf dieser Grundlage entwarfen die Forscher zwei Stufen, nämlich zunächst durch das „Aufgabenorientierte Greifmodul (Aufgabenorientiertes Greifen)“, um die Pose des Roboters zu generieren, der das Objekt ergreift, und dann durch die „Aufgabenbezogene Bewegungsplanung“. Modul (Task-Aware) „Motion Planning)“ generiert die Pose, die erforderlich ist, um die Aufgabe nach dem Greifen abzuschließen. Der Transfer des Roboters zwischen benachbarten Posen kann durch herkömmliche Pfadplanungsalgorithmen erreicht werden.

Wichtiges Teilerkennungsmodul
Forscher beobachteten, dass die meisten Manipulationsaufgaben ein detailliertes „Verständnis auf Teileebene“ von Objekten in der Szene erfordern. Wenn wir beispielsweise mit einem Messer schneiden, halten wir den Griff statt der Klinge; wenn wir eine Brille tragen, halten wir das Gestell statt der Gläser. Basierend auf dieser Beobachtung entwarf das Forschungsteam ein „Grob-zu-Fein-Erdungsmodul“, um aufgabenbezogene Teile der Szene zu lokalisieren. Konkret lokalisiert CoPa zunächst aufgabenrelevante Objekte in der Szene durch eine grobkörnige Objekterkennung und lokalisiert dann aufgabenrelevante Teile dieser Objekte durch eine feinkörnige Teileerkennung.

Im „aufgabenorientierten Greifmodul“ lokalisiert CoPa zunächst die Greifposition (z. B. den Griff des Werkzeugs) über das Modul zur Erkennung wichtiger Teile. Diese Positionsinformationen werden zum Filtern von GraspNet (einem Werkzeug, das dies kann) verwendet Generieren Sie Szenenmodelle aller möglichen Greifhaltungen) und ermitteln Sie dann die endgültige Greifhaltung.
Aufgabenbezogenes Bewegungsplanungsmodul
Damit das große Modell der visuellen Sprache dem Roboter bei der Ausführung von Bedienaufgaben helfen kann, muss in dieser Forschung eine Schnittstelle entworfen werden, die es dem großen Modell nicht nur ermöglicht, in einer Sprache zu argumentieren, sondern auch die Roboterbedienung erleichtert. Das Forschungsteam stellte fest, dass aufgabenbezogene Objekte bei der Ausführung von Aufgaben in der Regel vielen räumlichen geometrischen Einschränkungen unterliegen. Wenn Sie beispielsweise ein Mobiltelefon aufladen, muss der Ladekopf zum Ladeanschluss zeigen; beim Verschließen einer Flasche muss der Verschluss direkt auf der Flaschenöffnung aufgesetzt werden. Auf dieser Grundlage schlug das Forschungsteam vor, räumliche Einschränkungen als Brücke zwischen der visuellen Sprache großer Modelle und Robotern zu nutzen. Konkret verwendet CoPa zunächst ein großes visuelles Sprachmodell, um die räumlichen Einschränkungen zu generieren, die aufgabenbezogene Objekte bei der Erledigung der Aufgabe erfüllen müssen, und verwendet dann ein Lösungsmodul, um die Pose des Roboters basierend auf diesen Einschränkungen zu lösen.

Experimentelle Ergebnisse
CoPa-Fähigkeitsbewertung
CoPa hat starke Generalisierungsfähigkeiten bei realen Betriebsaufgaben gezeigt. CoPa verfügt über ein tiefes Verständnis der physikalischen Eigenschaften von Objekten in der Szene, dank der Nutzung von gesundem Menschenverstand, eingebettet in große Modelle der visuellen Sprache.
Bei der Aufgabe „Einen Nagel hämmern“ zum Beispiel ergriff CoPa zuerst den Griff des Hammers, drehte dann den Hammer, bis der Hammerkopf dem Nagel zugewandt war, und hämmerte schließlich nach unten. Die Aufgabe erforderte eine genaue Identifizierung des Hammerstiels, der Hammerfläche und der Nagelfläche sowie ein umfassendes Verständnis ihrer räumlichen Beziehungen, was CoPas umfassendes Verständnis der physikalischen Eigenschaften von Objekten in der Szene unter Beweis stellte.

Bei der Aufgabe „den Radiergummi in die Schublade legen“ lokalisierte CoPa zunächst die Position des Radiergummis und stellte dann fest, dass ein Teil des Radiergummis in Papier eingewickelt war Der Radiergummi würde keine Flecken hinterlassen.

Bei der Aufgabe „Löffel in die Tasse stecken“ ergriff CoPa zunächst den Griff des Löffels, übersetzte und drehte ihn so, dass er vertikal nach unten zeigte, sodass er der Tasse zugewandt war, und führte ihn schließlich in die Tasse ein, um zu beweisen, dass CoPa es kann leicht Gutes Verständnis der räumlichen geometrischen Einschränkungen, die Objekte erfüllen müssen, um Aufgaben zu erfüllen.

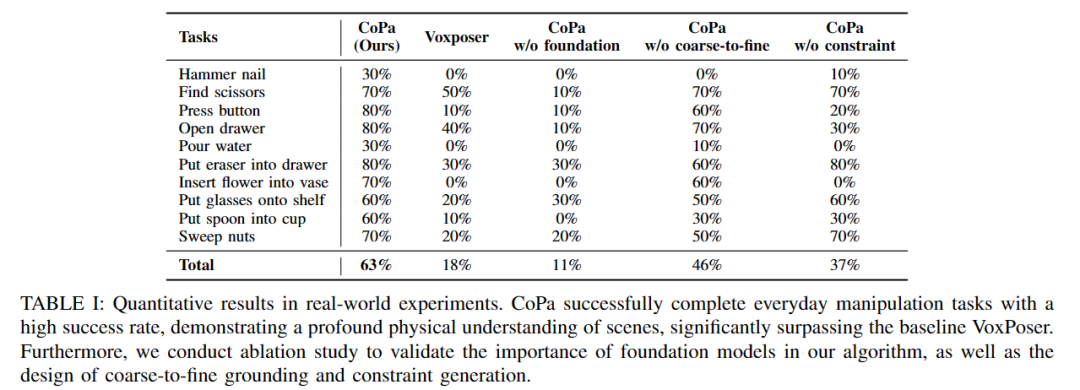
Das Forschungsteam führte ausreichend quantitative Experimente an 10 realen Aufgaben durch. Wie in Tabelle 1 gezeigt, übertrifft CoPa die Basismethoden sowie viele Ablationsvarianten bei diesen komplexen Aufgaben deutlich.
Ablationsexperimente
Die Forscher demonstrierten die Bedeutung der folgenden drei Komponenten im CoPa-Framework durch eine Reihe von Ablationsexperimenten: Basismodell, Grob-zu-Fein-Teilerkennung und Erzeugung räumlicher Restriktionen. Die Versuchsergebnisse sind in Tabelle 1 oben aufgeführt.
Basismodell
Das CoPa-Experiment ohne Fundamentablation in der Tabelle macht die Verwendung des Basismodells in CoPa überflüssig und verwendet stattdessen ein Erkennungsmodell zum Lokalisieren von Objekten und eine regelbasierte Methode zum Generieren räumlicher Einschränkungen. Die experimentellen Ergebnisse zeigen, dass die Erfolgsquote dieser Ablationsvariante sehr gering ist, was die wichtige Rolle des umfassenden gesunden Menschenverstandswissens beweist, das im Grundmodell von CoPa enthalten ist. Beispielsweise weiß die Ablationsvariante bei der Aufgabe „Sweeping Nuts“ nicht, welches Werkzeug in der Szene zum Fegen geeignet ist.
Erkennung von Grob-zu-Fein-Teilen
Das CoPa-Experiment ohne Grob-zu-Fein-Ablation in der Tabelle entfernt das CoPa-Design zur Erkennung von Grob-zu-Fein-Teilen und verwendet stattdessen direkt die feinkörnige Segmentierung Objekte lokalisieren. Diese Variante beeinträchtigt die Leistung bei der relativ schwierigen Aufgabe, wichtige Teile eines Objekts zu lokalisieren, erheblich. Beispielsweise ist es bei der Aufgabe „Einen Nagel einschlagen“ aufgrund des fehlenden „Grob-Fein“-Designs schwierig, die Hammeroberfläche zu identifizieren.
Erzeugung räumlicher Einschränkungen
Das CoPa-Experiment ohne Einschränkungsablation in der Tabelle entfernt das Modul zur Erzeugung räumlicher Einschränkungen von CoPa und ermöglicht stattdessen dem großen visuellen Sprachmodell, die spezifischen Werte des Roboters direkt auszugeben Zielpose. Experimente zeigen, dass es sehr schwierig ist, die Roboterzielpose basierend auf Szenenbildern direkt auszugeben. Beispielsweise muss bei der Aufgabe „Wasser gießen“ der Wasserkocher in einem bestimmten Winkel geneigt werden, und diese Variante ist zu diesem Zeitpunkt überhaupt nicht in der Lage, die Haltung des Roboters zu erzeugen.
Weitere Informationen finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt von. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Software zur Website-Erstellung
Software zur Website-Erstellung Verwendung der URL-Code-Funktion
Verwendung der URL-Code-Funktion So verwenden Sie die magnetische Btbook-Suche
So verwenden Sie die magnetische Btbook-Suche Audiokomprimierung
Audiokomprimierung So lösen Sie das Problem, dass der Geräte-Manager nicht geöffnet werden kann
So lösen Sie das Problem, dass der Geräte-Manager nicht geöffnet werden kann js-Methode zum Löschen des Knotens
js-Methode zum Löschen des Knotens Methoden zur Reparatur von Datenbankschwachstellen
Methoden zur Reparatur von Datenbankschwachstellen Es ist nicht möglich, das Standard-Gateway des Computers zu reparieren
Es ist nicht möglich, das Standard-Gateway des Computers zu reparieren
























