


... gestartet wurde, belegte es den zweiten Platz auf der GitHub-Hotlist.
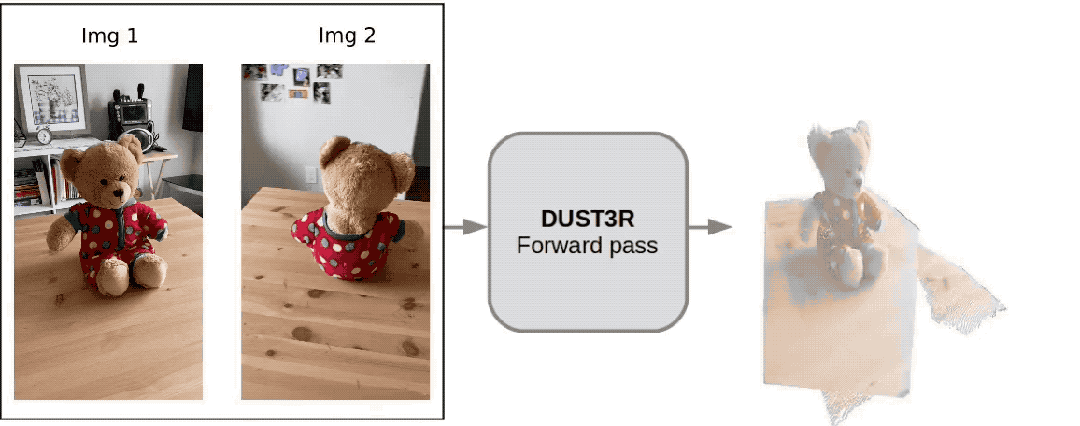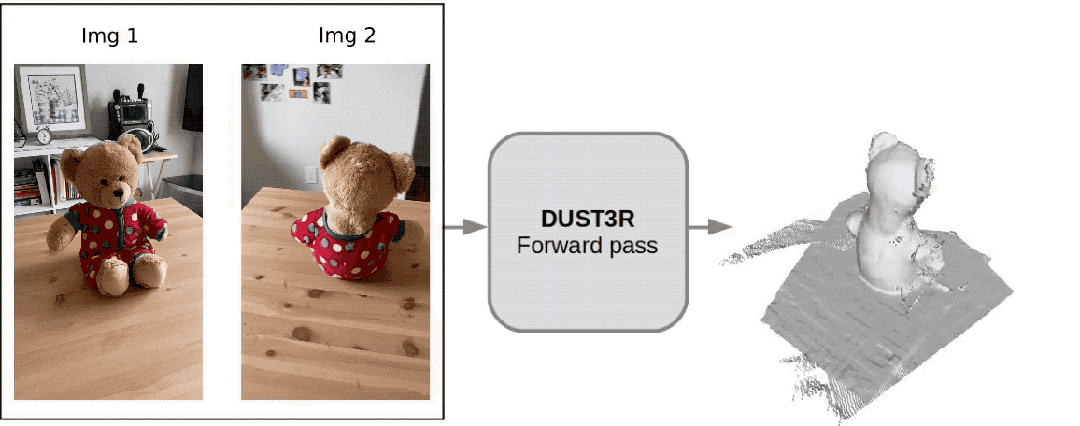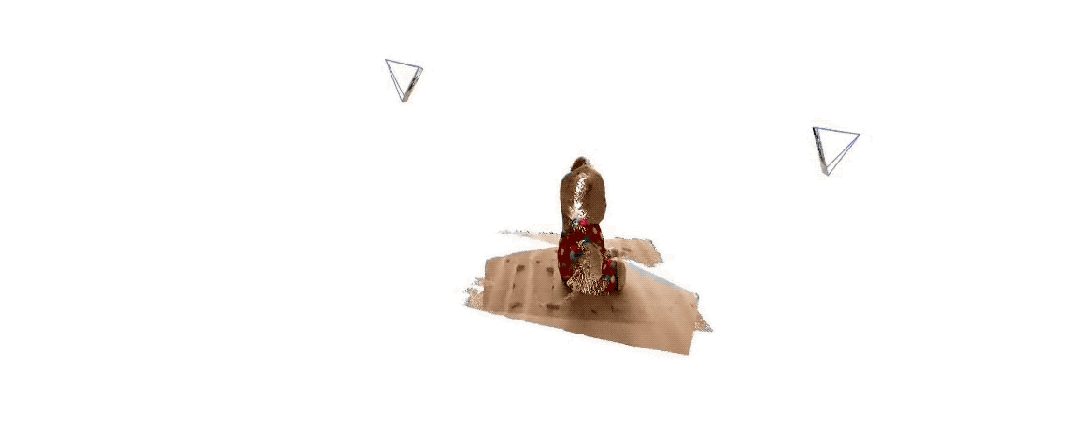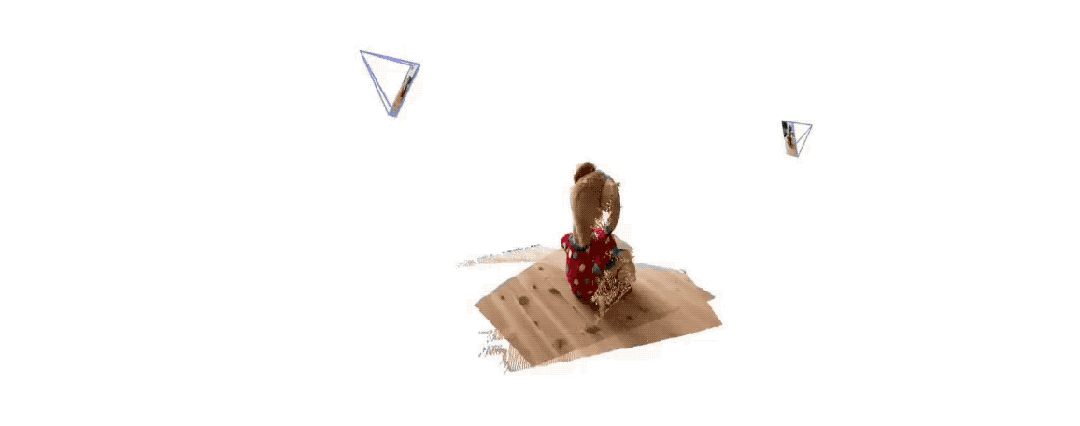 Ein
Ein
Internetnutzer hat tatsächlich getestet und zwei Fotos gemacht, um seine Küche wirklich zu rekonstruieren. Der gesamte Vorgang dauerte weniger als 2 Sekunden!
(Zusätzlich zu 3D-Karten können auch Tiefenkarten, Vertrauenskarten und Punktwolkenkarten bereitgestellt werden)
Dieser Freund war so schockiert, dass er sagte: Alle
Vergiss zuerst SoraNun, das ist es, was wir wirklich sehen und anfassen können.
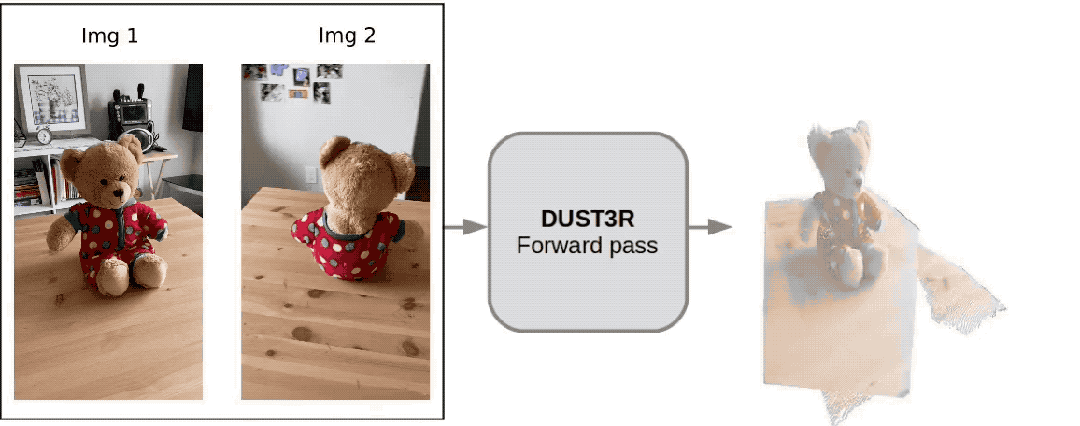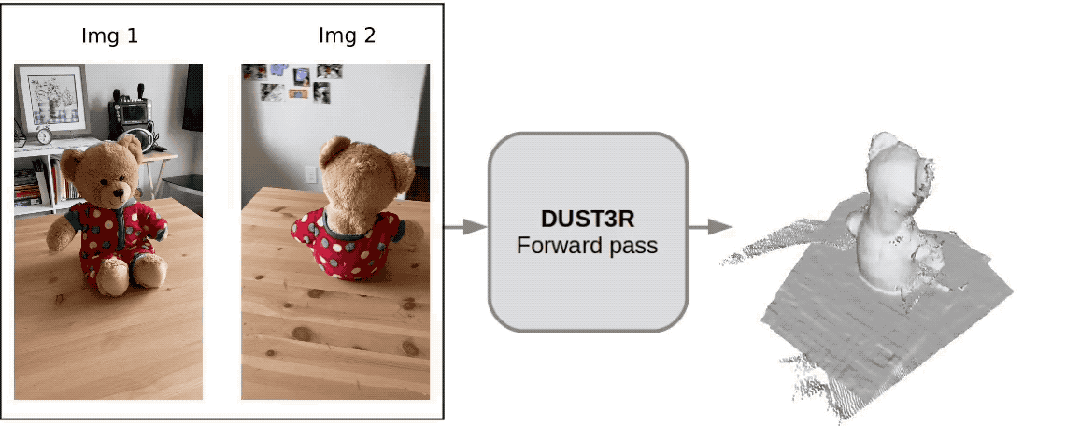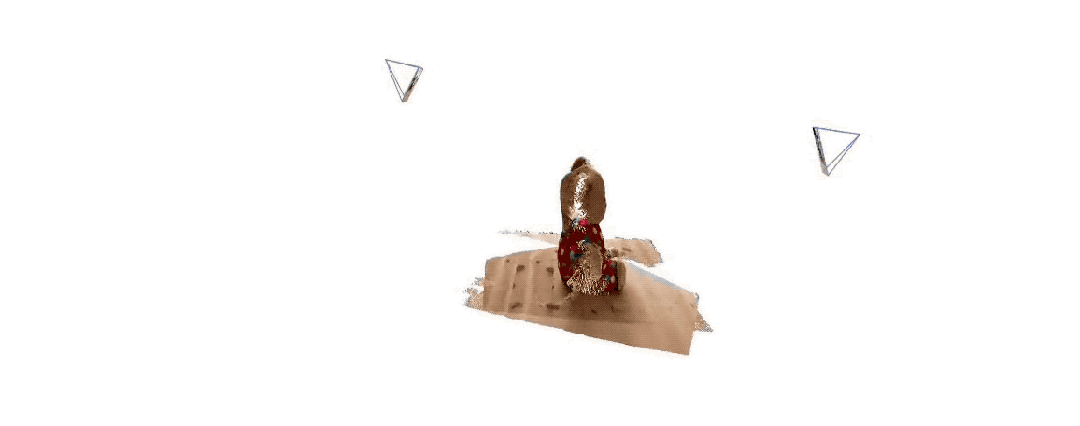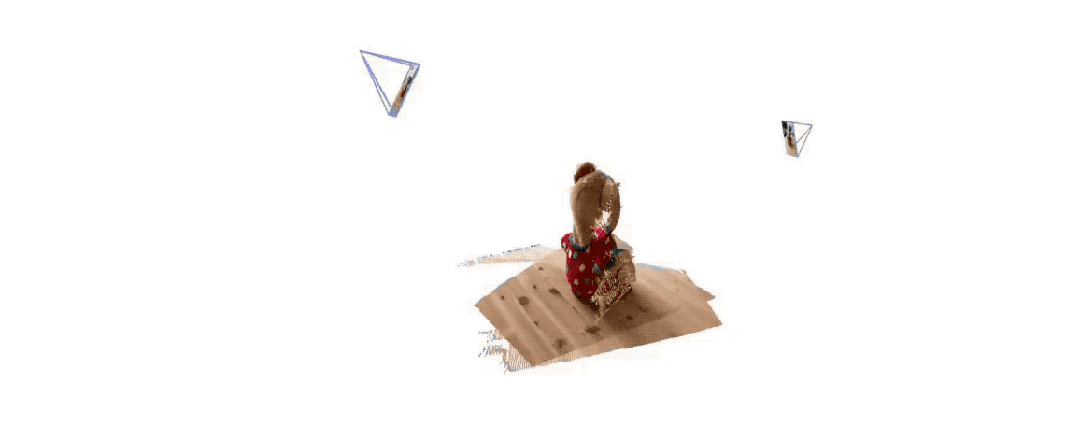
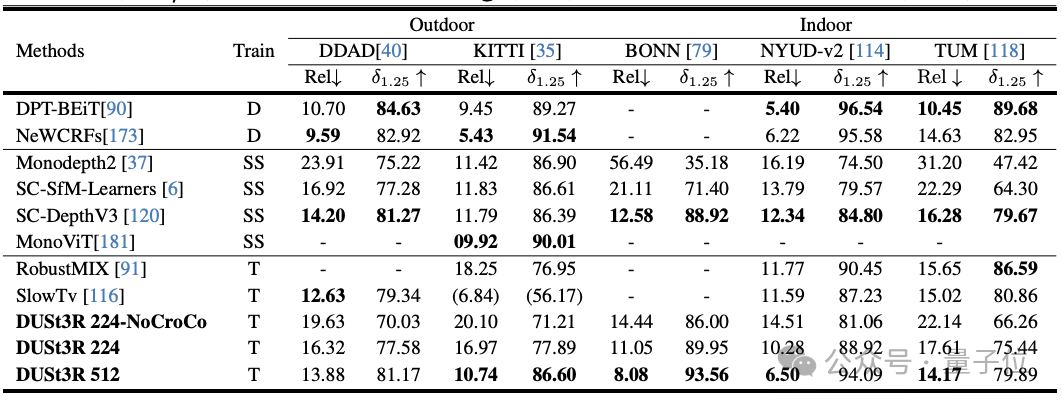
Experimente zeigen, dass DUSt3R SOTA in den drei Aufgaben der Monokular-/Multiview-Tiefenschätzung und der relativen Posenschätzung erreicht.
Das „Manifest“ des Autorenteams(von der Aalto-Universität, Finnland + NAVER LABS Artificial Intelligence Research Institute European Branch) ist ebenfalls voller Schwung: Wir wollen die Welt nicht mehr schwer zu lösenden 3D-Visionen machen Aufgaben.
Also, wie geht das? 
(MVS) besteht der erste Schritt darin, die Kameraparameter, einschließlich interner und externer Parameter, zu schätzen.
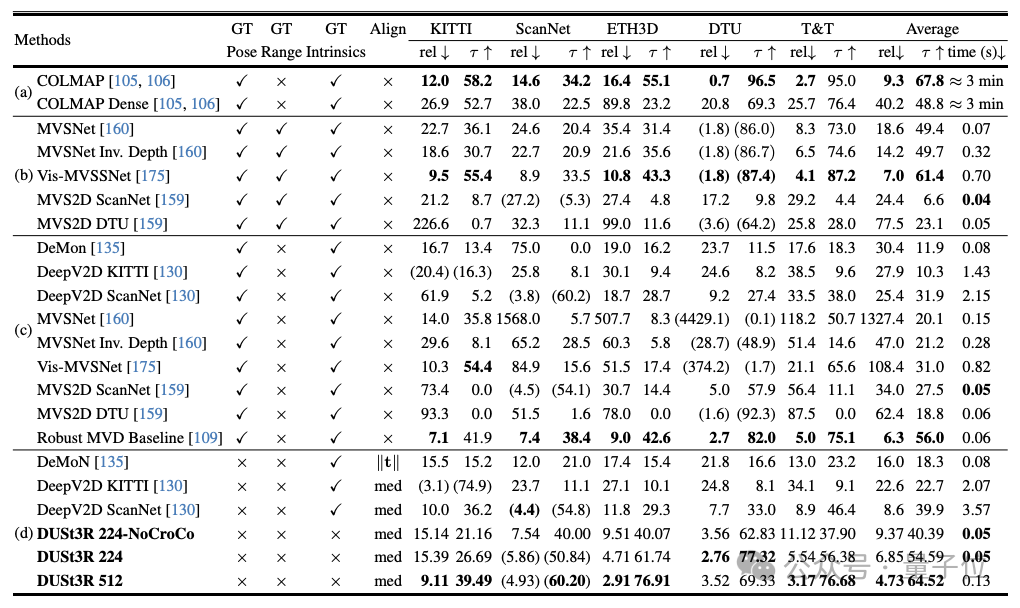
Dieser Vorgang ist langweilig und mühsam, aber für die anschließende Triangulation von Pixeln im dreidimensionalen Raum unverzichtbar und ein untrennbarer Bestandteil fast aller MVS-Algorithmen mit besserer Leistung.Eserfordert keine vorherigen Informationen zur Kamerakalibrierung oder Blickwinkelposition und kann eine dichte oder uneingeschränkte 3D-Rekonstruktion beliebiger Bilder durchführen.Beim Studium dieses Artikels verfolgte das vom Autorenteam vorgestellte DUSt3R einen völlig anderen Ansatz.
Hier formuliert das Team das paarweise Rekonstruktionsproblem als Point-Plot-Regression und vereinheitlicht die monokularen und binokularen Rekonstruktionssituationen.
Wenn mehr als zwei Eingabebilder bereitgestellt werden, werden alle Punktbildpaare durch eine einfache und effektive globale Ausrichtungsstrategie in einem gemeinsamen Referenzrahmen dargestellt. Wie in der Abbildung unten gezeigt, gibt DUSt3R bei einer Reihe von Fotos mit unbekannten Kamerapositionen und intrinsischen Merkmalen eine entsprechende Reihe von Punktkarten aus, aus denen wir verschiedene geometrische Größen, die normalerweise schwer gleichzeitig abzuschätzen sind, direkt wiederherstellen können, wie z Kameraparameter, Pixelkorrespondenz, Tiefenkarte und vollständig konsistenter 3D-Rekonstruktionseffekt.(Der Autor erinnert daran, dass DUSt3R auch für ein einzelnes Eingabebild geeignet ist)
In Bezug auf die spezifische Netzwerkarchitektur basiert DUSt3R auf dem
Standard-Transformer-Encoder und -Decoder
, der beeinflusst wurde von CroCo
(durch Cross Eine Studie zum selbstüberwachten Vortraining für 3D-Sehaufgaben wurde von inspiriert und mithilfe eines einfachen Regressionsverlusts trainiert. 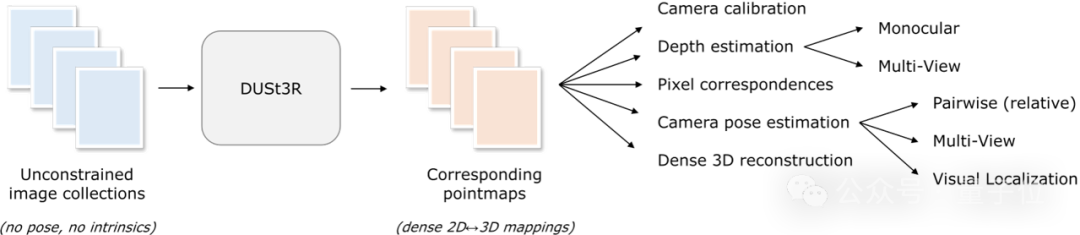
(I1, I2) der Szene zunächst mit dem gemeinsamen ViT-Encoder auf siamesische -Art codiert.
Die resultierende Token-Darstellung (F1 und F2) wird dann an zwei Transformer-Decoder übergeben, die durch gegenseitige Aufmerksamkeit kontinuierlich Informationen austauschen.
Schließlich geben die beiden Regressionsköpfe zwei entsprechende Punktkarten und zugehörige Konfidenzkarten aus.
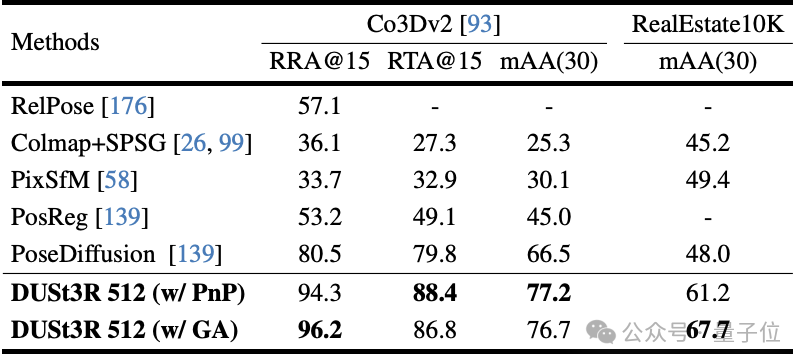
Der entscheidende Punkt ist, dass beide Punktdiagramme im gleichen Koordinatensystem des ersten Bildes dargestellt werden müssen.Das Experiment bewertete zunächst die Leistung von DUSt3R bei der absoluten Posenschätzungsaufgabe für die Datensätze 7Scenes (7 Innenszenen) und Cambridge Landmarks (8 Außenszenen). Die Indikatoren sind Übersetzungsfehler und Rotation. Fehler (je kleiner der Wert, desto besser) .
Der Autor gab an, dass die Leistung von DUSt3R im Vergleich zu anderen vorhandenen Feature-Matching- und End-to-End-Methoden bemerkenswert ist.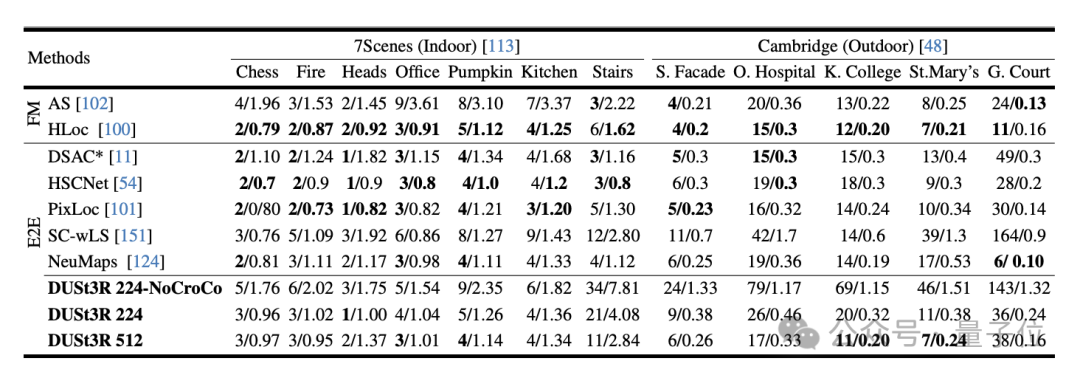



Einige Internetnutzer antworteten darauf, dass dies bedeute, dass diese Methode dort keine „objektiven Messungen“ durchführe, sondern sich eher wie eine KI verhalte.
Außerdem sind einige Leute neugierig,  ob die Methode noch funktioniert, wenn die Eingabebilder von zwei verschiedenen Kameras aufgenommen werden?
ob die Methode noch funktioniert, wenn die Eingabebilder von zwei verschiedenen Kameras aufgenommen werden?
Einige Internetnutzer haben es tatsächlich versucht, und die Antwort ist
Ja
Portal:
[1] Papier https://arxiv.org/abs/2312.14132 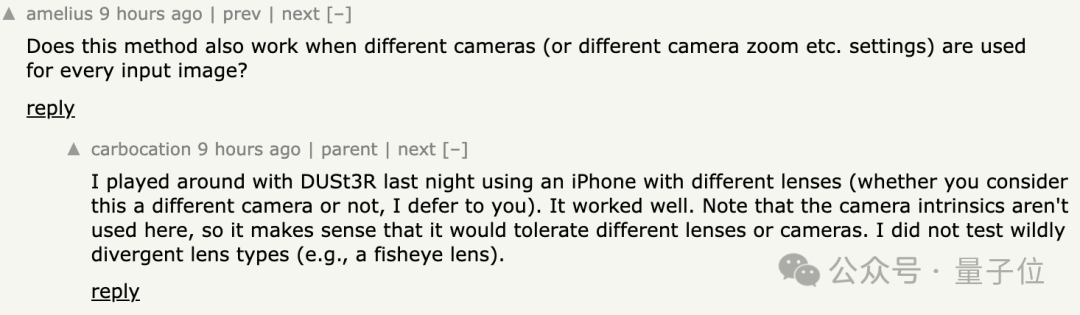
[2] Code https://github.com/naver/dust3r
Das obige ist der detaillierte Inhalt von3D-Rekonstruktion von zwei Bildern in 2 Sekunden! Dieses KI-Tool ist auf GitHub beliebt, Netizens: Vergessen Sie Sora. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



