


Mit Alibabas EMO ist es einfacher geworden, sich mit KI-generierten oder realen Bildern zu „bewegen, zu sprechen oder zu singen“.
Vor kurzem ist das von OpenAI Sora vertretene Vincent-Videomodell wieder populär geworden.
Neben textgenerierten Videos hat die menschzentrierte Videosynthese schon immer große Aufmerksamkeit erregt. Konzentrieren Sie sich beispielsweise auf die Videogenerierung „Sprecherkopf“, bei der das Ziel darin besteht, Gesichtsausdrücke auf der Grundlage von vom Benutzer bereitgestellten Audioclips zu generieren.
Auf technischer Ebene erfordert die Generierung von Ausdrücken die genaue Erfassung der subtilen und vielfältigen Gesichtsbewegungen des Sprechers, was bei ähnlichen Videosyntheseaufgaben eine große Herausforderung darstellt.
Herkömmliche Methoden bringen normalerweise einige Einschränkungen mit sich, um die Aufgabe der Videoerstellung zu vereinfachen. Einige Methoden nutzen beispielsweise 3D-Modelle, um wichtige Gesichtspunkte einzuschränken, während andere Kopfbewegungssequenzen aus Rohvideos extrahieren, um die Gesamtbewegung zu steuern. Während diese Einschränkungen die Komplexität der Videoerstellung verringern, schränken sie auch die Fülle und Natürlichkeit der endgültigen Gesichtsausdrücke ein.
In einem kürzlich vom Ali Intelligent Computing Research Institute veröffentlichten Artikel konzentrierten sich Forscher auf die Erforschung der subtilen Verbindung zwischen Audiohinweisen und Gesichtsbewegungen, um die Authentizität, Natürlichkeit und Ausdruckskraft des Kopfvideos des Sprechers zu verbessern.
Forscher haben herausgefunden, dass traditionelle Methoden oft nicht in der Lage sind, die Gesichtsausdrücke und einzigartigen Stile verschiedener Sprecher angemessen zu erfassen. Daher schlugen sie das EMO-Framework (Emote Portrait Alive) vor, das Gesichtsausdrücke direkt durch eine Audio-Video-Synthesemethode wiedergibt, ohne 3D-Zwischenmodelle oder Gesichtsorientierungspunkte zu verwenden.

Papiertitel: EMO: Emote Portrait Alive – Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Papieradresse: https://arxiv.org/pdf/2402.17485.pdf
Projekt-Homepage: https://humanaigc.github.io/emote-portrait-alive/
In Bezug auf die Wirkung kann Alis Methode einen nahtlosen Bildübergang im gesamten Video gewährleisten und eine konsistente Identität aufrechterhalten, wodurch Leistung erzeugt wird Das realistischere Charakter-Avatar-Video ist hinsichtlich Ausdruckskraft und Realismus deutlich besser als die aktuelle SOTA-Methode.
Zum Beispiel kann EMO die von Sora generierte Tokio-Mädchenfigur zum Singen bringen. Das Lied ist „Don't Start Now“, gesungen von der britisch-albanischen Sängerin Dua Lipa.  EMO unterstützt Songs in verschiedenen Sprachen, einschließlich Englisch und Chinesisch. Es kann die Tonänderungen des Audios intuitiv erkennen und dynamische und ausdrucksstarke KI-Charakter-Avatare generieren. Lassen Sie zum Beispiel die vom KI-Malmodell ChilloutMix generierte junge Dame „Melody“ von Tao Zhe singen.
EMO unterstützt Songs in verschiedenen Sprachen, einschließlich Englisch und Chinesisch. Es kann die Tonänderungen des Audios intuitiv erkennen und dynamische und ausdrucksstarke KI-Charakter-Avatare generieren. Lassen Sie zum Beispiel die vom KI-Malmodell ChilloutMix generierte junge Dame „Melody“ von Tao Zhe singen. 
EMO kann es dem Avatar auch ermöglichen, mit rasanten Rap-Songs Schritt zu halten, beispielsweise indem er DiCaprio bittet, einen Abschnitt von „Godzilla“ des amerikanischen Rappers Eminem vorzutragen. 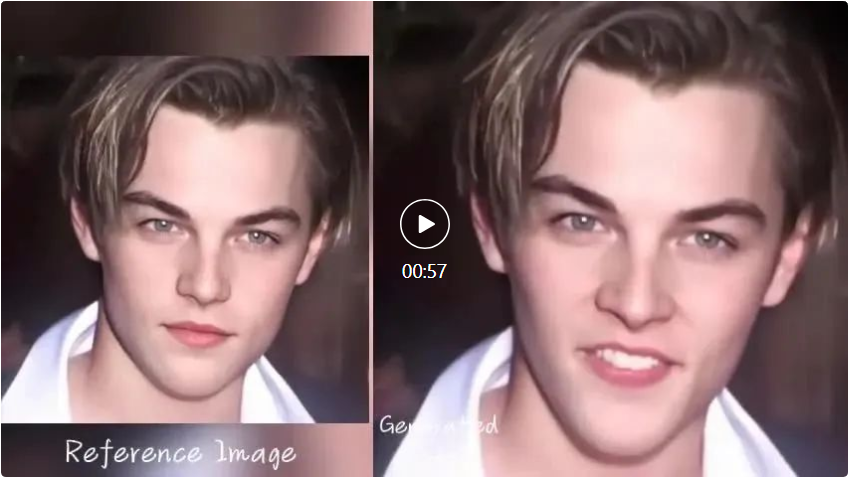 Natürlich ermöglicht EMO den Charakteren nicht nur das Singen, sondern unterstützt auch gesprochenes Audio in verschiedenen Sprachen und verwandelt verschiedene Stile von Porträts, Gemälden sowie 3D-Modellen und KI-generierten Inhalten in lebensechte animierte Videos. Wie zum Beispiel Audrey Hepburns Vortrag.
Natürlich ermöglicht EMO den Charakteren nicht nur das Singen, sondern unterstützt auch gesprochenes Audio in verschiedenen Sprachen und verwandelt verschiedene Stile von Porträts, Gemälden sowie 3D-Modellen und KI-generierten Inhalten in lebensechte animierte Videos. Wie zum Beispiel Audrey Hepburns Vortrag. 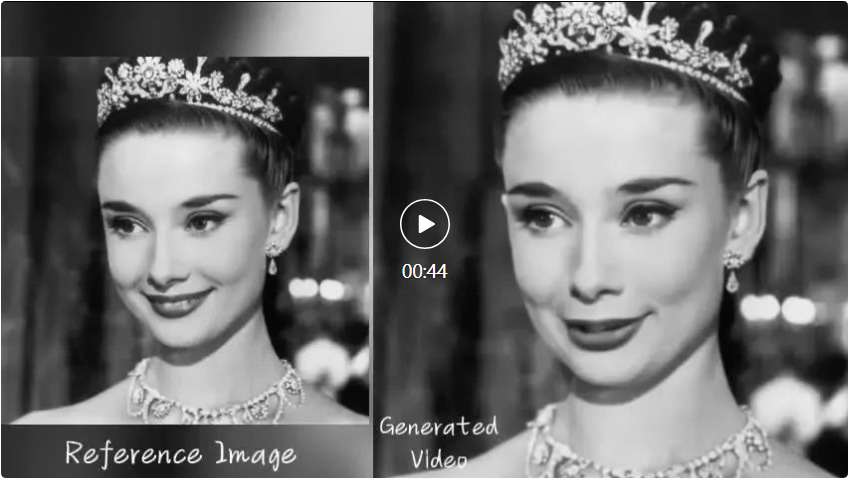
Schließlich kann EMO auch eine Verbindung zwischen verschiedenen Charakteren herstellen, wie zum Beispiel Gao Qiqiang, der sich in „Cyclone“ mit Lehrer Luo Xiang verbindet. 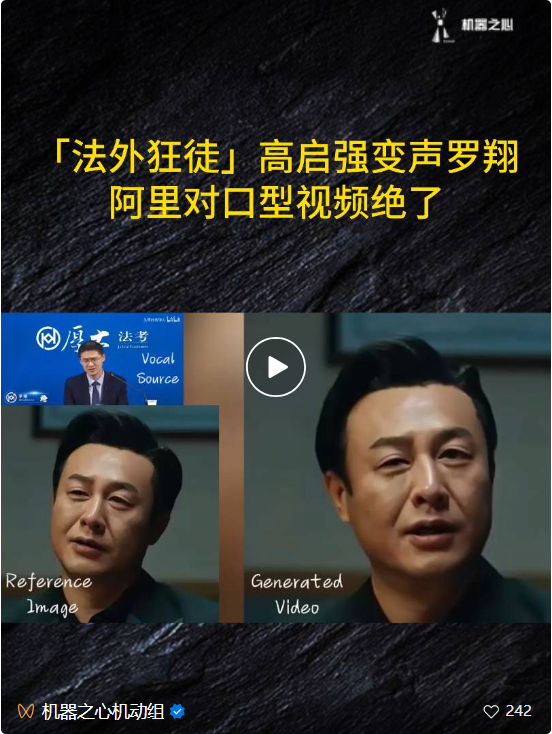
Methodenübersicht
Anhand eines einzelnen Referenzbilds eines Charakterporträts kann unsere Methode ein Video generieren, das mit dem Audioclip der eingegebenen Sprache synchronisiert ist, die sehr natürlichen Kopfbewegungen und lebendigen Ausdrücke des Charakters beibehält und mit den Tonhöhenänderungen des bereitgestellten Sprachaudios übereinstimmt . Koordination. Durch die Erstellung einer nahtlosen Reihe kaskadierender Videos trägt das Modell dazu bei, lange Videos sprechender Porträts mit konsistenter Identität und kohärenter Bewegung zu erstellen, die für Anwendungen in der realen Welt von entscheidender Bedeutung sind. Die Übersicht über die Methode „Network Pipeline“ ist in der folgenden Abbildung dargestellt. Das Backbone-Netzwerk empfängt mehrere Frames mit potenziellem Rauschen und versucht, diese bei jedem Zeitschritt in aufeinanderfolgende Videoframes zu entrauschen. Das Backbone-Netzwerk verfügt über eine ähnliche UNet-Strukturkonfiguration wie die ursprüngliche SD 1.5-Version, insbesondere
wie zuvor funktioniert es ähnlich. Um die Kontinuität zwischen generierten Frames sicherzustellen, ist im Backbone-Netzwerk ein zeitliches Modul eingebettet.
Trainingsstrategie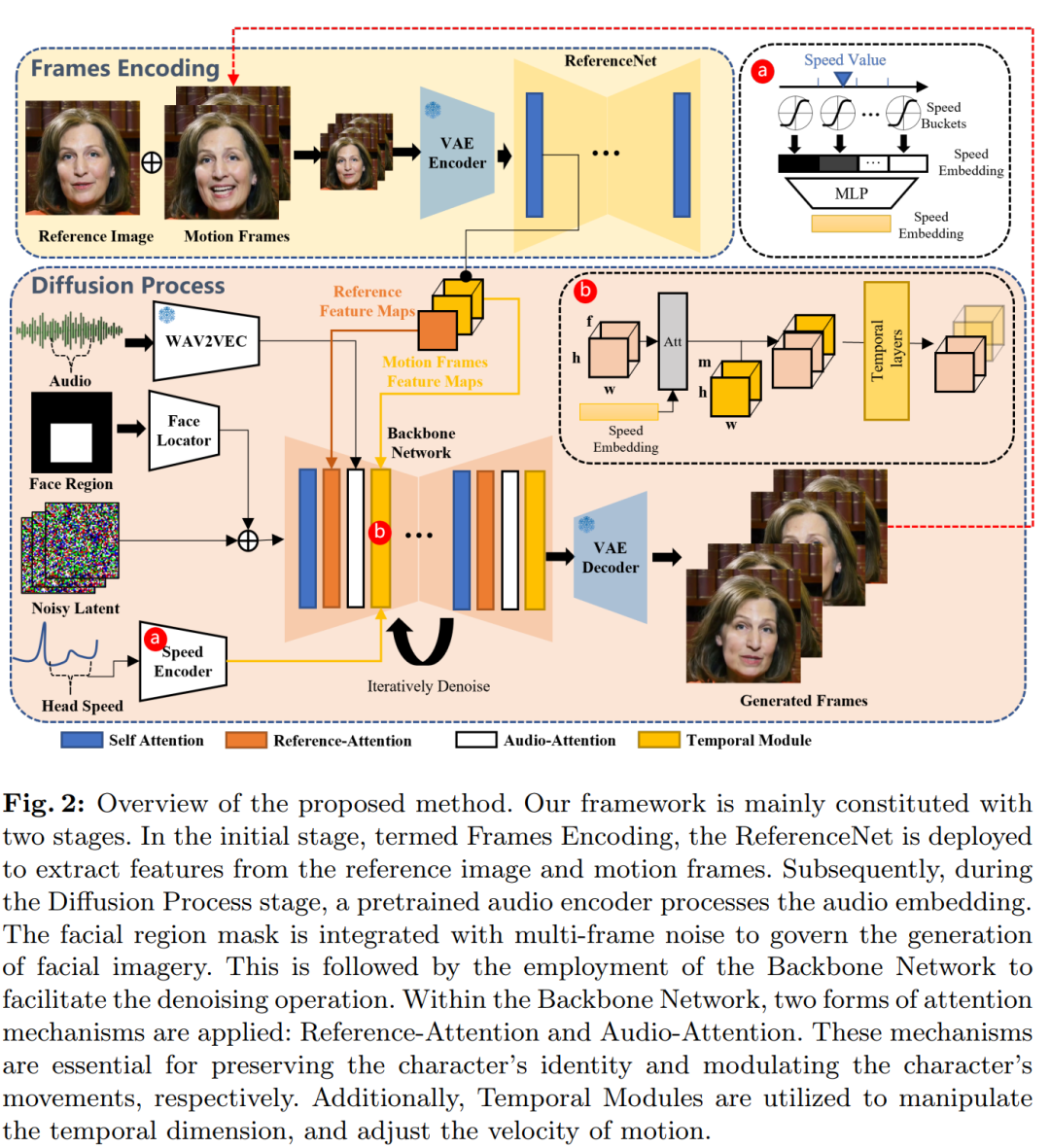
Der Trainingsprozess ist in drei Phasen unterteilt:
Die erste Phase ist das Bild-Vortraining, bei dem das Backbone-Netzwerk, ReferenceNet und der Gesichtslokalisierer in den Trainingsprozess integriert werden Das Backbone-Netzwerk wird in einem einzelnen Frame trainiert. Als Eingabe verarbeitet ReferenceNet verschiedene, zufällig ausgewählte Frames aus demselben Videoclip. Sowohl Backbone als auch ReferenceNet initialisieren Gewichte aus Roh-SD. In der zweiten Phase führten die Forscher ein Videotraining ein, fügten ein zeitliches Modul und eine Audioebene hinzu und probierten n+f aufeinanderfolgende Bilder aus dem Videoclip, wobei die ersten n Bilder Bewegungsbilder waren. Das Zeitmodul initialisiert die Gewichte von AnimateDiff.
Die letzte Stufe integriert die Geschwindigkeitsschicht, und der Forscher trainiert in dieser Stufe nur das Zeitmodul und die Geschwindigkeitsschicht. Dieser Ansatz dient dazu, die Audioschicht während des Trainings absichtlich zu ignorieren. Denn die Frequenz des Ausdrucks, der Mundbewegungen und der Kopfbewegungen des Sprechers werden hauptsächlich vom Ton beeinflusst. Daher scheint es eine Korrelation zwischen diesen Elementen zu geben, und das Modell steuert die Bewegung der Figur möglicherweise auf der Grundlage von Geschwindigkeitssignalen und nicht von Audio. Experimentelle Ergebnisse zeigen, dass das gleichzeitige Training der Geschwindigkeitsschicht und der Audioschicht die Fähigkeit von Audio schwächt, die Bewegung von Charakteren voranzutreiben.
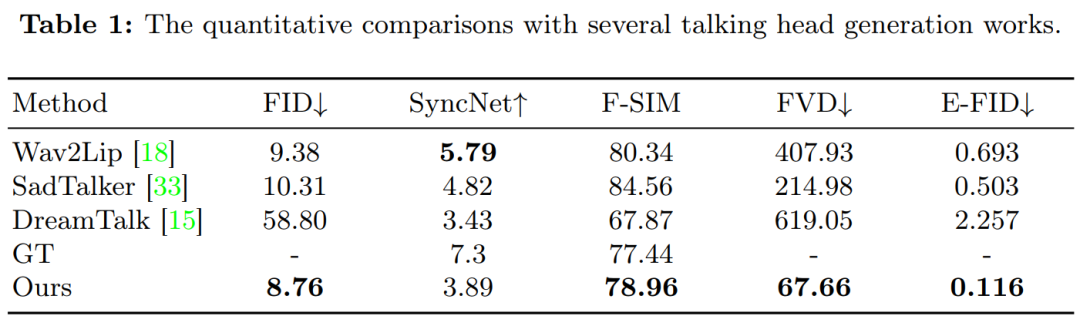
Experimentelle ErgebnisseZu den während des Experiments verglichenen Methoden gehören Wav2Lip, SadTalker und DreamTalk.
Abbildung 3 zeigt die Vergleichsergebnisse zwischen dieser Methode und früheren Methoden. Es ist zu beobachten, dass Wav2Lip bei Bereitstellung eines einzelnen Referenzbilds als Eingabe typischerweise einen unscharfen Mundbereich synthetisiert und Videos generiert, die durch statische Kopfhaltungen und minimale Augenbewegungen gekennzeichnet sind. Im Fall von DreamTalk können die Ergebnisse das ursprüngliche Gesicht verzerren und auch die Bandbreite an Gesichtsausdrücken und Kopfbewegungen einschränken. Im Vergleich zu SadTalker und DreamTalk ist die in dieser Studie vorgeschlagene Methode in der Lage, eine größere Bandbreite an Kopfbewegungen und lebendigere Gesichtsausdrücke zu erzeugen.
Diese Studie untersucht weiter die Erzeugung von Avatar-Videos in verschiedenen Porträtstilen, wie z. B. realistisch, Anime und 3D. Die Charaktere wurden mit demselben Sprach-Audio-Input animiert, und die Ergebnisse zeigten, dass die resultierenden Videos über die verschiedenen Stile hinweg eine ungefähr einheitliche Lippensynchronisation erzeugten.

Tabelle 1 Die Ergebnisse zeigen, dass diese Methode erhebliche Vorteile bei der Videoqualitätsbewertung hat: 
Das obige ist der detaillierte Inhalt vonLassen Sie das Mädchen Sora Tokyo singen, Gao Qiqiang ändert seine Stimme in Luo Xiang und das Lippensynchronisationsvideo des Alibaba-Charakters wird perfekt generiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So funktioniert der Temperatursensor
So funktioniert der Temperatursensor
 Der Unterschied zwischen vscode und vs
Der Unterschied zwischen vscode und vs
 Tutorial zum Ausführen von C++-Code
Tutorial zum Ausführen von C++-Code
 WeChat-Kampagne abbrechen
WeChat-Kampagne abbrechen
 So gehen Sie mit blockierten Dateidownloads in Windows 10 um
So gehen Sie mit blockierten Dateidownloads in Windows 10 um
 Verwendung von Fieldset-Tags
Verwendung von Fieldset-Tags
 So zeigen Sie HTML in der Mitte an
So zeigen Sie HTML in der Mitte an
 So springen Sie mit Parametern in vue.js
So springen Sie mit Parametern in vue.js












