


Im Bereich des autonomen Fahrens untersuchen Forscher auch die Richtung großer Modelle wie GPT/Sora.
Im Vergleich zur generativen KI ist das autonome Fahren auch einer der aktivsten Forschungs- und Entwicklungsbereiche in der jüngsten KI. Eine große Herausforderung beim Aufbau eines vollständig autonomen Fahrsystems ist das Szenenverständnis der KI, das komplexe, unvorhersehbare Szenarien wie Unwetter, komplexe Straßenführungen und unvorhersehbares menschliches Verhalten umfasst.
Das aktuelle autonome Fahrsystem besteht normalerweise aus drei Teilen: 3D-Wahrnehmung, Bewegungsvorhersage und Planung. Insbesondere wird die 3D-Wahrnehmung hauptsächlich zum Erkennen und Verfolgen bekannter Objekte verwendet, ihre Fähigkeit, seltene Objekte und ihre Eigenschaften zu identifizieren, ist jedoch begrenzt, während sich die Bewegungsvorhersage und -planung hauptsächlich auf die Flugbahnaktionen von Objekten konzentriert, die Beziehung zwischen Objekten und Fahrzeugen jedoch normalerweise ignoriert . Interaktionen auf Entscheidungsebene zwischen Diese Einschränkungen können die Genauigkeit und Sicherheit autonomer Fahrsysteme bei der Bewältigung komplexer Verkehrsszenarien beeinträchtigen. Daher muss die zukünftige autonome Fahrtechnologie weiter verbessert werden, um verschiedene Arten von Objekten besser zu identifizieren und vorherzusagen und den Fahrweg des Fahrzeugs effektiver zu planen, um die Intelligenz und Zuverlässigkeit des Systems zu verbessern
Der Schlüssel zum Erreichen des autonomen Fahrens Das Ziel ist um einen datengesteuerten Ansatz in einen wissensgesteuerten Ansatz umzuwandeln, der das Training großer Modelle mit logischen Argumentationsfähigkeiten erfordert. Nur so kann das autonome Fahrsystem das Long-Tail-Problem wirklich lösen und sich den L4-Fähigkeiten nähern. Da große Modelle wie GPT4 und Sora weiterhin auf dem Vormarsch sind, hat der Skaleneffekt auch leistungsstarke Wenig-Schuss-/Null-Schuss-Fähigkeiten gezeigt, was die Menschen dazu veranlasst hat, über eine neue Entwicklungsrichtung nachzudenken.
Die neueste Forschungsarbeit stammt vom Cross Information Institute der Tsinghua University und Li Auto und stellt ein neues Modell namens DriveVLM vor. Dieses Modell ist vom Visual Language Model (VLM) inspiriert, das im Bereich der generativen künstlichen Intelligenz auftaucht. DriveVLM hat hervorragende Fähigkeiten im visuellen Verständnis und Argumentation bewiesen.
Diese Arbeit ist die erste in der Branche, die ein autonomes Fahrgeschwindigkeitskontrollsystem vorschlägt. Ihre Methode kombiniert den gängigen autonomen Fahrprozess vollständig mit einem groß angelegten Modellprozess mit logischen Denkfähigkeiten und ist das erste Mal, dass ein großes System erfolgreich eingesetzt wird maßstabsgetreues Modell zum Testen auf ein Terminal übertragen (basierend auf der Orin-Plattform).
DriveVLM deckt einen Chain-of-Though (CoT)-Prozess ab, der drei Hauptmodule umfasst: Szenariobeschreibung, Szenarioanalyse und hierarchische Planung. Im Szenenbeschreibungsmodul wird Sprache verwendet, um die Fahrumgebung zu beschreiben und Schlüsselobjekte in der Szene zu identifizieren. Das Szenenanalysemodul untersucht eingehend die Eigenschaften dieser Schlüsselobjekte und ihre Auswirkungen auf autonome Fahrzeuge, während das hierarchische Planungsmodul schrittweise Pläne formuliert Die Elemente Aktionen und Entscheidungen werden zu Wegpunkten beschrieben.
Diese Module entsprechen den Wahrnehmungs-, Vorhersage- und Planungsschritten herkömmlicher autonomer Fahrsysteme. Der Unterschied besteht jedoch darin, dass sie die Objektwahrnehmung, die Vorhersage auf Absichtsebene und die Planung auf Aufgabenebene abwickeln, was in der Vergangenheit eine große Herausforderung darstellte.
Obwohl VLMs beim visuellen Verständnis gute Leistungen erbringen, weisen sie Einschränkungen bei der räumlichen Basis und beim Denken auf, und ihre Anforderungen an die Rechenleistung stellen eine Herausforderung für die Geschwindigkeit des endseitigen Denkens dar. Daher schlagen die Autoren weiterhin DriveVLMDual vor, ein Hybridsystem, das die Vorteile von DriveVLM und traditionellen Systemen vereint. DriveVLM-Dual integriert DriveVLM optional mit herkömmlichen 3D-Wahrnehmungs- und Planungsmodulen wie 3D-Objektdetektoren, Belegungsnetzwerken und Bewegungsplanern, wodurch das System 3D-Erdungs- und Hochfrequenzplanungsfunktionen erreichen kann. Dieses Dual-System-Design ähnelt den langsamen und schnellen Denkprozessen des menschlichen Gehirns und kann sich effektiv an unterschiedliche Komplexitäten in Fahrszenarien anpassen.
Die neue Forschung klärt außerdem die Definition von Szenenverständnis- und Planungsaufgaben (SUP) weiter und schlägt einige neue Bewertungsmetriken vor, um die Fähigkeiten von DriveVLM und DriveVLM-Dual bei der Szenenanalyse und Metaaktionsplanung zu bewerten. Darüber hinaus führten die Autoren umfangreiche Data-Mining- und Annotationsarbeiten durch, um einen internen SUP-AD-Datensatz für die SUP-Aufgabe zu erstellen.
Umfangreiche Experimente mit dem nuScenes-Datensatz und unseren eigenen Datensätzen zeigen die Überlegenheit von DriveVLM, insbesondere bei einer geringen Anzahl von Aufnahmen. Darüber hinaus übertrifft DriveVLM-Dual modernste End-to-End-Bewegungsplanungsmethoden.
Paper „DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models“

Paper-Link: https://arxiv.org/abs/2402.12289
Projekt-Link: https://tsinghua-mars- lab.github.io/DriveVLM/
Der Gesamtprozess von DriveVLM ist in Abbildung 1 dargestellt:
Kontinuierliche Bildbilder kodieren, mit LMM über das Feature-Alignment-Modul interagieren
Beginnen Sie mit der Szenenbeschreibung Denken Sie an das VLM-Modell und steuern Sie zunächst die statischen Szenen wie Zeit, Szene, Fahrspurumgebung usw. und dann die wichtigsten Hindernisse, die sich auf Fahrentscheidungen auswirken.
Analysieren Sie die wichtigsten Hindernisse und gleichen Sie sie durch herkömmliche 3D-Erkennung ab Von VLM verstandene Hindernisse bestätigen die Wirksamkeit von Hindernissen und beseitigen Illusionen und beschreiben die Eigenschaften der wichtigsten Hindernisse in diesem Szenario und ihre Auswirkungen auf unser Fahrverhalten
Gibt wichtige „Meta-Entscheidungen“ wie Verlangsamen, Parken, Links- und Rechtsabbiegen usw. und gibt dann eine Beschreibung der Fahrstrategie basierend auf den Meta-Entscheidungen und schließlich die zukünftige Fahrroute von das Trägerfahrzeug.
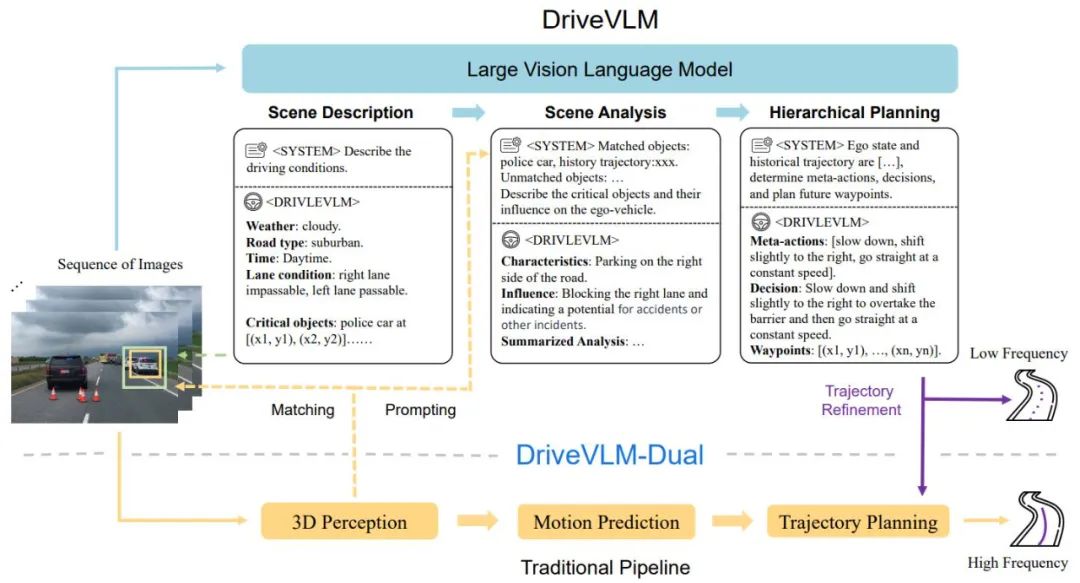
Abbildung 1. DriveVLM- und DriveVLM-Dual-Modellpipeline. Eine Bildsequenz wird von einem großen visuellen Sprachmodell (VLM) verarbeitet, um eine spezielle Gedankenkette (CoT) durchzuführen und daraus Fahrplanungsergebnisse abzuleiten. Großes VLM umfasst einen visuellen Transformator-Encoder und ein großes Sprachmodell (LLM). Ein visueller Encoder erzeugt Bild-Tags; ein aufmerksamkeitsbasierter Extraktor gleicht diese Tags dann mit einem LLM ab und schließlich führt der LLM eine CoT-Inferenz durch. Der CoT-Prozess kann in drei Module unterteilt werden: Szenariobeschreibung, Szenarioanalyse und hierarchische Planung.
DriveVLM-Dual ist ein Hybridsystem, das das umfassende Verständnis der Umgebung von DriveVLM und Vorschläge für Entscheidungsverläufe nutzt, um die Entscheidungs- und Planungsfähigkeiten der traditionellen Pipeline für autonomes Fahren zu verbessern. Es integriert 3D-Wahrnehmungsergebnisse in verbale Hinweise, um das Verständnis von 3D-Szenen zu verbessern, und verfeinert Flugbahn-Wegpunkte mit einem Echtzeit-Bewegungsplaner weiter.
Obwohl VLMs gut darin sind, Long-Tail-Objekte zu identifizieren und komplexe Szenen zu verstehen, haben sie oft Schwierigkeiten, die räumliche Position und den detaillierten Bewegungsstatus von Objekten genau zu verstehen, ein Mangel, der eine erhebliche Herausforderung darstellt. Erschwerend kommt hinzu, dass die enorme Modellgröße von VLM zu einer hohen Latenz führt und die Echtzeit-Reaktionsfähigkeit des autonomen Fahrens beeinträchtigt. Um diese Herausforderungen anzugehen, schlägt der Autor DriveVLM-Dual vor, das die Zusammenarbeit von DriveVLM und herkömmlichen autonomen Fahrsystemen ermöglicht. Dieser neue Ansatz umfasst zwei Schlüsselstrategien: Schlüsselobjektanalyse in Kombination mit 3D-Wahrnehmung, um hochdimensionale Fahrentscheidungsinformationen zu liefern, und Hochfrequenzverfeinerung der Flugbahn.
Um das Potenzial von DriveVLM und DriveVLMDual bei der Bewältigung komplexer und langwieriger Fahrszenarien voll auszuschöpfen, definierten die Forscher außerdem offiziell eine Aufgabe namens Szenenverständnisplanung sowie eine Reihe von Bewertungsmetriken. Darüber hinaus schlagen die Autoren ein Data-Mining- und Annotationsprotokoll vor, um das Szenenverständnis und die Planung von Datensätzen zu verwalten.
Um das Modell vollständig zu trainieren, hat der Autor eine Reihe von Drive LLM-Annotationstools und Annotationslösungen neu entwickelt. Durch eine Kombination aus automatisiertem Mining, Wahrnehmungsalgorithmus-Pre-Brushing, GPT-4-Zusammenfassung großer Modelle und manueller Annotation Mit diesem effizienten Annotationsschema wurde ein aktuelles Modell erstellt, in dem alle Clip-Daten Dutzende von Annotationsinhalten enthalten.

Der Autor schlug außerdem eine umfassende Data-Mining- und Annotations-Pipeline vor, wie in Abbildung 3 dargestellt, um einen SUP-AD-Datensatz (Scene Understanding for Planning in Autonomous Driving) für die vorgeschlagene Aufgabe zu erstellen, der mehr als 100.000 Bilder und mehr als 1.000 Bilder enthält. Textpaare. Insbesondere führen die Autoren zunächst Long-Tail-Objekt-Mining und anspruchsvolles Szenen-Mining aus einer großen Datenbank durch, um Proben zu sammeln. Anschließend wählen sie aus jeder Probe einen Keyframe aus und führen anschließend Szenenanmerkungen durch.
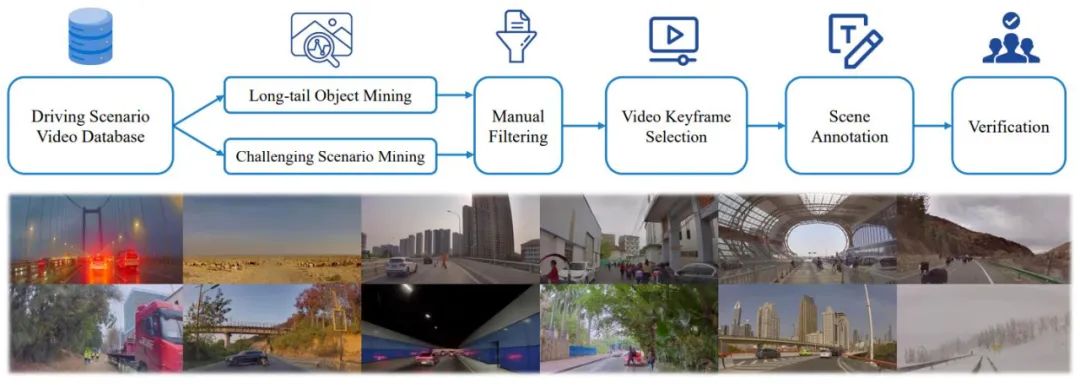
Abbildung 3. Data Mining- und Annotationspipeline zum Aufbau von Szenarioverständnissen und Planungsdatensätzen (oben). Beispiele für zufällig aus dem Datensatz (unten) entnommene Szenarien veranschaulichen die Vielfalt und Komplexität des Datensatzes.
SUP-AD ist in Trainings-, Verifizierungs- und Testteile im Verhältnis 7,5:1:1,5 unterteilt. Die Autoren trainieren das Modell auf der Trainingsaufteilung und verwenden neu vorgeschlagene Szenenbeschreibungen und Metaaktionsmetriken, um die Modellleistung auf der Validierungs-/Testaufteilung zu bewerten.
nuScenes-Datensatz ist ein groß angelegter Datensatz zum Fahren städtischer Szenen mit 1000 Szenen, die jeweils etwa 20 Sekunden dauern. Keyframes werden im gesamten Datensatz gleichmäßig mit 2 Hz annotiert. Hier verwenden die Autoren den Verschiebungsfehler (DE) und die Kollisionsrate (CR) als Indikatoren, um die Leistung des Modells bei der Verifizierungssegmentierung zu bewerten.
Die Autoren demonstrieren die Leistung von DriveVLM mit mehreren großen visuellen Sprachmodellen und vergleichen sie mit GPT-4V, wie in Tabelle 1 dargestellt. DriveVLM nutzt Qwen-VL als Rückgrat, das im Vergleich zu anderen Open-Source-VLMs die beste Leistung erzielt und sich durch Reaktionsfähigkeit und flexible Interaktion auszeichnet. Die ersten beiden großen Modelle waren Open-Source-Modelle und nutzten dieselben Daten für die Feinabstimmung des Trainings. GPT-4V nutzt komplexe Eingabeaufforderungen für die schnelle Entwicklung.
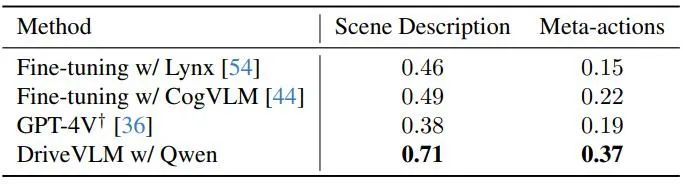
Tabelle 1. Testsatzergebnisse für den SUP-AD-Datensatz. Hier wird die offizielle API von GPT-4V verwendet und für Lynx und CogVLM werden Trainingssplits zur Feinabstimmung verwendet.
Wie in Tabelle 2 gezeigt, erreicht DriveVLM-Dual in Kombination mit VAD die Leistung auf dem neuesten Stand der Technik bei nuScenes-Planungsaufgaben. Dies zeigt, dass die neue Methode, obwohl sie auf das Verständnis komplexer Szenen zugeschnitten ist, auch in gewöhnlichen Szenen gut funktioniert. Beachten Sie, dass sich DriveVLM-Dual gegenüber UniAD erheblich verbessert: Der durchschnittliche Planungsverschiebungsfehler wird um 0,64 Meter und die Kollisionsrate um 51 % reduziert.
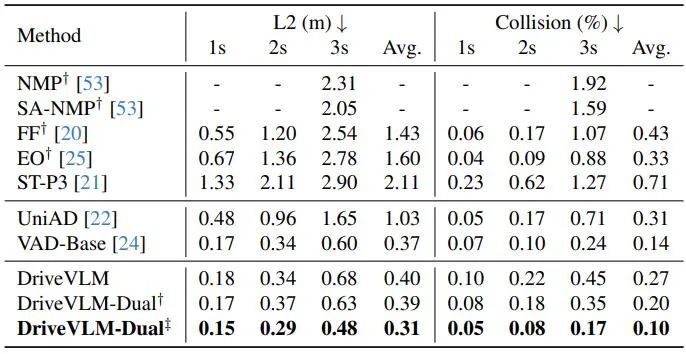
Tabelle 2. Planungsergebnisse für den nuScenes-Validierungsdatensatz. DriveVLM-Dual erreicht optimale Leistung. †Stellt Wahrnehmungs- und Belegungsvorhersageergebnisse mit Uni-AD dar. ‡ Zeigt die Arbeit mit VAD an, wobei alle Modelle Ego-Zustände als Eingabe verwenden. Abbildung 4. Qualitative Ergebnisse von DriveVLM. Die orangefarbene Kurve stellt die geplante zukünftige Flugbahn des Modells für die nächsten 3 Sekunden dar. 
Das obige ist der detaillierte Inhalt vonDie Tsinghua University und Ideal schlugen DriveVLM vor, ein visuelles großes Sprachmodell zur Verbesserung der autonomen Fahrfähigkeiten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



