Um Maschinen mit menschlicher Vorstellungskraft auszustatten, haben tiefe generative Modelle erhebliche Fortschritte gemacht. Diese Modelle erzeugen realistische Muster, insbesondere das Diffusionsmodell, das in mehreren Bereichen gute Ergebnisse liefert. Das Diffusionsmodell löst die Einschränkungen anderer Modelle, wie z. B. das Problem der hinteren Verteilungsausrichtung von VAEs, die Instabilität von GANs, die Rechenkomplexität von EBMs und das Netzwerkbeschränkungsproblem von NFs. Daher haben Diffusionsmodelle in Aspekten wie Computer Vision und Verarbeitung natürlicher Sprache große Aufmerksamkeit auf sich gezogen. Das Diffusionsmodell besteht aus zwei Prozessen: Vorwärtsprozess und Rückwärtsprozess. Der Vorwärtsprozess wandelt die Daten in eine einfache Prior-Verteilung um, während der Rückwärtsprozess diese Änderung umkehrt und die Daten mithilfe eines trainierten neuronalen Netzwerks generiert, um Differentialgleichungen zu simulieren. Im Vergleich zu anderen Modellen bietet das Diffusionsmodell ein stabileres Trainingsziel und bessere Generierungsergebnisse. 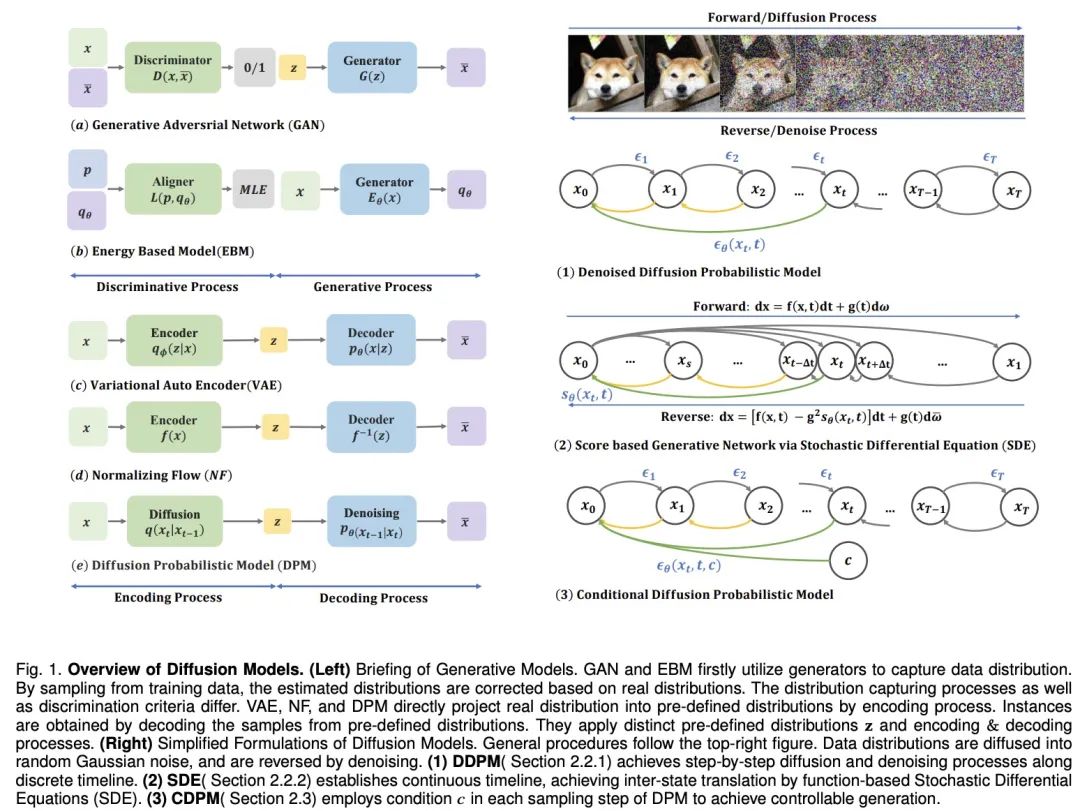
Der Stichprobenprozess des Diffusionsmodells wird jedoch von wiederholten Überlegungen und Bewertungen begleitet. Dieser Prozess steht vor Herausforderungen wie Instabilität, hochdimensionalen Rechenanforderungen und komplexer Likelihood-Optimierung. Zu diesem Zweck haben Forscher verschiedene Lösungen vorgeschlagen, beispielsweise die Verbesserung von ODE/SDE-Lösern und die Einführung von Modelldestillationsstrategien zur Beschleunigung der Probenentnahme sowie neue Vorwärtsprozesse zur Verbesserung der Stabilität und Reduzierung der Dimensionalität. Kürzlich haben Hong Kong Chinese Language and Literature, die West Lake University, das MIT und das Zhijiang Laboratory einen Übersichtsartikel mit dem Titel „A Survey on Generative Diffusion Models“ auf IEEE TKDE veröffentlicht, in dem die neuesten Fortschritte bei Diffusionsmodellen von vier Ländern erörtert wurden Aspekte: Stichprobenbeschleunigung, Prozessdesign, Wahrscheinlichkeitsoptimierung und Verteilungsüberbrückung. Der Bericht bietet außerdem einen detaillierten Einblick in den Erfolg von Diffusionsmodellen in verschiedenen Anwendungsbereichen wie Bildsynthese, Videogenerierung, 3D-Modellierung, medizinische Analyse und Textgenerierung. Anhand dieser Anwendungsfälle werden die Praktikabilität und das Potenzial des Diffusionsmodells in der realen Welt demonstriert. 
- Papieradresse: https://arxiv.org/pdf/2209.02646.pdf
- Projektadresse: https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model?tab= readme-ov-file
Verbessern Sie im Bereich des Diffusionsmodells die Abtastgeschwindigkeit Eine der Schlüsseltechnologien ist die Wissensdestillation. Bei diesem Prozess wird Wissen aus einem großen, komplexen Modell extrahiert und auf ein kleineres, effizienteres Modell übertragen. Mithilfe der Wissensdestillation können wir beispielsweise den Stichprobenverlauf des Modells vereinfachen, sodass die Zielverteilung bei jedem Schritt effizienter angenähert wird. Salimans et al. verwendeten einen auf gewöhnlichen Differentialgleichungen (ODE) basierenden Ansatz, um diese Trajektorien zu optimieren, während andere Forscher Techniken entwickelten, um saubere Daten direkt aus verrauschten Proben abzuschätzen und so den Prozess zum Zeitpunkt T zu beschleunigen.
Die Verbesserung der Trainingsmethode ist auch eine Möglichkeit, die Probenahmeeffizienz zu verbessern. Einige Forschungsarbeiten konzentrieren sich auf das Erlernen neuer Diffusionsschemata, bei denen die Daten nicht mehr einfach mit Gauß'schem Rauschen versetzt, sondern durch komplexere Methoden auf den latenten Raum abgebildet werden. Einige dieser Methoden konzentrieren sich auf die Optimierung des inversen Decodierungsprozesses, z. B. die Anpassung der Codierungstiefe, während andere neue Designs für Rauschskalen untersuchen, sodass das Hinzufügen von Rauschen nicht mehr statisch ist, sondern zu einer Variablen wird, die während des Trainingsprozesses geändert werden kann . Gelernte Parameter. - Trainingsfreie Probenahme
Neben dem Training neuer Modelle zur Verbesserung der Effizienz gibt es auch einige Techniken, die darauf abzielen, den Probenahmeprozess bereits vorab trainierter Diffusionsmodelle zu beschleunigen. Die ODE-Beschleunigung ist eine solche Technik, die ODEs verwendet, um den Diffusionsprozess zu beschreiben, wodurch die Probenentnahme schneller erfolgen kann. Beispielsweise ist DDIM eine Methode, die ODE für die Stichprobenentnahme nutzt, und nachfolgende Forschungen haben effizientere ODE-Löser wie PNDM und EDM eingeführt, um die Stichprobengeschwindigkeit weiter zu verbessern. - In Kombination mit anderen generativen Modellen
Darüber hinaus haben einige Forscher Analysemethoden vorgeschlagen, um die Probenentnahme zu beschleunigen. Diese Methoden versuchen, einen Weg zu finden, saubere Daten ohne Iteration direkt aus verrauschten Daten wiederherzustellen . Analytische Lösung. Zu diesen Methoden gehören Analytic-DPM und seine verbesserte Version Analytic-DPM++, die eine schnelle und genaue Probenahmestrategie bieten. - Latentraum-Diffusionsmodelle wie LSGM und INDM kombinieren VAE oder normalisierte Strömungsmodelle zur Entrauschung Die geteilte Gewichtung ist ein fraktionierter Matching-Verlust Wird zur Optimierung des Codecs und des Diffusionsmodells verwendet, sodass die Optimierung von ELBO oder Log-Likelihood darauf abzielt, einen latenten Raum aufzubauen, der leicht zu erlernen und Proben zu generieren ist. Beispielsweise verwendet Stable Diffusion zunächst eine VAE, um einen latenten Raum zu erlernen, und trainiert dann ein Diffusionsmodell, um Texteingaben zu akzeptieren. DVDP passt die orthogonalen Komponenten des Pixelraums während einer Bildstörung dynamisch an.
Innovativer Vorwärtsprozess- Um die Effizienz und Stärke des generativen Modells zu verbessern, haben Forscher neue Vorwärtsprozessdesigns erforscht. Das Poisson-Felderzeugungsmodell behandelt die Daten als Ladungen und lenkt eine einfache Verteilung auf die Datenverteilung entlang der elektrischen Feldlinien, was eine leistungsfähigere Rückabtastung als herkömmliche Diffusionsmodelle ermöglicht. PFGM++ führt dieses Konzept weiter auf hochdimensionale Variablen aus. Das kritisch gedämpfte Langevin-Diffusionsmodell von Dockhorn et al. vereinfacht das Lernen gebrochener Funktionen bedingter Geschwindigkeitsverteilungen mithilfe von Geschwindigkeitsvariablen in der Hamilton-Dynamik.
- Im Diffusionsmodell diskreter räumlicher Daten (z. B. Text, kategoriale Daten) definiert D3PM den Vorwärtsprozess des diskreten Raums. Basierend auf dieser Methode wurde die Forschung auf die Generierung von Sprachtexten, die Segmentierung von Diagrammen und die verlustfreie Komprimierung ausgeweitet. Bei multimodalen Herausforderungen werden vektorquantisierte Daten in Codes umgewandelt, die bessere Ergebnisse liefern. Mannigfaltige Daten in Riemannschen Mannigfaltigkeiten, wie z. B. Robotik und Proteinmodellierung, erfordern die Integration von Diffusionsproben in die Riemannsche Mannigfaltigkeit. Kombinationen aus graphischen neuronalen Netzen und Diffusionstheorie, wie etwa EDP-GNN und GraphGDP, verarbeiten Graphendaten, um die Permutationsinvarianz zu erfassen.
Wahrscheinlichkeitsoptimierung
Obwohl Diffusionsmodelle ELBO optimieren, bleibt die Wahrscheinlichkeitsoptimierung eine Herausforderung, insbesondere für zeitkontinuierliche Diffusionsmodelle. Methoden wie ScoreFlow und Variational Diffusion Models (VDM) stellen den Zusammenhang zwischen MLE-Training und DSM-Zielen her, wobei der Satz von Girsanov eine Schlüsselrolle spielt. Das verbesserte Denoising Diffusion Probabilistic Model (DDPM) schlägt ein hybrides Lernziel vor, das Variationsuntergrenzen und DSM sowie eine einfache Reparametrisierungstechnik kombiniert.Diffusionsmodelle eignen sich gut für die Umwandlung von Gaußschen Verteilungen in komplexe Verteilungen, weisen jedoch beim Zusammenführen beliebiger Verteilungen Probleme auf. Alpha-Hybrid-Methoden schaffen deterministische Brücken durch iteratives Mischen und Mischen. Der Korrekturfluss fügt zusätzliche Schritte zur Korrektur des Brückenpfads hinzu. Eine andere Methode besteht darin, die Verbindung zwischen zwei Verteilungen durch ODE zu realisieren, und die Methode der Schrödinger-Brücke oder der Gaußschen Verteilung als Zwischenverbindungspunkt wird ebenfalls untersucht. 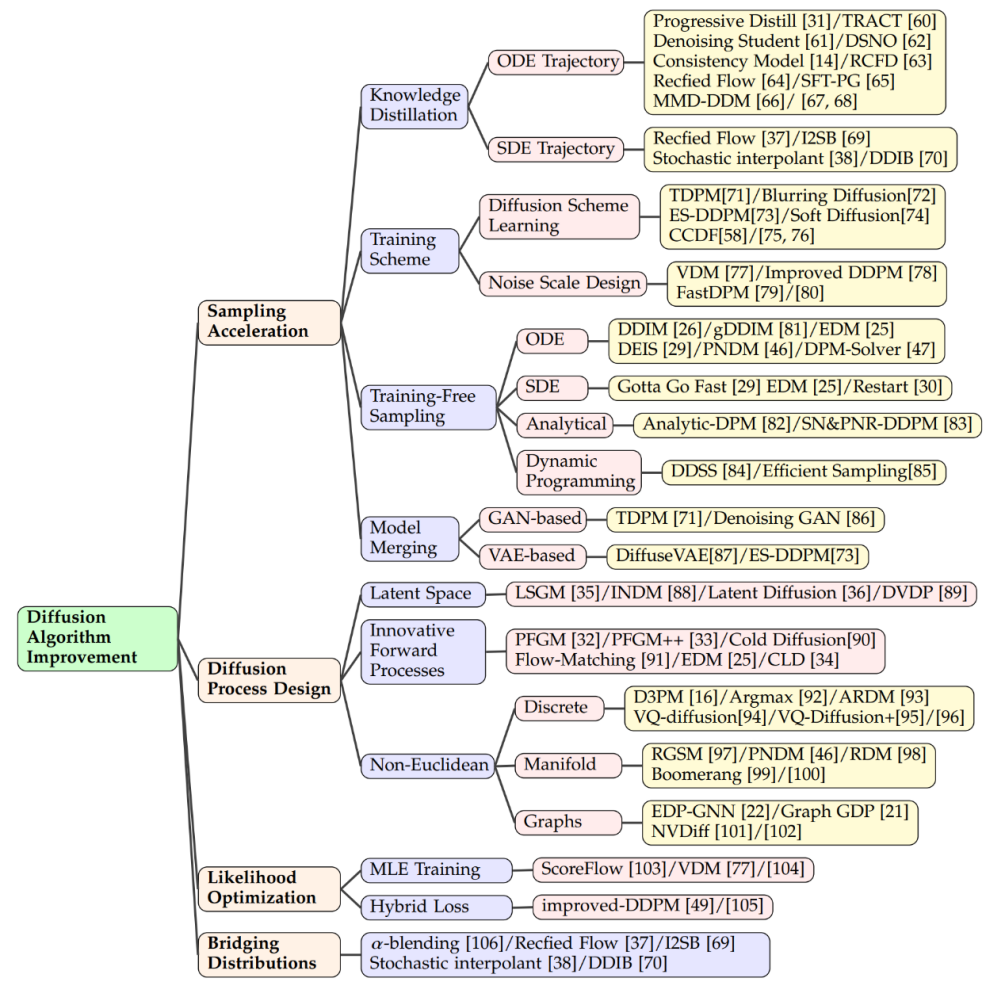
Das Diffusionsmodell ist sehr erfolgreich bei der Bilderzeugung. Es kann nicht nur gewöhnliche Bilder erzeugen, sondern auch komplexe Aufgaben erledigen, beispielsweise Text in Bilder umwandeln. Modelle wie Imagen, Stable Diffusion und DALL-E 2 beweisen diesbezüglich großes Können. Sie verwenden eine Diffusionsmodellstruktur in Kombination mit Cross-Attention-Layer-Techniken, um Textinformationen in generierte Bilder zu integrieren. Diese Modelle können nicht nur neue Bilder generieren, sondern auch Bilder bearbeiten, ohne dass eine Umschulung erforderlich ist. Die Bearbeitung erfolgt durch Anpassung über Aufmerksamkeitsebenen hinweg (Schlüssel, Werte, Aufmerksamkeitsmatrizen). Fügen Sie beispielsweise neue Konzepte hinzu, indem Sie Feature-Maps anpassen, um Bildelemente zu ändern, oder indem Sie neue Texteinbettungen einführen. Es gibt Untersuchungen, um sicherzustellen, dass das Modell bei der Generierung alle Schlüsselwörter des Textes berücksichtigt, um sicherzustellen, dass das Bild die Beschreibung genau widerspiegelt. Diffusionsmodelle können auch bildbasierte bedingte Eingaben wie Quellbilder, Tiefenkarten oder menschliche Skelette verarbeiten, indem sie diese Funktionen kodieren und integrieren, um die Bilderzeugung zu steuern. Einige Studien fügen der Startebene des Modells Funktionen zur Quellbildkodierung hinzu, um eine Bild-zu-Bild-Bearbeitung zu erreichen, die auch auf Szenen anwendbar ist, in denen Tiefenkarten, Kantenerkennung oder Skelette als Bedingungen verwendet werden. In Bezug auf die 3D-Generierung gibt es zwei Hauptmethoden durch Diffusionsmodelle. Die erste besteht darin, Modelle direkt auf 3D-Daten zu trainieren, die effektiv auf eine Vielzahl von 3D-Darstellungen wie NeRF, Punktwolken oder Voxel angewendet wurden. Forscher haben beispielsweise gezeigt, wie man Punktwolken aus 3D-Objekten direkt erzeugen kann. Um die Effizienz der Probenahme zu verbessern, haben einige Studien eine hybride Punkt-Voxel-Darstellung oder Bildsynthese als zusätzliche Bedingung für die Punktwolkenerzeugung eingeführt. Andererseits gibt es Studien, die Diffusionsmodelle verwenden, um NeRF-Darstellungen von 3D-Objekten zu verarbeiten, neue Ansichten zu synthetisieren und NeRF-Darstellungen durch das Training perspektivenbedingter Diffusionsmodelle zu optimieren. Der zweite Ansatz konzentriert sich auf die Nutzung von Vorkenntnissen über 2D-Diffusionsmodelle zur Generierung von 3D-Inhalten. Beispielsweise verwendet das Dreamfusion-Projekt ein Score-Destillation-Sampling-Ziel, um NeRF aus einem vorab trainierten Text-zu-Bild-Modell zu extrahieren und durch einen Gradientenabstiegsoptimierungsprozess gerenderte Bilder mit geringem Verlust zu erzielen. Auch dieser Prozess wurde weiter ausgebaut, um die Generierung zu beschleunigen. Videodiffusionsmodelle sind Erweiterungen von 2D-Bilddiffusionsmodellen. Sie generieren Videosequenzen durch Hinzufügen einer zeitlichen Dimension. Die Grundidee dieses Ansatzes besteht darin, der vorhandenen 2D-Struktur zeitliche Ebenen hinzuzufügen, um Kontinuität und Abhängigkeiten zwischen Videobildern zu modellieren. Verwandte Arbeiten zeigen, wie Videodiffusionsmodelle zum Generieren dynamischer Inhalte verwendet werden, z. B. Make-A-Video, AnimatedDiff und andere Modelle. Genauer gesagt verwendet das RaMViD-Modell ein 3D-Faltungs-Neuronales Netzwerk, um das Bilddiffusionsmodell auf Video zu erweitern, und entwickelt eine Reihe videospezifischer bedingter Techniken. Diffusionsmodelle helfen bei der Lösung der Herausforderung, qualitativ hochwertige Datensätze in der medizinischen Analyse, insbesondere in der medizinischen Bildgebung, zu erhalten. Aufgrund ihrer leistungsstarken Bilderfassungsfunktionen konnten diese Modelle die Bildauflösung, Klassifizierung und Rauschverarbeitung erfolgreich verbessern. Beispielsweise nutzen Score-MRI und Diff-MIC fortschrittliche Techniken, um die Rekonstruktion von MRT-Bildern zu beschleunigen und eine präzisere Klassifizierung zu ermöglichen. MCG nutzt vielfältige Korrekturen in der Superauflösung von CT-Bildern und verbessert so die Rekonstruktionsgeschwindigkeit und -genauigkeit. Im Hinblick auf die Generierung seltener Bilder kann das Modell mithilfe spezifischer Techniken zwischen verschiedenen Bildtypen konvertieren. Beispielsweise werden FNDM und DiffuseMorph zur Erkennung von Gehirnanomalien bzw. zur Registrierung von MR-Bildern verwendet. Einige neue Methoden synthetisieren Trainingsdatensätze aus einer kleinen Anzahl hochwertiger Stichproben, beispielsweise ein Modell mit 31.740 Stichproben, das einen Datensatz mit 100.000 Instanzen synthetisierte und sehr niedrige FID-Werte erzielte. Die Technologie zur Textgenerierung ist eine wichtige Brücke zwischen Menschen und KI und kann eine reibungslose und natürliche Sprache erzeugen. Autoregressive Sprachmodelle erzeugen Text mit starker Kohärenz, sind aber langsam, während Diffusionsmodelle Text schnell, aber mit relativ schwacher Kohärenz generieren können. Die beiden gängigen Methoden sind die diskrete Generation und die latente Generation. Die diskrete Generierung basiert auf fortschrittlichen Techniken und vorab trainierten Modellen. D3PM und Argmax behandeln beispielsweise Wörter als kategoriale Vektoren, während DiffusionBERT Diffusionsmodelle mit Sprachmodellen kombiniert, um die Textgenerierung zu verbessern. Die latente Generierung generiert Text im latenten Raum von Token. Modelle wie LM-Diffusion und GENIE leisten bei verschiedenen Aufgaben gute Dienste und zeigen das Potenzial von Diffusionsmodellen bei der Textgenerierung. Von Diffusionsmodellen wird erwartet, dass sie die Leistung bei der Verarbeitung natürlicher Sprache verbessern, sich in große Sprachmodelle integrieren und eine modalübergreifende Generierung ermöglichen. Die Modellierung von Zeitreihendaten ist eine Schlüsseltechnologie für Vorhersagen und Analysen in Bereichen wie Finanzen, Klimawissenschaften und Medizin. Diffusionsmodelle wurden bei der Generierung von Zeitreihendaten verwendet, da sie in der Lage sind, qualitativ hochwertige Datenproben zu generieren.In diesem Bereich werden Diffusionsmodelle häufig so konzipiert, dass sie die zeitliche Abhängigkeit und Periodizität von Zeitreihendaten berücksichtigen. Beispielsweise ist CSDI (Conditional Sequence Diffusion Interpolation) ein Modell, das eine bidirektionale Faltungs-Neuronale Netzwerkstruktur nutzt, um Zeitreihen-Datenpunkte zu generieren oder zu interpolieren. Es zeichnet sich durch die Generierung medizinischer Daten und Umweltdaten aus. Andere Modelle wie DiffSTG und TimeGrad können die dynamischen Eigenschaften von Zeitreihen besser erfassen und realistischere Zeitreihenstichproben generieren, indem sie raumzeitliche Faltungsnetzwerke kombinieren. Diese Modelle stellen durch Selbstkonditionierungsführung nach und nach aussagekräftige Zeitreihendaten aus dem Gaußschen Rauschen wieder her. Die Audiogenerierung umfasst mehrere Anwendungsszenarien von der Sprachsynthese bis zur Musikgenerierung. Da Audiodaten in der Regel komplexe zeitliche Strukturen und reichhaltige spektrale Informationen enthalten, zeigen Diffusionsmodelle auch in diesem Bereich Potenzial. WaveGrad und DiffSinger sind beispielsweise zwei Diffusionsmodelle, die einen bedingten Generierungsprozess nutzen, um hochwertige Audiowellenformen zu erzeugen. WaveGrad verwendet das Mel-Spektrum als bedingte Eingabe, während DiffSinger darüber hinaus zusätzliche musikalische Informationen wie Tonhöhe und Tempo hinzufügt, um eine feinere stilistische Kontrolle zu ermöglichen. In Text-to-Speech-Anwendungen (TTS) kombinieren Guided-TTS und Diff-TTS die Konzepte von Textkodierern und akustischen Klassifikatoren, um Sprache zu erzeugen, die sowohl dem Textinhalt entspricht als auch einem bestimmten Klangstil folgt. Guide-TTS2 demonstriert außerdem, wie Sprache ohne einen expliziten Klassifikator generiert werden kann, indem die Klangerzeugung durch vom Modell selbst gelernte Funktionen gesteuert wird. In Bereichen wie Arzneimitteldesign, Materialwissenschaften und chemischer Biologie ist molekulares Design ein wichtiger Schritt bei der Entdeckung und Synthese neuer Verbindungen. Diffusionsmodelle dienen hier als leistungsstarkes Werkzeug, um den chemischen Raum effizient zu erkunden und Moleküle mit spezifischen Eigenschaften zu erzeugen. Bei der bedingungslosen Molekülgenerierung erzeugt das Diffusionsmodell spontan molekulare Strukturen, ohne sich auf Vorkenntnisse zu verlassen. Bei der modalübergreifenden Generierung kann das Modell spezifische funktionelle Bedingungen wie die Arzneimittelwirksamkeit oder die Bindungsneigung eines Zielproteins berücksichtigen, um Moleküle mit den gewünschten Eigenschaften zu erzeugen. Sequenzbasierte Methoden berücksichtigen möglicherweise die Proteinsequenz als Steuerung für die Erzeugung von Molekülen, während strukturbasierte Methoden die dreidimensionalen Strukturinformationen des Proteins nutzen können. Solche Strukturinformationen können als Vorwissen beim molekularen Andocken oder beim Antikörperdesign genutzt werden, wodurch die Qualität der erzeugten Moleküle verbessert wird. Verwendet ein Diffusionsmodell zur Generierung von Diagrammen mit dem Ziel, reale Netzwerkstrukturen und Ausbreitungsprozesse besser zu verstehen und zu simulieren. Dieser Ansatz hilft Forschern, Muster und Wechselwirkungen in komplexen Systemen zu ermitteln und mögliche Ergebnisse vorherzusagen. Zu den Anwendungen gehören soziale Netzwerke, biologische Netzwerkanalysen und die Erstellung von Diagrammdatensätzen. Herkömmliche Methoden basieren auf der Generierung von Adjazenzmatrizen oder Knotenmerkmalen, diese Methoden weisen jedoch eine schlechte Skalierbarkeit und eine begrenzte Praktikabilität auf. Daher bevorzugen moderne Techniken zur Diagrammgenerierung die Erstellung von Diagrammen basierend auf bestimmten Bedingungen. Beispielsweise verwendet das PCFI-Modell einen Teil der Merkmale des Diagramms und Vorhersagen des kürzesten Pfads, um den Generierungsprozess zu steuern. EDGE und DiffFormer nutzen Knotengrad- und Energiebeschränkungen, um die Generierung zu optimieren. Diese Methoden verbessern die Genauigkeit und Praktikabilität der Diagrammerstellung. 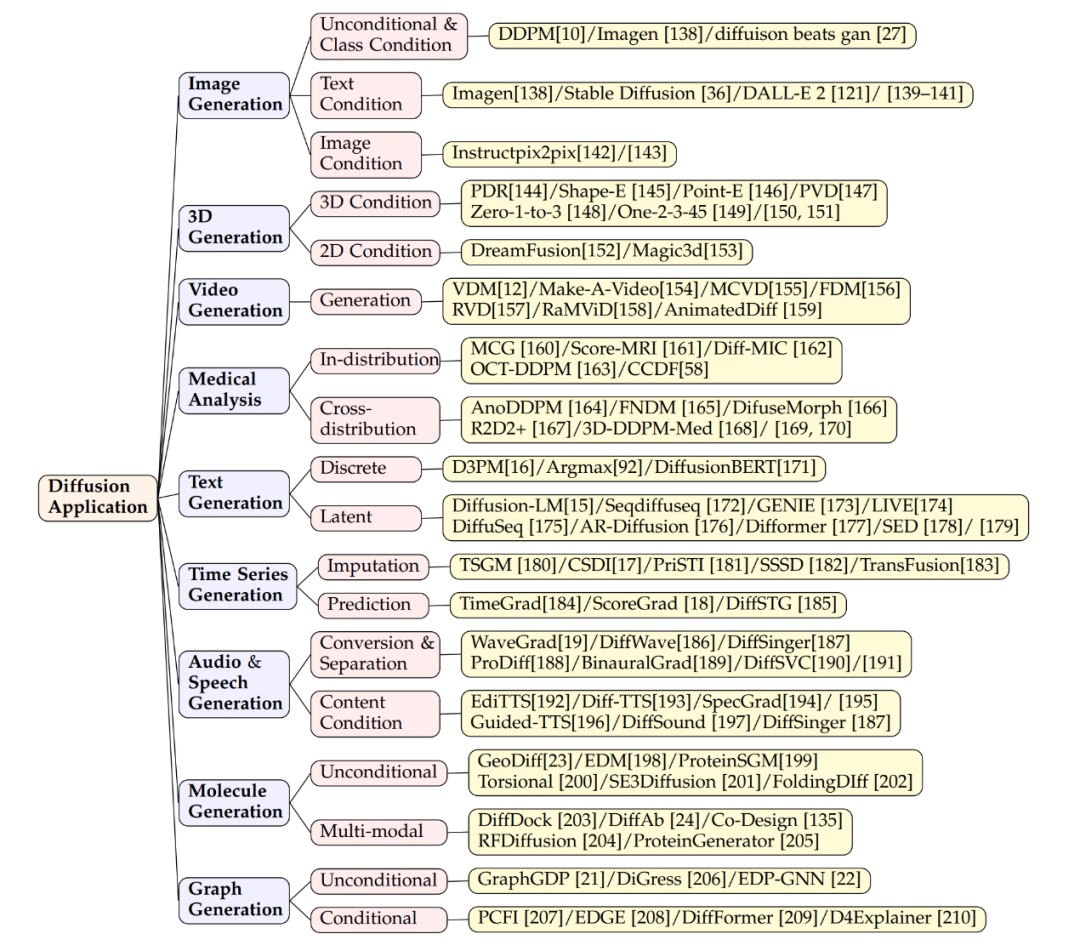
Fazit und Ausblick auf neue Szenarien oder Datensätze verallgemeinern. Darüber hinaus entstehen beim Umgang mit großen Datensätzen rechnerische Herausforderungen, wie z. B. längere Trainingszeiten, übermäßige Speichernutzung oder die Unfähigkeit, gewünschte Zustände zu erreichen, wodurch die Größe und Komplexität des Modells begrenzt wird. Darüber hinaus kann eine verzerrte oder ungleichmäßige Datenerfassung die Fähigkeit eines Modells einschränken, Ergebnisse zu generieren, die an verschiedene Domänen oder Populationen angepasst werden können.
Kontrollierbare verteilungsbasierte Generierung Die Verbesserung der Fähigkeit des Modells, Stichproben innerhalb einer bestimmten Verteilung zu verstehen und zu generieren, ist entscheidend, um eine bessere Verallgemeinerung mit begrenzten Daten zu erreichen. Durch die Konzentration auf die Identifizierung von Mustern und Korrelationen in den Daten kann das Modell Stichproben generieren, die den Trainingsdaten genau entsprechen und spezifische Anforderungen erfüllen. Dies erfordert eine effiziente Datenerfassung, Nutzungstechniken und die Optimierung von Modellparametern und -strukturen. Letztendlich ermöglicht dieses verbesserte Verständnis eine kontrolliertere und präzisere Generierung und verbessert dadurch die Generalisierungsleistung.
Erweiterte multimodale Generierung unter Verwendung großer Sprachmodelle Zukünftige Richtungen für Diffusionsmodelle umfassen die Weiterentwicklung der multimodalen Generierung durch Integration großer Sprachmodelle (LLMs). Durch diese Integration kann das Modell Ausgaben generieren, die Kombinationen aus Text, Bildern und anderen Modalitäten enthalten. Durch die Einbeziehung von LLMs wird das Verständnis des Modells für die Wechselwirkungen zwischen verschiedenen Modalitäten verbessert und die generierten Ergebnisse sind vielfältiger und realistischer. Darüber hinaus verbessern LLMs die Effizienz der prompt-basierten Generierung erheblich, indem sie die Verbindungen zwischen Text und anderen Modalitäten effektiv nutzen. Darüber hinaus verbessern LLMs als Katalysatoren die Generierungsfähigkeiten von Diffusionsmodellen und erweitern das Spektrum der Bereiche, in denen sie Moden erzeugen können.
Integration mit dem Bereich des maschinellen Lernens Die Kombination des Diffusionsmodells mit der traditionellen Theorie des maschinellen Lernens bietet neue Möglichkeiten, die Leistung verschiedener Aufgaben zu verbessern. Halbüberwachtes Lernen ist besonders wertvoll, wenn es darum geht, die inhärenten Herausforderungen von Diffusionsmodellen zu lösen, wie z. B. Generalisierungsprobleme, und eine effiziente Bedingungsgenerierung zu ermöglichen, wenn die Daten begrenzt sind. Durch die Nutzung unbeschrifteter Daten werden die Generalisierungsfähigkeiten von Diffusionsmodellen verbessert und eine ideale Leistung bei der Generierung von Proben unter bestimmten Bedingungen erreicht.
Darüber hinaus spielt das Reinforcement Learning eine entscheidende Rolle, indem es Feinabstimmungsalgorithmen verwendet, um eine gezielte Anleitung während des Sampling-Prozesses des Modells bereitzustellen. Diese Anleitung gewährleistet eine gezielte Erkundung und fördert eine kontrollierte Erzeugung. Darüber hinaus wird das verstärkende Lernen durch die Integration zusätzlicher Rückmeldungen bereichert und dadurch die Fähigkeit des Modells verbessert, kontrollierbare Bedingungen zu erzeugen.
Algorithmus-Verbesserungsmethode (Anhang)
Feldanwendungsmethode (Anhang)Das obige ist der detaillierte Inhalt vonDie Technologie hinter der Explosion von Sora, ein Artikel, der die neueste Entwicklungsrichtung von Diffusionsmodellen zusammenfasst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 Was tun, wenn die CPU-Temperatur zu hoch ist?
Was tun, wenn die CPU-Temperatur zu hoch ist?
 Was ist Systemsoftware?
Was ist Systemsoftware?
 So kaufen und verkaufen Sie Bitcoin legal
So kaufen und verkaufen Sie Bitcoin legal
 Was sind die Marquee-Parameter?
Was sind die Marquee-Parameter?
 So laden Sie den Razer-Maustreiber herunter
So laden Sie den Razer-Maustreiber herunter
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 0x80070057 Parameterfehlerlösung
0x80070057 Parameterfehlerlösung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



