


Obwohl visuelle Sprachmodelle (VLM) bei vielen Aufgaben erhebliche Fortschritte gemacht haben, darunter Bildbeschreibung, visuelle Beantwortung von Fragen, verkörperte Planung und Handlungserkennung, bestehen immer noch Herausforderungen beim räumlichen Denken. Viele Modelle haben immer noch Schwierigkeiten, den Standort oder die räumlichen Beziehungen von Zielen im dreidimensionalen Raum zu verstehen. Dies zeigt, dass es bei der Weiterentwicklung visueller Sprachmodelle notwendig ist, sich auf die Lösung des Problems des räumlichen Denkens zu konzentrieren, um die Genauigkeit und Effizienz des Modells bei der Verarbeitung komplexer visueller Aufgaben zu verbessern.
Forscher erforschen dieses Thema häufig anhand menschlicher körperlicher Erfahrungen und evolutionärer Entwicklung. Menschen verfügen über angeborene räumliche Denkfähigkeiten, die es ihnen ermöglichen, räumliche Beziehungen, wie etwa die relative Position von Objekten, leicht zu bestimmen und Entfernungen und Größen abzuschätzen, ohne dass komplexe Denkprozesse oder mentale Berechnungen erforderlich sind.
Diese Kompetenz bei direkten räumlichen Denkaufgaben steht im Gegensatz zu den Einschränkungen der aktuellen Fähigkeiten visueller Sprachmodelle und wirft eine zwingende Forschungsfrage auf: Können visuelle Sprachmodelle mit menschenähnlichen räumlichen Denkfähigkeiten ausgestattet werden?
Kürzlich hat Google ein visuelles Sprachmodell mit räumlichen Denkfähigkeiten vorgeschlagen: SpatialVLM.

Die Forscher glauben, dass die Einschränkungen des aktuellen visuellen Sprachmodells in Bezug auf räumliche Denkfähigkeiten möglicherweise nicht auf Einschränkungen von zurückzuführen sind Es liegt jedoch eher an den Einschränkungen der beim Training verwendeten gemeinsamen Datensätze. Viele visuelle Sprachmodelle werden auf umfangreichen Bild-Text-Paardatensätzen trainiert, die begrenzte räumliche Informationen enthalten. Das Erhalten räumlich informationsreicher verkörperter Daten oder das Durchführen hochwertiger menschlicher Annotationen ist eine herausfordernde Aufgabe. Um dieses Problem zu lösen, werden Techniken zur automatischen Datengenerierung und -verbesserung vorgeschlagen. Bisherige Forschung konzentriert sich jedoch hauptsächlich auf die Erzeugung fotorealistischer Bilder mit echten semantischen Anmerkungen und ignoriert dabei den Reichtum an Objekten und 3D-Beziehungen. Zukünftige Forschungen könnten daher untersuchen, wie das Verständnis des Modells für räumliche Informationen durch automatische Generierungstechniken verbessert werden kann, beispielsweise durch die Einführung stärker verkörperter Daten oder durch die Konzentration auf die Modellierung von Objekten und 3D-Beziehungen. Dies wird dazu beitragen, die Leistung visueller Sprachmodelle beim räumlichen Denken zu verbessern und sie für reale Anwendungsszenarien besser geeignet zu machen.
Im Gegensatz dazu konzentriert sich diese Forschung auf die direkte Extraktion räumlicher Informationen mithilfe realer Daten, um die Vielfalt und Komplexität der realen 3D-Welt zu zeigen. Diese Methode basiert auf der neuesten visuellen Modellierungstechnologie und kann automatisch räumliche 3D-Anmerkungen aus 2D-Bildern generieren.
Eine Schlüsselfunktion des SpatialVLM-Systems besteht darin, umfangreiche, dicht annotierte reale Daten mithilfe von Technologien wie Objekterkennung, Tiefenschätzung, semantischer Segmentierung und Objektzentrumsbeschreibungsmodellen zu verarbeiten, um die räumlichen Denkfähigkeiten visueller Sprachmodelle zu verbessern . Das SpatialVLM-System erreicht die Ziele der Datengenerierung und des Trainings visueller Sprachmodelle, indem es von visuellen Modellen generierte Daten in ein hybrides Datenformat umwandelt, das für Beschreibung, VQA und räumliches Denken verwendet werden kann. Die Bemühungen der Forscher haben es diesem System ermöglicht, visuelle Informationen besser zu verstehen und zu verarbeiten und dadurch seine Leistung bei komplexen räumlichen Denkaufgaben zu verbessern. Dieser Ansatz hilft dabei, visuelle Sprachmodelle zu trainieren, um die Beziehung zwischen Bildern und Text besser zu verstehen und zu verarbeiten, wodurch ihre Genauigkeit und Effizienz bei verschiedenen visuellen Aufgaben verbessert wird.
Untersuchungen zeigen, dass das in diesem Artikel vorgeschlagene visuelle Sprachmodell in mehreren Bereichen zufriedenstellende Fähigkeiten aufweist. Erstens zeigt es deutliche Verbesserungen im Umgang mit qualitativen räumlichen Problemen. Zweitens ist das Modell in der Lage, selbst dann zuverlässig quantitative Schätzungen zu erstellen, wenn in den Trainingsdaten Rauschen vorhanden ist. Diese Fähigkeit stattet ihn nicht nur mit vernünftigem Wissen über die Zielgröße aus, sondern macht ihn auch nützlich bei der Bewältigung von Neuanordnungsaufgaben und der Annotation von Belohnungen im offenen Vokabular. In Kombination mit einem leistungsstarken groß angelegten Sprachmodell kann das räumliche visuelle Sprachmodell schließlich räumliche Denkketten ausführen und komplexe räumliche Denkaufgaben auf der Grundlage natürlicher Sprachschnittstellen lösen.
Um das visuelle Sprachmodell mit qualitativen und quantitativen Fähigkeiten zum räumlichen Denken auszustatten, schlugen die Forscher vor, einen großen räumlichen VQA-Datensatz zum Trainieren des visuellen Sprachmodells zu generieren. Konkret geht es darum, ein umfassendes Datengenerierungs-Framework zu entwerfen, das zunächst handelsübliche Computer-Vision-Modelle nutzt, einschließlich offener Vokabularerkennung, metrischer Tiefenschätzung, semantischer Segmentierung und zielzentrierter Beschreibungsmodelle, um zielzentrierte Hintergrundinformationen zu extrahieren, A Anschließend wird ein vorlagenbasierter Ansatz übernommen, um umfangreiche räumliche VQA-Daten mit angemessener Qualität zu generieren. In diesem Artikel verwendeten die Forscher den generierten Datensatz, um SpatialVLM zu trainieren, direkte räumliche Denkfähigkeiten zu erlernen, und kombinierten ihn dann mit dem in LLMs eingebetteten gesunden Menschenverstandsdenken auf hoher Ebene, um das räumliche Denken des Kettendenkens freizuschalten.

Räumlicher Benchmark für 2D-Bilder
Die Forscher entwickelten einen Prozess zur Generierung von VQA-Daten mit Fragen zum räumlichen Denken. Der spezifische Prozess ist in Abbildung 2 dargestellt.

1. Semantische Filterung: Im Datensyntheseprozess dieses Artikels besteht der erste Schritt darin, das CLIP-basierte Klassifizierungsmodell mit offenem Vokabular zu verwenden, um alle Bilder zu klassifizieren und ungeeignete Bilder auszuschließen.
2. 2D-Bildextraktion zielzentrierter Hintergrund: Dieser Schritt erhält zielzentrierte Entitäten, die aus Pixelclustern und offenen Vokabularbeschreibungen bestehen.
3. 2D-Hintergrundinformationen zu 3D-Hintergrundinformationen: Nach der Tiefenschätzung werden die 2D-Pixel eines einzelnen Auges zu einer 3D-Punktwolke im metrischen Maßstab aktualisiert. Dieser Artikel ist der erste, der Bilder im Internetmaßstab auf objektzentrierte 3D-Punktwolken hochskaliert und sie zur Synthese von VQA-Daten mit 3D-Rauminferenzüberwachung verwendet.
4. Begriffsklärung: Manchmal gibt es in einem Bild mehrere Objekte ähnlicher Kategorien, was zu Mehrdeutigkeiten in ihren Beschreibungsbezeichnungen führt. Bevor Sie Fragen zu diesen Zielen stellen, müssen Sie daher sicherstellen, dass der Referenzausdruck keine Mehrdeutigkeit enthält.
Großräumiger VQA-Datensatz zum räumlichen Denken
Forscher integrieren „intuitive“ Fähigkeiten zum räumlichen Denken in VLM, indem sie synthetische Daten für das Vortraining verwenden. Daher umfasst die Synthese räumliche Frage-Antwort-Paare von nicht mehr als zwei Objekten (bezeichnet mit A und B) im Bild. Dabei kommen vor allem die folgenden zwei Arten von Fragen in Betracht:
1. Qualitative Fragen: Fragen nach der Beurteilung bestimmter räumlicher Zusammenhänge. Zum Beispiel: „Gegeben seien zwei Objekte A und B, welches befindet sich weiter links?“
2. Quantitative Fragen: Bitten Sie um detailliertere Antworten, einschließlich Zahlen und Einheiten. Zum Beispiel: „Wie weit links ist Objekt A relativ zu Objekt B?“, „Wie weit ist Objekt A von B entfernt?“
Hier spezifizierten die Forscher jeweils 38 verschiedene Arten von qualitativen und quantitativen Fragen zum räumlichen Denken Die Fragen enthalten etwa 20 Fragevorlagen und 10 Antwortvorlagen.
Abbildung 3 zeigt ein Beispiel der in diesem Artikel erhaltenen synthetischen Frage-Antwort-Paare. Die Forscher erstellten einen riesigen Datensatz aus 10 Millionen Bildern und 2 Milliarden Frage-Antwort-Paaren zum direkten räumlichen Denken (50 % qualitativ, 50 % quantitativ).

Räumliches Denken lernen
Direktes räumliches Denken: Das visuelle Sprachmodell empfängt ein Bild I und eine Abfrage Q zu einer räumlichen Aufgabe als Eingabe, gibt eine Antwort A aus und wird präsentiert in einem Textformat, ohne dass externe Tools verwendet oder mit anderen großen Modellen interagiert werden müssen. Dieser Artikel übernimmt die gleiche Architektur und den gleichen Trainingsprozess wie PaLM-E, mit der Ausnahme, dass das Rückgrat von PaLM durch PaLM 2-S ersetzt wird. Anschließend wurde das Modelltraining mit einer Mischung aus dem ursprünglichen PaLM-E-Datensatz und dem Datensatz des Autors durchgeführt, wobei 5 % der Token für die räumliche Inferenzaufgabe verwendet wurden.
Verkettetes Denken, räumliches Denken: SpatialVLM bietet eine Schnittstelle in natürlicher Sprache, die zum Abfragen von Fragen mit zugrunde liegenden Konzepten verwendet werden kann und in Kombination mit dem leistungsstarken LLM komplexe räumliche Überlegungen durchführen kann.
Ähnlich den Methoden in Socratic Models und LLM-Koordinator verwendet dieser Artikel LLM (text-davinci-003), um die Kommunikation mit SpatialVLM zu koordinieren und komplexe Probleme in einer Eingabeaufforderung für Kettendenken zu lösen, wie in Abbildung 4 dargestellt.

Die Forscher haben die folgenden Fragen durch Experimente bewiesen und beantwortet:
Frage 1: Verbessert der in diesem Artikel entwickelte räumliche VQA-Datengenerierungs- und Trainingsprozess die allgemeine Leistung von? VLM? Räumliches Denkvermögen? Und wie funktioniert es?
Frage 2: Welchen Einfluss haben synthetische räumliche VQA-Daten voller verrauschter Daten und unterschiedlicher Trainingsstrategien auf die Lernleistung?
Frage 3: Kann ein VLM, das mit „direkten“ räumlichen Denkfähigkeiten ausgestattet ist, neue Fähigkeiten wie Kettendenken und verkörperte Planung freischalten?
Die Forscher trainierten das Modell mithilfe einer Mischung aus dem PaLM-E-Trainingssatz und dem in diesem Artikel entwickelten räumlichen VQA-Datensatz. Um zu überprüfen, ob die Einschränkung des VLM beim räumlichen Denken ein Datenproblem darstellt, wählten sie das aktuelle, hochmoderne visuelle Sprachmodell als Basis. Die semantische Beschreibungsaufgabe nimmt einen erheblichen Anteil im Trainingsprozess dieser Modelle ein, anstatt den räumlichen VQA-Datensatz dieses Artikels für das Training zu verwenden.
Räumliche VQA-Leistung
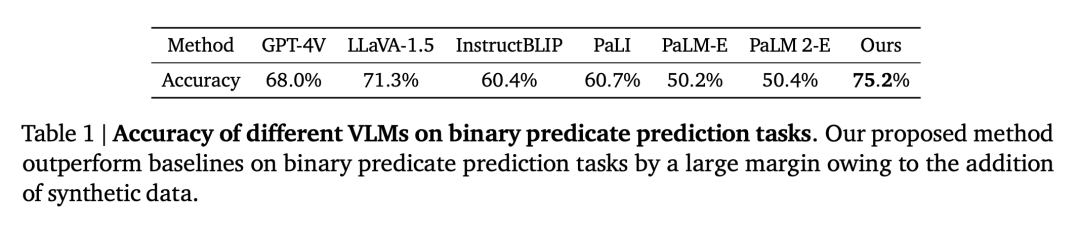
Qualitative räumliche VQA. Bei dieser Frage handelt es sich sowohl bei den von Menschen kommentierten Antworten als auch bei der VLM-Ausgabe um freie natürliche Sprache. Um die Leistung des VLM zu bewerten, haben wir daher menschliche Bewerter eingesetzt, um zu bestimmen, ob die Antworten richtig waren. Die Erfolgsraten für jedes VLM sind in Tabelle 1 aufgeführt.
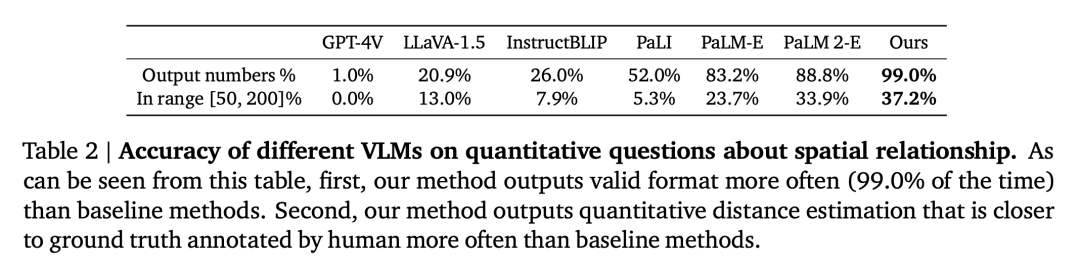
Quantitative räumliche VQA. Wie in Tabelle 2 gezeigt, schneidet unser Modell bei beiden Metriken besser ab als das Basismodell und liegt weit vorne.
Der Einfluss räumlicher VQA-Daten auf die allgemeine VQA
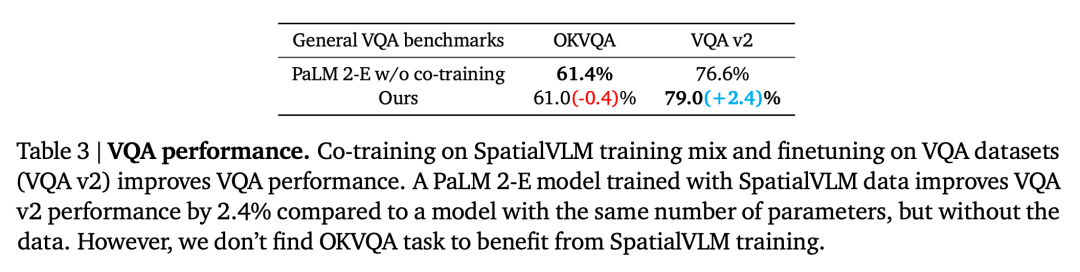
Die zweite Frage ist, ob die Leistung von VLM bei anderen Aufgaben durch das Co-Training mit einer großen Menge räumlicher VQA beeinflusst wird Daten reduzieren. Durch den Vergleich unseres Modells mit dem Basis-PaLM 2-E, das auf dem allgemeinen VQA-Benchmark trainiert wurde, ohne räumliche VQA-Daten zu verwenden, wie in Tabelle 3 zusammengefasst, erreicht unser Modell eine vergleichbare Leistung wie PaLM 2-E auf dem OKVQA-Benchmark, der begrenzte räumliche Daten umfasst Inferenzprobleme sind im VQA-v2 Test-Dev-Benchmark, der räumliche Inferenzprobleme umfasst, etwas besser.
Einfluss des ViT-Encoders auf das räumliche Denken
Kodiert Frozen ViT (trainiert auf kontrastierenden Zielen) genügend Informationen für das räumliche Denken? Um dies zu untersuchen, begannen die Experimente der Forscher bei Trainingsschritt 110.000 und wurden in zwei Trainingsläufe unterteilt, einen Frozen ViT und einen Unfrozen ViT. Durch Training beider Modelle für 70.000 Schritte sind die Bewertungsergebnisse in Tabelle 4 dargestellt.

Die Auswirkung verrauschter quantitativer räumlicher Antworten
Die Forscher verwendeten den Roboterbetriebsdatensatz, um ein visuelles Sprachmodell zu trainieren, und stellten fest, dass das Modell in der Lage war, eine feine Entfernungsschätzung durchzuführen Operationsdomäne (Abbildung 5), was die Genauigkeit der Daten weiter beweist.
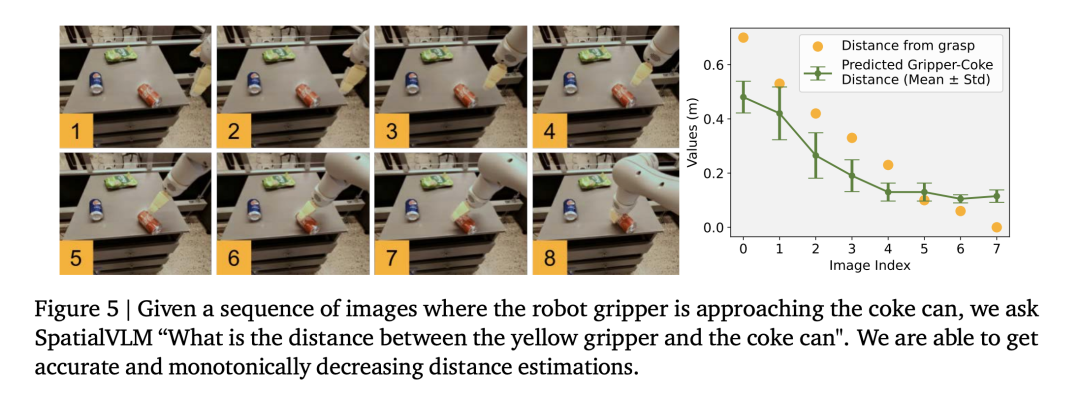
Tabelle 5 vergleicht die Auswirkungen verschiedener Standardabweichungen des Gaußschen Rauschens auf die Gesamtleistung des VLM bei der quantitativen räumlichen VQA.

1. Visuelles Sprachmodell als dichter Belohnungsannotator
Visuelle Sprachmodelle haben eine wichtige Anwendung im Bereich der Robotik. Jüngste Untersuchungen haben gezeigt, dass visuelle Sprachmodelle und große Sprachmodelle als allgemeine Belohnungsannotatoren und Erfolgsdetektoren für offene Vokabeln für Roboteraufgaben dienen können, die zur Entwicklung effektiver Kontrollstrategien verwendet werden können. Allerdings sind die Belohnungskennzeichnungsfunktionen von VLM oft durch unzureichende räumliche Wahrnehmung eingeschränkt. SpatialVLM eignet sich aufgrund seiner Fähigkeit, Entfernungen oder Abmessungen anhand von Bildern quantitativ abzuschätzen, hervorragend als Annotator für dichte Belohnungen. Die Autoren führen ein reales Robotikexperiment durch, spezifizieren eine Aufgabe in natürlicher Sprache und bitten SpatialVLM, Belohnungen für jeden Frame in der Flugbahn zu kommentieren.
Jeder Punkt in Abbildung 6 stellt den Standort eines Ziels dar und seine Farbe stellt die kommentierte Belohnung dar. Während sich der Roboter einem bestimmten Ziel nähert, nehmen die Belohnungen monoton zu, was die Fähigkeiten von SpatialVLM als Annotator für dichte Belohnungen demonstriert.

2. Verkettetes räumliches Denken
Die Forscher untersuchten auch, ob SpatialVLM zur Ausführung von Aufgaben verwendet werden kann, die mehrstufiges Denken erfordern, und zwar angesichts seiner Fähigkeit, grundlegende räumliche Probleme zu lösen Verbessern Sie Ihre Antwortfähigkeiten. Einige Beispiele zeigen die Autoren in den Abbildungen 1 und 4. Wenn das große Sprachmodell (GPT-4) mit SpatialVLM als Submodul für räumliches Denken ausgestattet ist, kann es komplexe Aufgaben des räumlichen Denkens ausführen, beispielsweise die Beantwortung der Frage, ob drei Objekte in der Umgebung ein „gleichschenkliges Dreieck“ bilden können.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonLassen Sie das visuelle Sprachmodell räumliches Denken übernehmen, und Google ist wieder neu. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 CPU auslastung
CPU auslastung
 Anhand welcher Dateitypen können Sie diese identifizieren?
Anhand welcher Dateitypen können Sie diese identifizieren?
 Was ist ein ISP-Chip?
Was ist ein ISP-Chip?
 Multifunktionsnutzung
Multifunktionsnutzung
 Es gibt mehrere Möglichkeiten, die CSS-Position zu positionieren
Es gibt mehrere Möglichkeiten, die CSS-Position zu positionieren
 Konvertierung von RGB in Hexadezimal
Konvertierung von RGB in Hexadezimal
 Wie lautet das Passwort für den Mobilfunkdienst?
Wie lautet das Passwort für den Mobilfunkdienst?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



