

 System-Tutorial
LINUX
Multiprozessprogrammierung in Linux-Systemen: Detaillierte Erläuterung der Funktion fork()
System-Tutorial
LINUX
Multiprozessprogrammierung in Linux-Systemen: Detaillierte Erläuterung der Funktion fork()
Multiprozessprogrammierung in Linux-Systemen: Detaillierte Erläuterung der Funktion fork()

Die Fork()-Funktion ist einer der am häufigsten verwendeten Systemaufrufe in Linux-Systemen. Sie wird verwendet, um einen neuen Prozess zu erstellen, der ein untergeordneter Prozess des aufrufenden Prozesses ist. Das Merkmal der Funktion fork() ist, dass sie nur einmal aufgerufen wird, aber zweimal zurückgegeben wird, jeweils im übergeordneten Prozess und im untergeordneten Prozess. Der Rückgabewert der Funktion fork () ist unterschiedlich und kann zur Unterscheidung des übergeordneten Prozesses und des untergeordneten Prozesses verwendet werden. In diesem Artikel stellen wir die Prinzipien und die Verwendung der Funktion fork() vor, einschließlich der Bedeutung des Rückgabewerts, der Eigenschaften des untergeordneten Prozesses, der Synchronisation und Kommunikation des übergeordneten und untergeordneten Prozesses usw., und geben Beispiele über deren Verwendung und Vorsichtsmaßnahmen.
1. Einführung in die Gabel
Ein Prozess, einschließlich Code, Daten und Ressourcen, die dem Prozess zugewiesen sind. Die Funktion fork() erstellt durch einen Systemaufruf einen Prozess, der nahezu identisch mit dem ursprünglichen Prozess ist, d kann auch verschiedene Dinge tun.
Nachdem ein Prozess die Funktion fork() aufruft, weist das System dem neuen Prozess zunächst Ressourcen zu, beispielsweise Speicherplatz zum Speichern von Daten und Code. Kopieren Sie dann alle Werte des ursprünglichen Prozesses in den neuen Prozess, mit Ausnahme einiger Werte, die sich von den Werten des ursprünglichen Prozesses unterscheiden. Es ist gleichbedeutend damit, sich selbst zu klonen.
Schauen wir uns ein Beispiel an:
1. /*
2. \* fork_test.c
3. \* version 1
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main ()
10. {
11. pid_t fpid; //fpid表示fork函数返回的值
12. int count=0;
13. fpid=fork();
14. if (fpid printf("error in fork!");
16. else if (fpid == 0) {
17. printf("i am the child process, my process id is %d/n",getpid());
18. printf("我是爹的儿子/n");//对某些人来说中文看着更直白。
19. count++;
20. }
21. else {
22. printf("i am the parent process, my process id is %d/n",getpid());
23. printf("我是孩子他爹/n");
24. count++;
25. }
26. printf("统计结果是: %d/n",count);
27. return 0;
28. }
Das Laufergebnis ist:
Ich bin der untergeordnete Prozess, meine Prozess-ID ist 5574
Ich bin der Sohn meines Vaters
Das statistische Ergebnis ist: 1
Ich bin der übergeordnete Prozess, meine Prozess-ID ist 5573
Ich bin der Vater des Kindes
Das statistische Ergebnis ist: 1
Vor der Anweisung fpid=fork() führt nur ein Prozess diesen Code aus, aber nach dieser Anweisung sind es zwei Prozesse, die als nächstes ausgeführt werden. Die Anweisungen sind alle if(fpid
Warum sind die fpids der beiden Prozesse unterschiedlich? Dies hängt mit den Eigenschaften der Gabelfunktion zusammen.
Eines der wunderbaren Dinge am Fork-Aufruf ist, dass er nur einmal aufgerufen wird, aber zweimal zurückgegeben werden kann. Er kann drei verschiedene Rückgabewerte haben:
1) Im übergeordneten Prozess gibt Fork die Prozess-ID des neu erstellten untergeordneten Prozesses zurück
2) Im untergeordneten Prozess gibt fork 0 zurück;
3) Wenn ein Fehler auftritt, gibt fork einen negativen Wert zurück
Nachdem die Fork-Funktion ausgeführt wurde und der neue Prozess erfolgreich erstellt wurde, werden zwei Prozesse angezeigt, einer ist der untergeordnete Prozess und der andere ist der übergeordnete Prozess. Im untergeordneten Prozess gibt die fork-Funktion 0 zurück. Im übergeordneten Prozess gibt fork die Prozess-ID des neu erstellten untergeordneten Prozesses zurück. Wir können den von fork zurückgegebenen Wert verwenden, um zu bestimmen, ob der aktuelle Prozess ein untergeordneter Prozess oder ein übergeordneter Prozess ist.
Zitat eines Internetnutzers, um zu erklären, warum der Wert von fpid in den Vater-Sohn-Prozessen unterschiedlich ist. „Tatsächlich entspricht es einer verknüpften Liste. Die Prozesse bilden eine verknüpfte Liste. Die fpid des übergeordneten Prozesses (p bedeutet Punkt) zeigt auf die Prozess-ID des untergeordneten Prozesses. Da der untergeordnete Prozess keine untergeordneten Prozesse hat, ist dies der Fall fpid ist 0,
Fork-Fehler können aus zwei Gründen auftreten:
1) Die aktuelle Anzahl der Prozesse hat die vom System festgelegte Obergrenze erreicht. Zu diesem Zeitpunkt wird der Wert von errno auf EAGAIN gesetzt.
2) Das System verfügt nicht über genügend Speicher und der Wert von errno ist auf ENOMEM gesetzt.
Nachdem der neue Prozess erfolgreich erstellt wurde, werden zwei grundsätzlich identische Prozesse im System angezeigt. Es gibt keine feste Reihenfolge, in der die beiden Prozesse ausgeführt werden. Welcher Prozess zuerst ausgeführt wird, hängt von der Prozessplanungsrichtlinie des Systems ab.
Nachdem der Fork ausgeführt wurde, erscheinen zwei Prozesse,
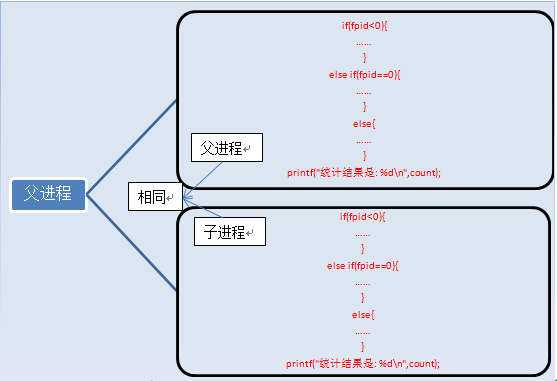
Nach der Ausführung von fork sind die Variablen von Prozess 1 count=0, fpid! =0 (übergeordneter Prozess). Die Variablen von Prozess 2 sind count=0 und fpid=0 (untergeordneter Prozess). Die Variablen dieser beiden Prozesse sind an unterschiedlichen Adressen vorhanden. Dies sollte nicht beachtet werden. Man kann sagen, dass wir fpid verwenden, um die übergeordneten und untergeordneten Prozesse zu identifizieren und zu betreiben.
Einige Leute fragen sich vielleicht, warum der Code nicht von #include kopiert wird. Dies liegt daran, dass fork die aktuelle Situation des Prozesses kopiert, wenn der Prozess int count=0;
ausgeführt wirdfork kopiert nur den nächsten auszuführenden Code in den neuen Prozess.
2. Fork fortgeschrittene KenntnisseSchauen wir uns zuerst den Code an:
1. /*
2. \* fork_test.c
3. \* version 2
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main(void)
10. {
11. int i=0;
12. printf("i son/pa ppid pid fpid/n");
13. //ppid指当前进程的父进程pid
14. //pid指当前进程的pid,
15. //fpid指fork返回给当前进程的值
16. for(i=0;iif(fpid==0)
19. printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
20. else
21. printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
22. }
23. return 0;
24. }
Das Laufergebnis ist:
i son/pa ppid pid fpid 0 parent 2043 3224 3225 0 child 3224 3225 0 1 parent 2043 3224 3226 1 parent 3224 3225 3227 1 child 1 3227 0 1 child 1 3226 0
Dieser Code ist sehr interessant, analysieren wir ihn sorgfältig:
Schritt 1: Im übergeordneten Prozess wird die Anweisung in der for-Schleife ausgeführt, i=0, und dann wird die Verzweigung ausgeführt. Nachdem die Verzweigung ausgeführt wurde, erscheinen zwei Prozesse im System, nämlich p3224 und p3225 (ich werde pxxxx verwenden). um später die Prozess-ID darzustellen) ist der Prozess von xxxx). Sie können sehen, dass der übergeordnete Prozess des übergeordneten Prozesses p3224 p2043 ist und der übergeordnete Prozess des untergeordneten Prozesses p3225 zufällig p3224 ist. Wir verwenden eine verknüpfte Liste, um diese Beziehung darzustellen:
p2043->p3224->p3225
第一次fork后,p3224(父进程)的变量为i=0,fpid=3225(fork函数在父进程中返向子进程id),代码内容为:
1. for(i=0;iif(fpid==0)
4. printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
5. else
6. printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
7. }
8. return 0;
p3225(子进程)的变量为i=0,fpid=0(fork函数在子进程中返回0),代码内容为:
1. for(i=0;iif(fpid==0)
4. printf("%d child %4d %4d %4d/n",i,getppid(),getpid(),fpid);
5. else
6. printf("%d parent %4d %4d %4d/n",i,getppid(),getpid(),fpid);
7. }
8. return 0;
所以打印出结果:
0 parent 2043 3224 3225
0 child 3224 3225 0
第二步:假设父进程p3224先执行,当进入下一个循环时,i=1,接着执行fork,系统中又新增一个进程p3226,对于此时的父进程,
p2043->p3224(当前进程)->p3226(被创建的子进程)。
对于子进程p3225,执行完第一次循环后,i=1,接着执行fork,系统中新增一个进程p3227,对于此进程,p3224->p3225(当前进程)->p3227(被创建的子进程)。
从输出可以看到p3225原来是p3224的子进程,现在变成p3227的父进程。父子是相对的,这个大家应该容易理解。只要当前进程执行了fork,该进程就变成了父进程了,就打印出了parent。
所以打印出结果是:
1 parent 2043 3224 3226
1 parent 3224 3225 3227
第三步:第二步创建了两个进程p3226,p3227,这两个进程执行完printf函数后就结束了,因为这两个进程无法进入第三次循环,无法fork,该执行return 0;了,其他进程也是如此。
以下是p3226,p3227打印出的结果:
1 child 1 3227 0
1 child 1 3226 0
细心的读者可能注意到p3226,p3227的父进程难道不该是p3224和p3225吗,怎么会是1呢?这里得讲到进程的创建和死亡的过程,在p3224和p3225执行完第二个循环后,main函数就该退出了,也即进程该死亡了,因为它已经做完所有事情了。p3224和p3225死亡后,p3226,p3227就没有父进程了,这在操作系统是不被允许的,所以p3226,p3227的父进程就被置为p1了,p1是永远不会死亡的,至于为什么,这里先不介绍,留到“三、fork高阶知识”讲。
总结一下,这个程序执行的流程如下:
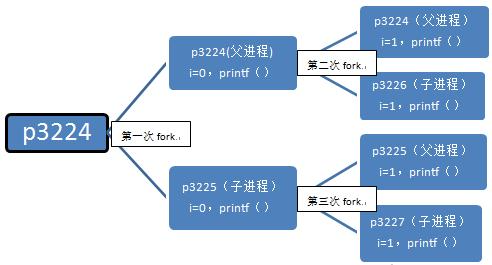
这个程序最终产生了3个子进程,执行过6次printf()函数。
我们再来看一份代码:
1. /*
2. \* fork_test.c
3. \* version 3
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main(void)
10. {
11. int i=0;
12. for(i=0;iif(fpid==0)
15. printf("son/n");
16. else
17. printf("father/n");
18. }
19. return 0;
20.
21. }
它的执行结果是:
father son father father father father son son father son son son father son
这里就不做详细解释了,只做一个大概的分析。
for i=0 1 2 father father father son son father son son father father son son father son
其中每一行分别代表一个进程的运行打印结果。
总结一下规律,对于这种N次循环的情况,执行printf函数的次数为2*(1+2+4+……+2N-1)次,创建的子进程数为1+2+4+……+2N-1个。
(感谢gao_jiawei网友指出的错误,原本我的结论是“执行printf函数的次数为2*(1+2+4+……+2N)次,创建的子进程数为1+2+4+……+2N ”,这是错的)
网上有人说N次循环产生2*(1+2+4+……+2N)个进程,这个说法是不对的,希望大家需要注意。
同时,大家如果想测一下一个程序中到底创建了几个子进程,最好的方法就是调用printf函数打印该进程的pid,也即调用printf(“%d/n”,getpid());或者通过printf(“+/n”);
来判断产生了几个进程。有人想通过调用printf(“+”);来统计创建了几个进程,这是不妥当的。具体原因我来分析。
老规矩,大家看一下下面的代码:
1. /*
2. \* fork_test.c
3. \* version 4
4. \* Created on: 2010-5-29
5. \* Author: wangth
6. */
7. \#include
8. \#include
9. int main() {
10. pid_t fpid;//fpid表示fork函数返回的值
11. //printf("fork!");
12. printf("fork!/n");
13. fpid = fork();
14. if (fpid printf("error in fork!");
16. else if (fpid == 0)
17. printf("I am the child process, my process id is %d/n", getpid());
18. else
19. printf("I am the parent process, my process id is %d/n", getpid());
20. return 0;
21. }
执行结果如下:
fork!
I am the parent process, my process id is 3361
I am the child process, my process id is 3362
如果把语句printf("fork!/n");注释掉,执行printf("fork!");
则新的程序的执行结果是:
fork!I am the parent process, my process id is 3298 fork!I am the child process, my process id is 3299
程序的唯一的区别就在于一个/n回车符号,为什么结果会相差这么大呢?
这就跟printf的缓冲机制有关了,printf某些内容时,操作系统仅仅是把该内容放到了stdout的缓冲队列里了,并没有实际的写到屏幕上。
但是,只要看到有/n 则会立即刷新stdout,因此就马上能够打印了。
运行了printf(“fork!”)后,“fork!”仅仅被放到了缓冲里,程序运行到fork时缓冲里面的“fork!” 被子进程复制过去了。因此在子进程度stdout
缓冲里面就也有了fork! 。所以,你最终看到的会是fork! 被printf了2次!!!!
而运行printf(“fork! /n”)后,“fork!”被立即打印到了屏幕上,之后fork到的子进程里的stdout缓冲里不会有fork! 内容。因此你看到的结果会是fork! 被printf了1次!!!!
所以说printf(“+”);不能正确地反应进程的数量。
大家看了这么多可能有点疲倦吧,不过我还得贴最后一份代码来进一步分析fork函数。
1. \#include
2. \#include
3. int main(int argc, char* argv[])
4. {
5. fork();
6. fork() && fork() || fork();
7. fork();
8. return 0;
9. }
问题是不算main这个进程自身,程序到底创建了多少个进程。
为了解答这个问题,我们先做一下弊,先用程序验证一下,到此有多少个进程。
1. \#include
2. int main(int argc, char* argv[])
3. {
4. fork();
5. fork() && fork() || fork();
6. fork();
7. printf("+/n");
8. }
答案是总共20个进程,除去main进程,还有19个进程。
我们再来仔细分析一下,为什么是还有19个进程。
第一个fork和最后一个fork肯定是会执行的。
主要在中间3个fork上,可以画一个图进行描述。
这里就需要注意&&和||运算符。
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
fork()对于父进程和子进程的返回值是不同的,按照上面的A&&B和A||B的分支进行画图,可以得出5个分支。
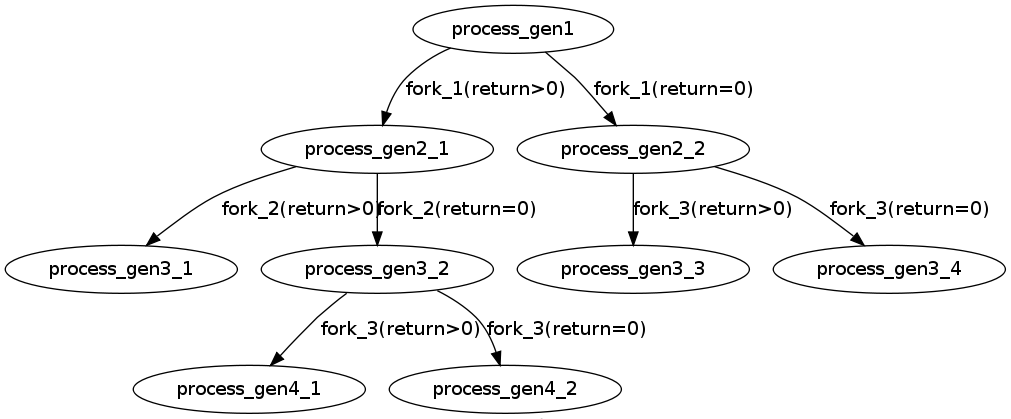
加上前面的fork和最后的fork,总共4*5=20个进程,除去main主进程,就是19个进程了。
三、fork高阶知识
<code style="display: -webkit-box;font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;border-radius: 0px;font-size: 12px">这一块我主要就fork函数讲一下操作系统进程的创建、死亡和调度等。因为时间和精力限制,我先写到这里,下次找个时间我争取把剩下的内容补齐。 </code>
通过本文,我们了解了fork()函数的原理和用法,它可以用来实现多进程编程,提高程序的并发性和效率。我们应该根据实际需求选择合适的fork()函数,并遵循一些基本原则,如检查返回值是否正确,处理僵尸进程,使用信号或管道进行同步和通信等。fork()函数是Linux系统中最强大的系统调用之一,它可以实现多种复杂的功能和特性,也可以提升程序的灵活性和可扩展性。希望本文能够对你有所帮助和启发。
Das obige ist der detaillierte Inhalt vonMultiprozessprogrammierung in Linux-Systemen: Detaillierte Erläuterung der Funktion fork(). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Linux vs Windows: Welches Betriebssystem ist besser für Sie?
Jul 29, 2025 am 03:40 AM
Linux vs Windows: Welches Betriebssystem ist besser für Sie?
Jul 29, 2025 am 03:40 AM
WindowsSbetterForBeginersDuetoeaseofuse, SeamlessHardWarecompatibilität und SupportformainStreamSoftwarelikemicrosoftOfficAndAbApps.2.LinuxoutPerformswindowSonolderorlow-Resourcehardwarewithfasterboottimes, LowersyStemRequeStemeStemRequirements und LowsSystems und LesslosedleSble
 Wie installiere ich Software unter Linux mit dem Terminal?
Aug 02, 2025 pm 12:58 PM
Wie installiere ich Software unter Linux mit dem Terminal?
Aug 02, 2025 pm 12:58 PM
Es gibt drei Hauptmethoden, um Software unter Linux zu installieren: 1. Verwenden Sie einen Paketmanager wie APT, DNF oder Pacman und führen dann den Installationsbefehl aus, nachdem die Quelle aktualisiert wurde, wie z. B. sudoaptininstallcurl; 2. Verwenden Sie für .deb- oder .rpm -Dateien DPKG- oder RPM -Befehle, um Abhängigkeiten bei Bedarf zu installieren und zu reparieren. 3.. Verwenden Sie Snap oder Flatpak, um Anwendungen über Plattformen hinweg zu installieren, z. Es wird empfohlen, den eigenen Paketmanager des Systems für eine bessere Kompatibilität und Leistung zu verwenden.
 So planen Sie Aufgaben unter Linux mit Cron und Anacron
Aug 01, 2025 am 06:11 AM
So planen Sie Aufgaben unter Linux mit Cron und Anacron
Aug 01, 2025 am 06:11 AM
cronisusedForprecisesDulingonalways-Einsysteme, whileanaconeSureSureStoctasKsRunonSystemthataren'tcontinuouslyPowered, Suchaslaptops; 1.USecronforexacttiming (z
 Die ultimative Anleitung für Hochleistungsspiele unter Linux
Aug 03, 2025 am 05:51 AM
Die ultimative Anleitung für Hochleistungsspiele unter Linux
Aug 03, 2025 am 05:51 AM
CHOOSEPOP! _OS, Ubuntu, Nobaralinux, OrarchlinuxforoptimalgamingPerformancewithminimaloverhead.2.installofficialnvidiaproprietaryDreversFornvidiagpus, sicherstellen, dass die Datemesa-Kernelversionen-Lattel-Latzen-Latzen-LATTETEPUSTEPUSTEPUSTEPUSCOWEPERSCHUWS
 Was sind die wichtigsten Vor- und Nachteile von Linux vs. Windows?
Aug 03, 2025 am 02:56 AM
Was sind die wichtigsten Vor- und Nachteile von Linux vs. Windows?
Aug 03, 2025 am 02:56 AM
Linux ist für alte Hardware geeignet, verfügt über eine hohe Sicherheit und ist anpassbar, hat jedoch eine schwache Softwarekompatibilität. Windows -Software ist reich und einfach zu bedienen, verfügt jedoch über eine hohe Ressourcenauslastung. 1. In Bezug auf die Leistung ist Linux leicht und effizient und für alte Geräte geeignet. Windows hat hohe Hardwareanforderungen. 2. In Bezug auf die Software hat Windows eine größere Kompatibilität, insbesondere professionelle Tools und Spiele. Linux muss Tools verwenden, um Software auszuführen. 3. In Bezug auf die Sicherheit ist das Linux -Berechtigungsmanagement strenger und Aktualisierungen sind bequem. Obwohl Windows geschützt ist, ist es immer noch anfällig für Angriffe. 4. In Bezug auf die Nutzungsschwierigkeit ist die Linux -Lernkurve steil; Der Windows -Betrieb ist intuitiv. Wählen Sie gemäß den Anforderungen: Wählen Sie Linux mit Leistung und Sicherheit aus und wählen Sie Windows mit Kompatibilität und Benutzerfreundlichkeit aus.
 Die Bedeutung der Zeitsynchronisation unter Linux mit NTP
Aug 01, 2025 am 06:00 AM
Die Bedeutung der Zeitsynchronisation unter Linux mit NTP
Aug 01, 2025 am 06:00 AM
TimesynchronizationiscrucialForSystemRecurity und SecurityBecauseConsistentTimeCaussLogConfusion, Sicherheitsfailuren, fehlgeschlagene Scheduledtasks und aufgehobene SystemeStemErrors;
 Einrichten eines Git -Servers auf einem Linux -Computer
Jul 28, 2025 am 02:47 AM
Einrichten eines Git -Servers auf einem Linux -Computer
Jul 28, 2025 am 02:47 AM
Installieren Sie GIT: Installieren Sie Git über den Paketmanager auf dem Server und überprüfen Sie die Version. 2. Erstellen Sie einen dedizierten Git -Benutzer: Verwenden Sie AddUser, um einen Git -Benutzer zu erstellen und optional seinen Shell -Zugriff einzuschränken. 3. Konfigurieren Sie den Entwickler SSH Access: Stellen Sie das Verzeichnis .ssh und autorized_keys für Git -Benutzer fest und fügen Sie den öffentlichen Schlüssel des Entwicklers hinzu. V. 5. Client -Klonen und Push: Entwickler klonieren das Repository durch SSH, reichen Sie Änderungen ein und drücken Sie den Code erfolgreich, um die Konstruktion eines privaten Git -Servers abzuschließen.
 Verständnis der RAID -Konfigurationen auf einem Linux -Server
Aug 05, 2025 am 11:50 AM
Verständnis der RAID -Konfigurationen auf einem Linux -Server
Aug 05, 2025 am 11:50 AM
RaidimProvessTorageperformanceCanDrelabilityonLinuxServersThroughVariousConfigurations; raid0OffersspeedButNoredundantanz; raid1providesMirrororingforcriticalDatawith50 ° C.
