


Eine der größten Herausforderungen bei der Simulation heutiger Quantencomputergeräte ist die Fähigkeit, die komplexen Zusammenhänge zwischen Qubits zu lernen und zu kodieren. Neue Technologien, die auf Sprachmodellen für maschinelles Lernen basieren, haben die einzigartige Fähigkeit bewiesen, Quantenzustände zu lernen.
Kürzlich haben Forscher der University of Waterloo in „Nature Computational Science“ einen perspektivischen Artikel mit dem Titel „Sprachmodelle für die Quantensimulation“ veröffentlicht, in dem sie den wichtigen Beitrag von Sprachmodellen beim Aufbau von Quantencomputern hervorheben und ihre mögliche Rolle in der Zukunft diskutieren Wettbewerb um die Quantenüberlegenheit. Dieser Artikel hebt den einzigartigen Wert von Sprachmodellen im Bereich des Quantencomputings hervor und weist darauf hin, dass sie zur Bewältigung der Komplexität und Genauigkeit von Quantensystemen verwendet werden können. Forscher glauben, dass durch den Einsatz von Sprachmodellen die Leistung von Quantenalgorithmen besser verstanden und optimiert werden kann und neue Ideen für die Entwicklung von Quantencomputern geliefert werden können. Der Artikel betont auch die potenzielle Rolle von Sprachmodellen im Wettbewerb um Quantenvorteile und glaubt, dass sie dazu beitragen können, die Entwicklung von Quantencomputern zu beschleunigen, und dass erwartet wird, dass sie Ergebnisse bei der Lösung praktischer Probleme erzielen

Link zum Papier: https: //www.nature.com/articles/s43588-023-00578-0
Quantencomputer haben begonnen zu reifen, und viele neuere Geräte behaupten, Quantenüberlegenheit zu haben. Die kontinuierliche Weiterentwicklung klassischer Rechenfähigkeiten, wie etwa der rasante Aufstieg maschineller Lerntechniken, hat zu vielen spannenden Szenarien rund um das Zusammenspiel von Quanten- und klassischen Strategien geführt. Da maschinelles Lernen weiterhin rasch in den Quantencomputing-Stack integriert wird, stellt sich die Frage: Könnte es die Quantentechnologie in Zukunft auf wirkungsvolle Weise verändern?
Eine der größten Herausforderungen für Quantencomputer ist derzeit das Erlernen von Quantenzuständen. Kürzlich entwickelte generative Modelle bieten zwei gängige Strategien zur Lösung des Problems des Lernens von Quantenzuständen.

Illustration: Generative Modelle für natürliche Sprache und andere Bereiche. (Quelle: Papier)
Erstens können herkömmliche Maximum-Likelihood-Methoden eingesetzt werden, indem datengesteuertes Lernen unter Verwendung eines Datensatzes durchgeführt wird, der die Ausgabe eines Quantencomputers darstellt. Zweitens können wir einen physikalischen Ansatz für Quantenzustände verwenden, der das Wissen über Wechselwirkungen zwischen Qubits nutzt, um Ersatzverlustfunktionen zu definieren.
In beiden Fällen führt eine Erhöhung der Anzahl der Qubits N dazu, dass die Größe des Quantenzustandsraums (Hilbert-Raum) exponentiell wächst, was als Fluch der Dimensionalität bezeichnet wird. Daher gibt es große Herausforderungen hinsichtlich der Anzahl der Parameter, die zur Darstellung von Quantenzuständen in erweiterten Modellen erforderlich sind, und hinsichtlich der Recheneffizienz bei der Suche nach optimalen Parameterwerten. Um dieses Problem zu lösen, sind Modelle zur Erzeugung künstlicher neuronaler Netze eine sehr geeignete Lösung.
Sprachmodelle sind ein besonders vielversprechendes generatives Modell, das sich zu einer leistungsstarken Architektur zur Lösung hochkomplexer Sprachprobleme entwickelt hat. Aufgrund seiner Skalierbarkeit eignet es sich auch für Probleme im Quantencomputing. Da sich industrielle Sprachmodelle nun in den Billionen-Parameterbereich bewegen, stellt sich natürlich die Frage, was ähnliche Großmodelle in der Physik leisten können, sei es in Anwendungen wie dem erweiterten Quantencomputing oder in Quantenmaterie, Materialien und grundlegendem theoretischen Verständnis Ausrüstung.
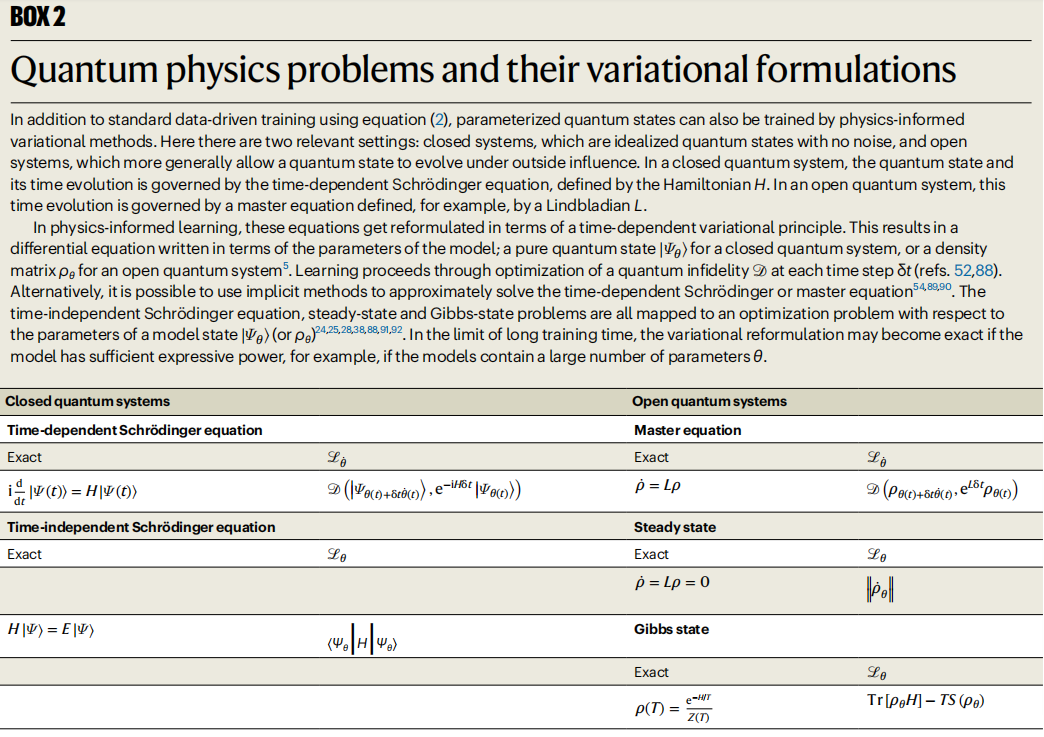
Illustration: Probleme der Quantenphysik und ihre Variationsformeln. (Quelle: Papier)
Sprachmodelle sind generative Modelle, die darauf ausgelegt sind, Wahrscheinlichkeitsverteilungen aus Daten natürlicher Sprache abzuleiten.
Die Aufgabe des generativen Modells besteht darin, probabilistische Beziehungen zwischen im Korpus vorkommenden Wörtern zu lernen und so die Generierung neuer Phrasen Token für Token zu ermöglichen. Die Hauptschwierigkeit besteht darin, alle komplexen Abhängigkeiten zwischen Wörtern zu modellieren.
Ähnliche Herausforderungen gelten auch für Quantencomputer, wo nicht-lokale Korrelationen wie Verschränkung zu höchst nicht-trivialen Abhängigkeiten zwischen Qubits führen. Eine interessante Frage ist daher, ob die in der Industrie entwickelten leistungsstarken autoregressiven Architekturen auch zur Lösung von Problemen in stark korrelierten Quantensystemen eingesetzt werden können.
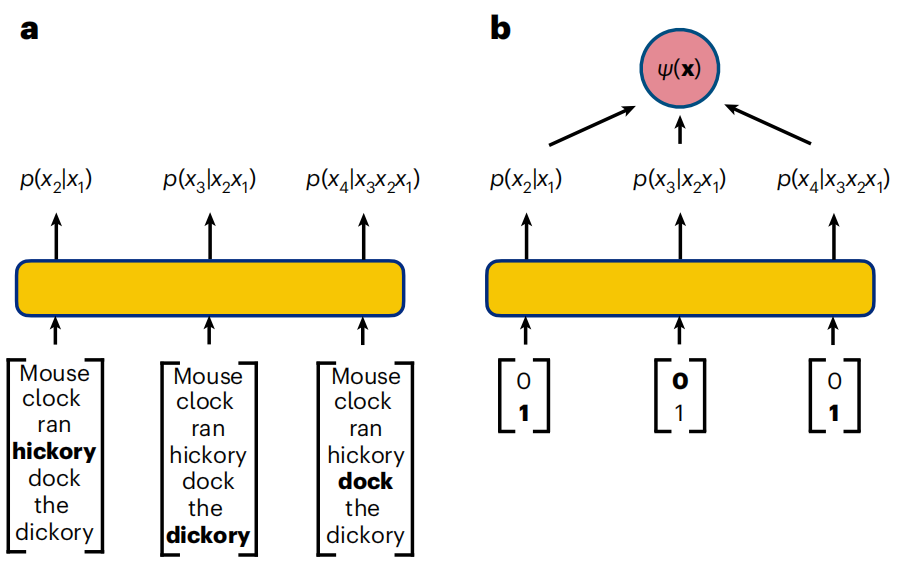
Illustration: Autoregressive Strategien für Text- und Qubit-Sequenzen. (Quelle: Paper)
RNN ist jedes neuronale Netzwerk, das wiederkehrende Verbindungen enthält, sodass die Ausgabe einer RNN-Einheit von der vorherigen Ausgabe abhängt. Seit 2018 hat sich der Einsatz von RNNs rasch ausgeweitet und deckt eine Vielzahl der anspruchsvollsten Aufgaben beim Verständnis von Quantensystemen ab.
Ein wesentlicher Vorteil von RNNs, die für diese Aufgaben geeignet sind, ist ihre Fähigkeit, hochsignifikante Korrelationen zwischen Qubits zu lernen und zu kodieren, einschließlich intrinsisch nicht-lokaler Quantenverschränkung.
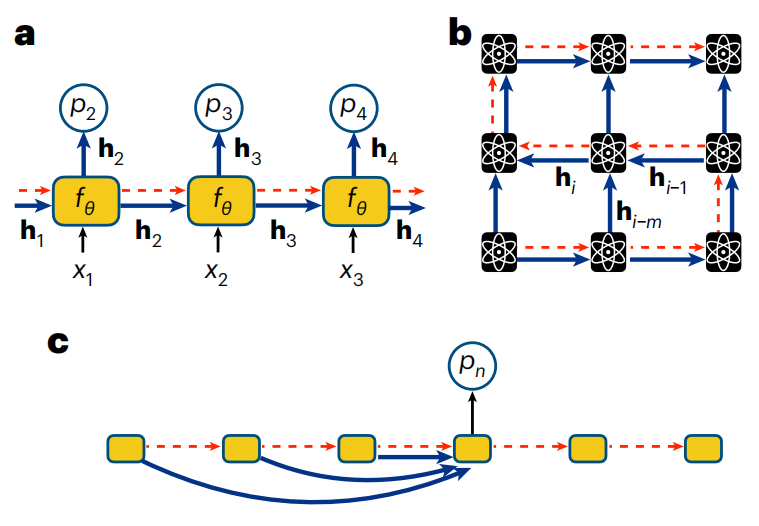
Abbildung: RNN für Qubit-Sequenz. (Quelle: Papier)
Physiker haben RNNs für eine Vielzahl innovativer Anwendungen im Zusammenhang mit Quantencomputern verwendet. RNNs wurden für die Rekonstruktion von Quantenzuständen aus Qubit-Messungen verwendet. RNNs können auch zur Simulation der Dynamik von Quantensystemen verwendet werden, was als eine der vielversprechendsten Anwendungen des Quantencomputings und daher als Schlüsselaufgabe bei der Definition von Quantenvorteilen gilt. RNNs wurden als Strategie zum Aufbau neuronaler fehlerkorrigierender Decoder verwendet, einem Schlüsselelement bei der Entwicklung fehlertoleranter Quantencomputer. Darüber hinaus sind RNNs in der Lage, datengesteuerte und physikalisch inspirierte Optimierungen zu nutzen, was eine zunehmende Anzahl innovativer Anwendungen in Quantensimulationen ermöglicht.
Die Physiker-Gemeinschaft entwickelt RNNs weiterhin aktiv weiter und hofft, sie zur Bewältigung der immer komplexer werdenden Rechenaufgaben im Zeitalter des Quantenvorteils nutzen zu können. Die rechnerische Konkurrenzfähigkeit von RNNs mit Tensornetzwerken bei vielen Quantenaufgaben, gepaart mit ihrer natürlichen Fähigkeit, den Wert von Qubit-Messdaten zu nutzen, legt nahe, dass RNNs auch in Zukunft eine wichtige Rolle bei der Simulation komplexer Aufgaben auf Quantencomputern spielen werden.
Während RNNs im Laufe der Jahre große Erfolge bei Aufgaben in natürlicher Sprache erzielt haben, wurden sie in der Industrie kürzlich durch den Selbstaufmerksamkeitsmechanismus von Transformer, einem der heutigen großen Sprachmodelle (LLM), in den Schatten gestellt. Eine Schlüsselkomponente der Encoder-Decoder-Architektur.
Skalierung Der Erfolg von Transformern und die wichtigen Fragen, die durch die nicht-trivialen Emergenzphänomene, die sie in Sprachaufgaben zeigen, aufgeworfen werden, faszinieren seit langem Physiker, für die das Erreichen der Skalierung ein Hauptschwerpunkt der Quantencomputerforschung ist.
Im Wesentlichen ist Transformer ein einfaches autoregressives Modell. Im Gegensatz zu RNNs, die Korrelationen implizit durch versteckte Vektoren kodieren, hängt die von einem Transformer-Modell ausgegebene bedingte Verteilung jedoch explizit von allen anderen Variablen in der Sequenz hinsichtlich autoregressiver Eigenschaften ab. Dies wird durch den Selbstaufmerksamkeitsmechanismus der kausalen Abschirmung erreicht.
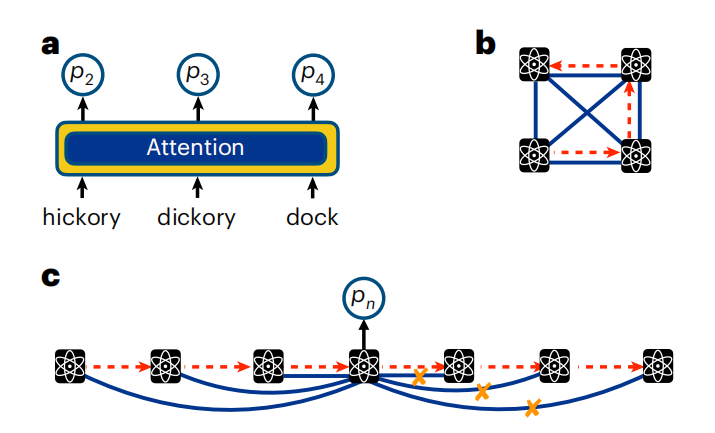
Abbildung: Beachten Sie den Text und die Qubit-Sequenz. (Quelle: Paper)
Wie bei Sprachdaten wird die Aufmerksamkeit in Quantensystemen berechnet, indem Qubit-Messungen vorgenommen und diese durch eine Reihe parametrisierter Funktionen transformiert werden. Durch das Training einer Reihe dieser parametrisierten Funktionen kann der Transformer die Abhängigkeiten zwischen Qubits lernen. Beim Aufmerksamkeitsmechanismus besteht keine Notwendigkeit, die Geometrie der übermittelten verborgenen Zustände (wie in RNNs) mit der physikalischen Anordnung der Qubits in Beziehung zu setzen.
Durch die Nutzung dieser Architektur können Transformer mit Milliarden oder Billionen Parametern trainiert werden.
Hybride zweistufige Optimierung, die datengesteuertes und physikalisch inspiriertes Lernen kombiniert, ist für die aktuelle Generation von Quantencomputern sehr wichtig. Transformer ist nachweislich in der Lage, Fehler zu mildern, die in den heutigen unvollständigen Ausgabedaten auftreten und entstehen können leistungsstarkes Fehlerprotokoll, um die Entwicklung wirklich fehlertoleranter Hardware in der Zukunft zu unterstützen.
Da der Umfang der Forschung im Bereich der Quantenphysik-Transformatoren immer schneller zunimmt, bleiben eine Reihe interessanter Fragen offen.
Obwohl Physiker sie erst seit kurzer Zeit erforschen, haben Sprachmodelle bemerkenswerte Erfolge erzielt, wenn sie auf eine Vielzahl von Herausforderungen im Quantencomputing angewendet werden. Diese Ergebnisse weisen auf viele vielversprechende zukünftige Forschungsrichtungen hin.
Ein weiterer wichtiger Anwendungsfall für Sprachmodelle in der Quantenphysik ergibt sich aus ihrer Fähigkeit zur Optimierung, nicht durch Daten, sondern durch die Kenntnis der grundlegenden Qubit-Wechselwirkungen des Hamilton- oder Lindbladian-Operators.
Schließlich eröffnen Sprachmodelle durch die Kombination von datengesteuerter und variantengesteuerter Optimierung neue Bereiche des Hybridtrainings. Diese neuen Strategien bieten neue Möglichkeiten zur Fehlerreduzierung und zeigen starke Verbesserungen bei Variationssimulationen. Da generative Modelle kürzlich in Quantenfehler-korrigierende Decoder übernommen wurden, könnte Hybridtraining ein wichtiger Schritt auf dem Weg zum zukünftigen Heiligen Gral fehlertoleranter Quantencomputer sein. Dies deutet darauf hin, dass ein positiver Kreislauf zwischen Quantencomputern und auf deren Ergebnisse trainierten Sprachmodellen entsteht.
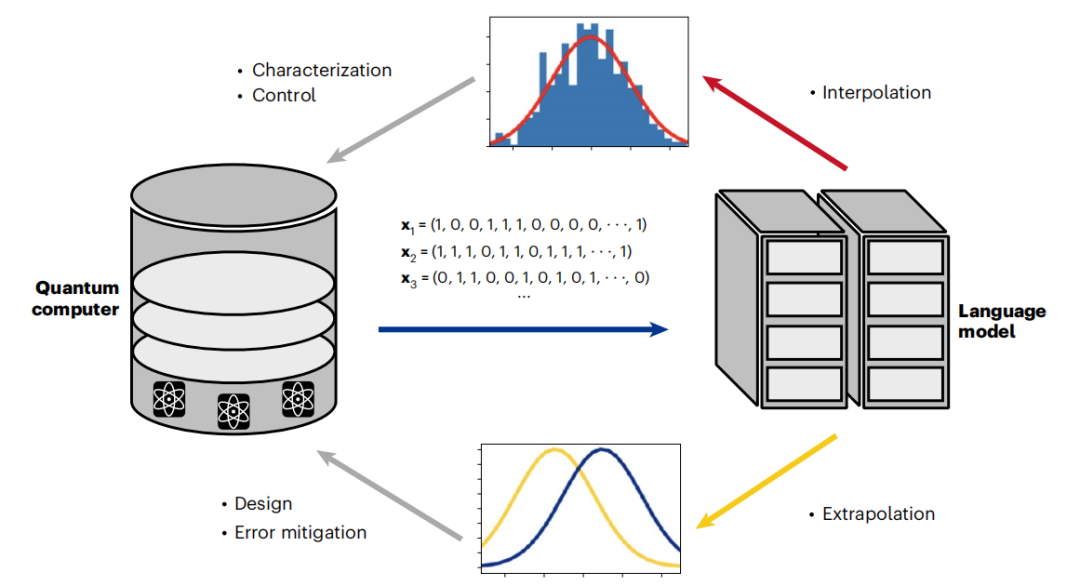
Abbildung: Das Sprachmodell erreicht die Erweiterung des Quantencomputings durch einen positiven Zyklus. (Quelle: Papier)
Mit Blick auf die Zukunft liegen die aufregendsten Möglichkeiten, den Bereich der Sprachmodelle mit Quantencomputing zu verbinden, in ihrer Fähigkeit, Maßstab und Emergenz zu demonstrieren.
Heutzutage wurde mit der Demonstration neuer Eigenschaften von LLM ein neues Feld erschlossen, das viele zwingende Fragen aufwirft. Kann LLM bei ausreichenden Trainingsdaten eine digitale Kopie eines Quantencomputers erlernen? Wie wird sich die Einbeziehung von Sprachmodellen in den Kontrollstapel auf die Charakterisierung und das Design von Quantencomputern auswirken? Wenn der Maßstab groß genug ist, kann LLM dann die Entstehung makroskopischer Quantenphänomene wie der Supraleitung zeigen?
Während Theoretiker über diese Fragen nachdenken, haben Experimental- und Computerphysiker begonnen, Sprachmodelle ernsthaft auf den Entwurf, die Charakterisierung und die Steuerung heutiger Quantencomputer anzuwenden. Wenn wir die Schwelle des Quantenvorteils überschreiten, betreten wir auch Neuland bei erweiterten Sprachmodellen. Während es schwierig ist, vorherzusagen, wie sich die Kollision von Quantencomputern und LLM entwickeln wird, ist klar, dass grundlegende Veränderungen, die durch das Zusammenspiel dieser Technologien hervorgerufen werden, bereits begonnen haben.
Das obige ist der detaillierte Inhalt vonIn der Unterzeitschrift „Nature' veröffentlicht, kommentiert das Team der University of Waterloo die Gegenwart und Zukunft von „Quantencomputern + großen Sprachmodellen'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Permutations- und Kombinationsformeln
Häufig verwendete Permutations- und Kombinationsformeln
 So lösen Sie das Problem, dass die Festplattenpartition nicht geöffnet werden kann
So lösen Sie das Problem, dass die Festplattenpartition nicht geöffnet werden kann
 So installieren Sie den Treiber
So installieren Sie den Treiber
 Das heißt, die Verknüpfung kann nicht gelöscht werden
Das heißt, die Verknüpfung kann nicht gelöscht werden
 So kaufen Sie Bitcoin
So kaufen Sie Bitcoin
 So verwenden Sie die Countif-Funktion
So verwenden Sie die Countif-Funktion
 locallapstore
locallapstore
 So stellen Sie vlanid ein
So stellen Sie vlanid ein








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



