


Im Dezember letzten Jahres veröffentlichten zwei Forscher von CMU und Princeton die Mamba-Architektur, was die KI-Community sofort schockierte!
Infolgedessen wurde heute bekannt, dass dieses Papier, von dem erwartet wird, dass es „die Hegemonie von Transformer untergräbt“, im Verdacht steht, abgelehnt zu werden? !
Heute Morgen entdeckte Sasha Rush, außerordentliche Professorin an der Cornell University, zum ersten Mal, dass dieses Papier, das voraussichtlich zu einer Grundlagenarbeit werden soll, vom ICLR 2024 abgelehnt zu werden scheint.
und sagte: „Um ehrlich zu sein, ich verstehe es nicht. Wenn es abgelehnt wird, welche Chance haben wir dann?“
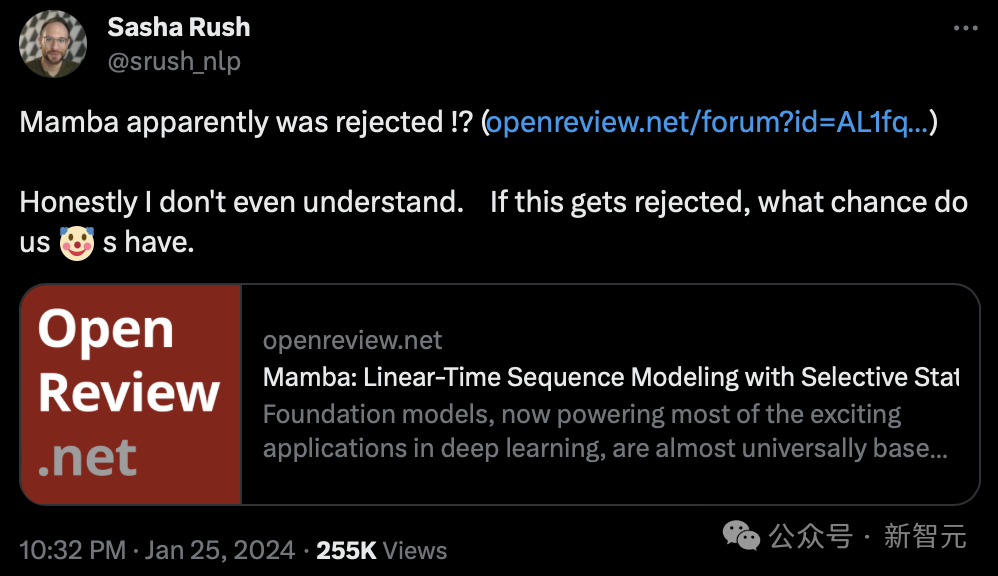
Wie Sie auf OpenReview sehen können, lauten die von den vier Rezensenten vergebenen Bewertungen 3, 6, 8 und 8.
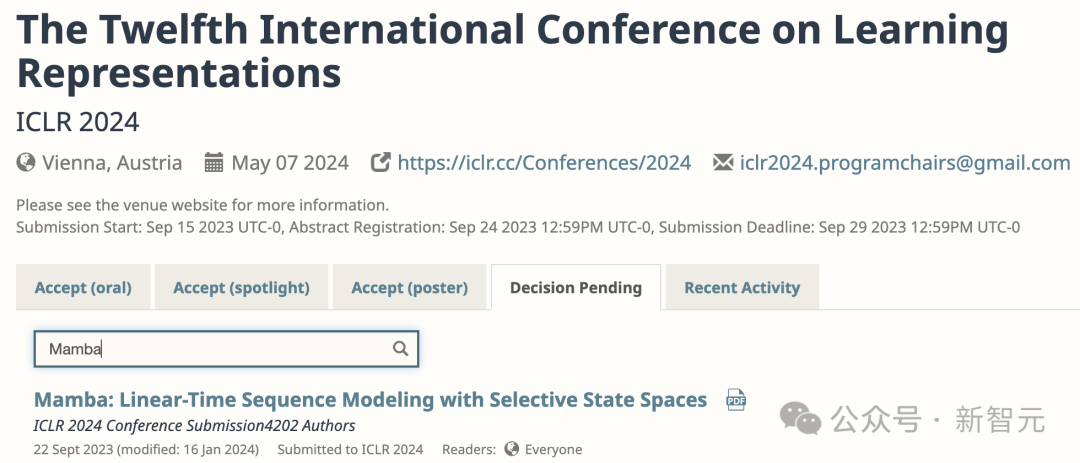
Obwohl diese Punktzahl nicht unbedingt zur Ablehnung der Arbeit führt, ist eine Punktzahl von nur 3 Punkten ebenfalls unverschämt.
Dieses von zwei Forschern der CMU und der Princeton University veröffentlichte Papier schlägt eine neue Architektur-Mamba vor.
Diese SSM-Architektur ist vergleichbar mit Transformers in der Sprachmodellierung und kann auch linear skaliert werden, wobei der Inferenzdurchsatz fünfmal höher ist!

Papieradresse: https://arxiv.org/pdf/2312.00752.pdf
Sobald das Papier herauskam, schockierte es die KI-Community direkt Dieser umgestürzte Transformer war endlich geboren.
Nun wird Mambas Beitrag wahrscheinlich abgelehnt, was viele Menschen nicht verstehen können.
Sogar Turing-Riese LeCun beteiligte sich an dieser Diskussion und sagte, er sei auf ähnliche „Ungerechtigkeit“ gestoßen.
„Ich glaube, damals hatte ich die meisten Zitate. Allein die Beiträge, die ich auf Arxiv eingereicht habe, wurden mehr als 1880 Mal zitiert, aber nie akzeptiert.“
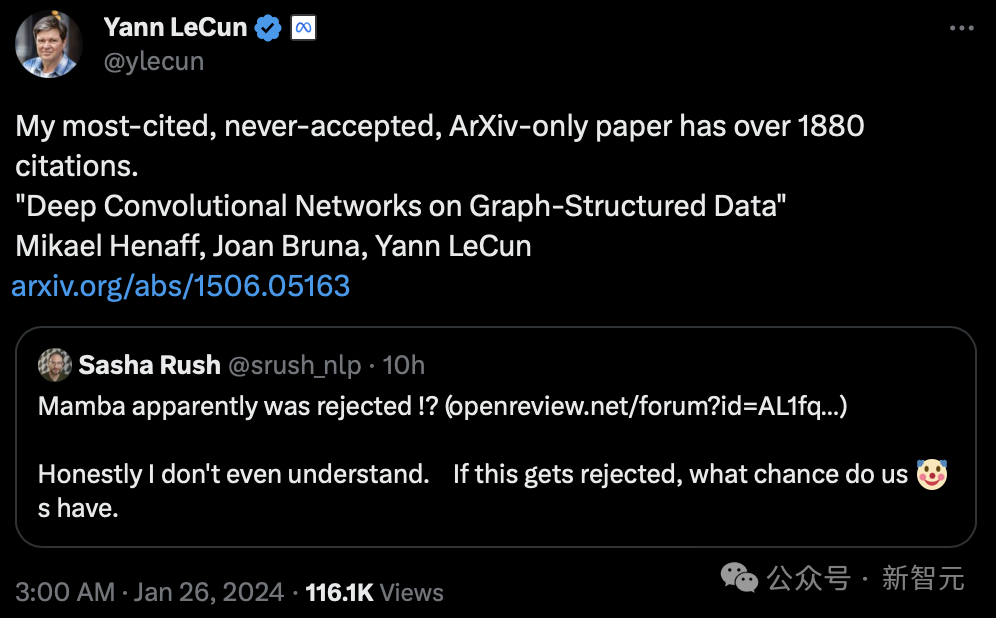
LeCun ist berühmt für seine Arbeit in den Bereichen optische Zeichenerkennung und Computer Vision unter Verwendung von Convolutional Neural Networks (CNN), für die er 2019 den Turing Award gewann.
Allerdings wurde sein 2015 veröffentlichter Artikel „Deep Convolutional Network Based on Graph Structure Data“ nie von der Konferenz angenommen.

Papieradresse: https://arxiv.org/pdf/1506.05163.pdf
Deep-Learning-KI-Forscher Sebastian Raschka sagte, dass Mamba trotzdem einen tiefgreifenden Einfluss auf die KI-Community hatte .
Eine große Forschungswelle hat sich in letzter Zeit von der Mamba-Architektur abgeleitet, beispielsweise MoE-Mamba und Vision Mamba.

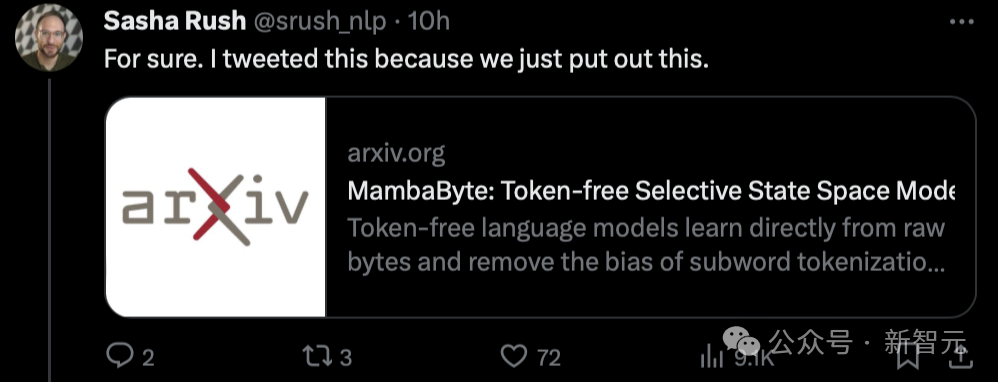
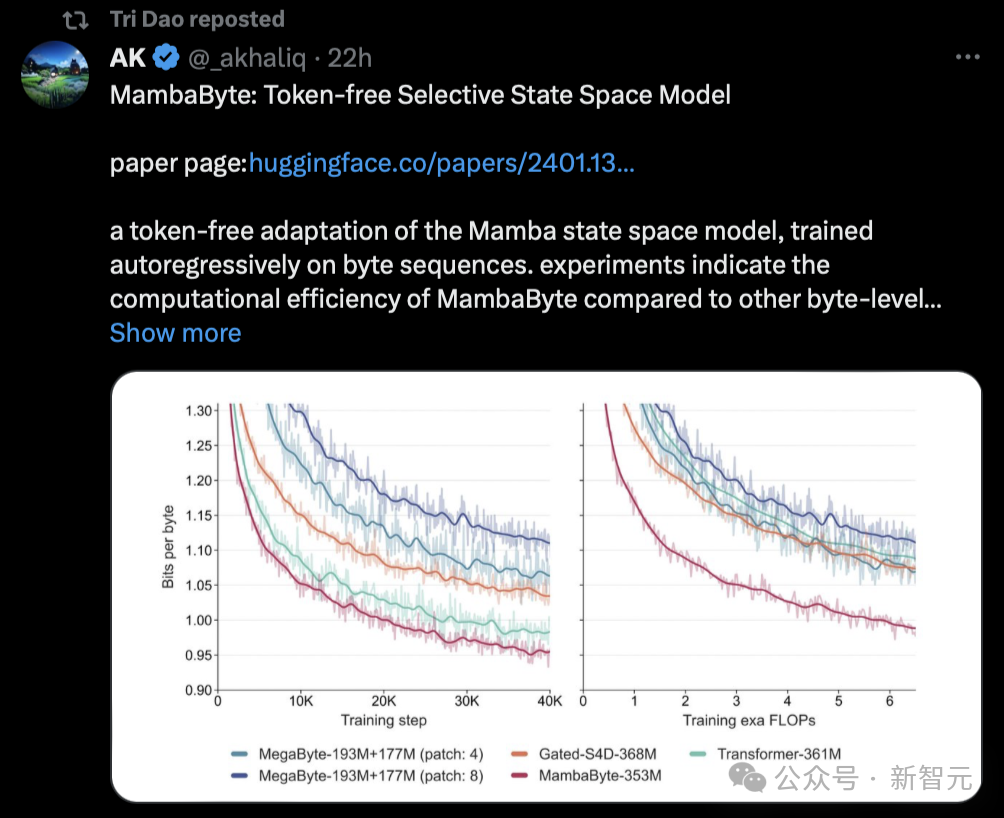
Interessanterweise veröffentlichte Sasha Rush, die die Nachricht verbreitete, dass Mamba eine niedrige Punktzahl erhalten hatte, heute auch einen neuen Artikel, der auf solchen Untersuchungen basiert – MambaByte.

Tatsächlich hat die Mamba-Architektur bereits den Status „Ein einziger Funke kann ein Präriefeuer entfachen“ erreicht und ihr Einfluss im akademischen Kreis wird immer größer.
Einige Internetnutzer sagten, dass Mamba-Zeitungen anfangen werden, arXiv zu besetzen.
„Ich habe zum Beispiel gerade dieses Papier gesehen, in dem MambaByte vorgeschlagen wird, ein tokenloses selektives Zustandsraummodell. Im Grunde passt es Mamba SSM an, um direkt von den Original-Tokens zu lernen.“ Auch Mamba Papers hat diese Recherche heute weitergeleitet.

Einem so beliebten Artikel wurde eine niedrige Bewertung gegeben. Einige Leute sagten, dass es den Anschein hat, dass Peer-Rezensenten dem Marketing wirklich keine Aufmerksamkeit schenken.
Der Grund, warum Mambas Arbeit eine Punktzahl von 3 erhielt
 Was ist der Grund dafür, dass Mambas Arbeit eine niedrige Punktzahl erhält?
Was ist der Grund dafür, dass Mambas Arbeit eine niedrige Punktzahl erhält?
In der Rezension sind die von ihm aufgeworfenen Fragen in zwei Teile gegliedert: Der eine stellt das Modelldesign in Frage, der andere das Experiment.

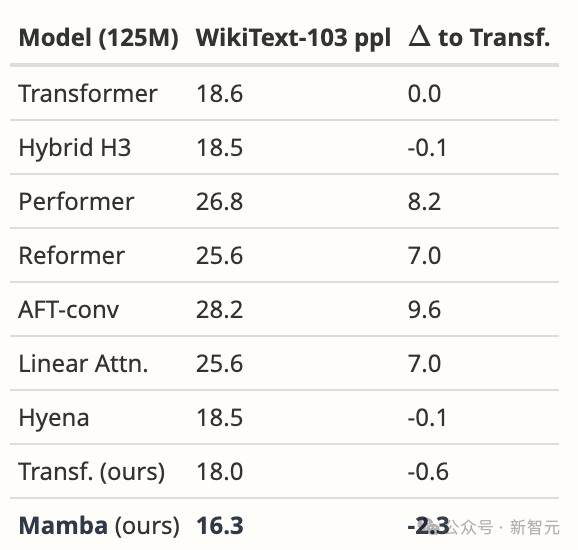
- Die Designmotivation von Mamba besteht darin, die Mängel des Schleifenmodells zu beheben und gleichzeitig die Effizienz des Transformer-basierten Modells zu verbessern. Es gibt viele Studien in diese Richtung: S4-diagonal [1], SGConv [2], MEGA [3], SPADE [4] und viele effiziente Transformer-Modelle (wie z. B. [5]). Diese Modelle erreichen alle eine nahezu lineare Komplexität, und die Autoren müssen Mamba hinsichtlich der Modellleistung und -effizienz mit diesen Werken vergleichen. Bezüglich der Modellleistung reichen einige einfache Experimente (z. B. Sprachmodellierung auf Wikitext-103) aus. - Viele aufmerksamkeitsbasierte Transformer-Modelle weisen die Fähigkeit zur Längenverallgemeinerung auf, d. h. das Modell kann auf kürzere Sequenzlängen trainiert und dann auf längere Sequenzlängen getestet werden. Einige Beispiele umfassen relative Positionskodierung (T5) und Alibi [6]. Verfügt Mamba über diese Fähigkeit zur Längenverallgemeinerung, da SSM im Allgemeinen kontinuierlich ist?
Experiment

– Die Autoren müssen mit stärkeren Basislinien vergleichen. Die Autoren erkennen an, dass H3 als Motivation für die Modellarchitektur verwendet wurde. Allerdings konnten sie experimentell nicht mit H3 verglichen werden. Wie aus Tabelle 4 von [7] ersichtlich ist, beträgt der ppl von H3 im Pile-Datensatz 8,8 (125 Mio.), 7,1 (355 Mio.) bzw. 6,0 (1,3 B), was deutlich besser ist als der von Mamba. Autoren müssen einen Vergleich mit H3 zeigen. - Für das vorab trainierte Modell zeigt der Autor nur die Ergebnisse der Zero-Shot-Inferenz. Dieses Setup ist recht begrenzt und die Ergebnisse belegen die Wirksamkeit von Mamba nicht ausreichend. Ich empfehle den Autoren, mehr Experimente mit langen Sequenzen durchzuführen, beispielsweise mit der Zusammenfassung von Dokumenten, bei denen die Eingabesequenzen natürlich sehr lang sind (z. B. ist die durchschnittliche Sequenzlänge des arXiv-Datensatzes größer als 8 KB).
- Der Autor behauptet, dass einer seiner Hauptbeiträge die Modellierung langer Sequenzen ist. Die Autoren sollten mit mehr Basislinien auf LRA (Long Range Arena) vergleichen, was im Grunde der Standardmaßstab für das Verständnis langer Sequenzen ist.
– Fehlender Speicher-Benchmark. Obwohl Abschnitt 4.5 den Titel „Geschwindigkeits- und Speicher-Benchmarks“ trägt, behandelt er nur Geschwindigkeitsvergleiche. Darüber hinaus sollte der Autor auf der linken Seite von Abbildung 8 detailliertere Einstellungen bereitstellen, z. B. Modellebenen, Modellgröße, Faltungsdetails usw. Können die Autoren eine intuitive Erklärung dafür liefern, warum FlashAttention am langsamsten ist, wenn die Sequenzlänge sehr groß ist (Abbildung 8 links)?
Als Reaktion auf die Zweifel des Rezensenten machte sich der Autor ebenfalls daran, seine Hausaufgaben zu machen und legte einige experimentelle Daten zur Widerlegung vor.
Zu der ersten Frage zum Modelldesign gab der Autor beispielsweise an, dass das Team sich auf die Komplexität groß angelegter Vorschulungen und nicht auf kleine Benchmarks konzentrieren möchte.
Dennoch übertrifft Mamba alle vorgeschlagenen Modelle und mehr auf WikiText-103 deutlich, was wir von unseren allgemeinen Ergebnissen in Sprachen erwarten würden.
Zuerst verglichen wir Mamba in genau der gleichen Umgebung wie das Hyena-Papier [Poli, Tabelle 4.3]. Zusätzlich zu den gemeldeten Daten haben wir auch unsere eigene starke Transformer-Basislinie optimiert.
Wir haben dann das Modell auf Mamba umgestellt, was eine Verbesserung von 1,7 Personen gegenüber unserem Transformer und 2,3 Personen gegenüber dem ursprünglichen Basistransformer ergab. Wie bei den meisten Deep-Sequence-Modellen (einschließlich FlashAttention) beträgt die Speichernutzung nur die Größe des Aktivierungstensors. Tatsächlich ist Mamba sehr speichereffizient; wir haben zusätzlich den Trainingsspeicherbedarf des 125-MB-Modells auf einer A100-80-GB-GPU gemessen. Jeder Stapel besteht aus Sequenzen der Länge 2048. Wir haben dies mit der speichereffizientesten Transformer-Implementierung verglichen, die wir kennen (Kernel-Fusion und FlashAttention-2 mit Torch.compile).
Weitere Einzelheiten zur Widerlegung finden Sie unter https://openreview.net/forum?id=AL1fq05o7H
Im Allgemeinen wurden die Kommentare der Rezensenten vom Autor gelöst Sie wurden alle von den Rezensenten ignoriert.
 Jemand hat einen „Punkt“ in der Meinung dieses Rezensenten gefunden: Vielleicht versteht er nicht, was RNN ist?
Jemand hat einen „Punkt“ in der Meinung dieses Rezensenten gefunden: Vielleicht versteht er nicht, was RNN ist?
Internetnutzer, die den gesamten Prozess beobachteten, sagten, dass der gesamte Prozess zu schmerzhaft sei, um ihn zu lesen. Der Autor des Papiers gab eine so ausführliche Antwort, aber die Rezensenten schwankten überhaupt nicht und bewerteten ihn nicht erneut.
Bewerten Sie eine 3 mit einem Konfidenzniveau von 5 und ignorieren Sie die begründete Widerlegung des Autors. Diese Art von Rezensent ist zu nervig. 
Die anderen drei Rezensenten gaben hohe Punktzahlen von 6, 8 und 8. 
Der Rezensent, der 6 Punkte erzielte, wies darauf hin, dass die Schwäche darin besteht, dass „das Modell während des Trainings immer noch sekundären Speicher wie Transformer benötigt“.
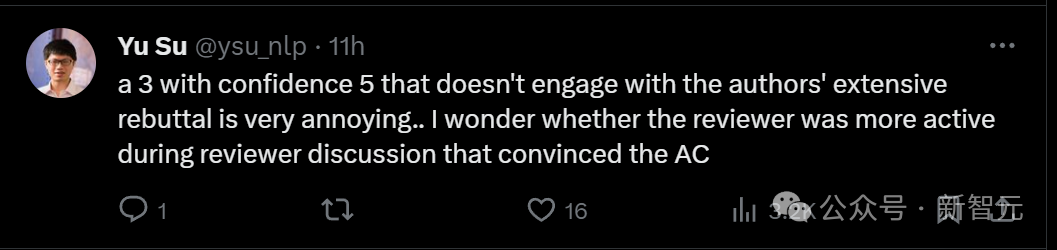
Der Rezensent, der 8 Punkte erzielte, sagte, dass die Schwäche des Artikels lediglich „das Fehlen von Zitaten zu einigen verwandten Werken“ sei.
Ein anderer Rezensent, der 8 Punkte vergab, lobte das Papier und sagte: „Der empirische Teil ist sehr gründlich und die Ergebnisse sind überzeugend.“ 
Nicht einmal eine Schwäche gefunden.
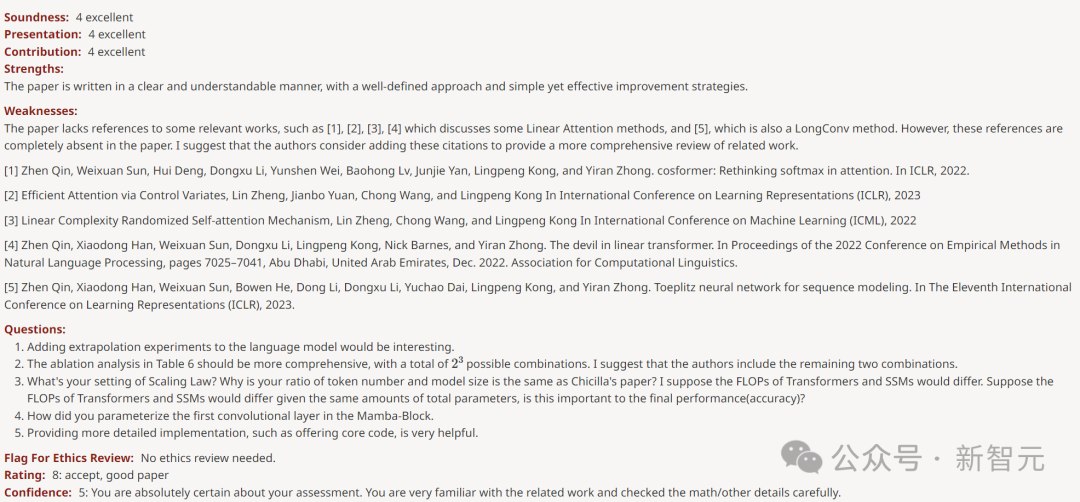
Für solch stark unterschiedliche Einstufungen sollte es eine Erklärung geben. Aber es gibt noch keine Meta-Rezensentenkommentare.
Im Kommentarbereich fragte jemand nach Seelenfolter. Wer hat so eine niedrige Punktzahl von 3 erreicht? ?

Offensichtlich hat dieses Papier mit sehr niedrigen Parametern bessere Ergebnisse erzielt, und der GitHub-Code ist auch klar und jeder kann ihn testen, sodass er in der Öffentlichkeit Anklang gefunden hat, also fühlt sich jeder empörend an.
Einige Leute haben einfach WTF geschrien, auch wenn die Mamba-Architektur das Muster von LLM nicht ändern kann, ist es ein zuverlässiges Modell mit mehreren Verwendungsmöglichkeiten für lange Sequenzen. Bedeutet diese Bewertung, dass die heutige akademische Welt im Niedergang begriffen ist?
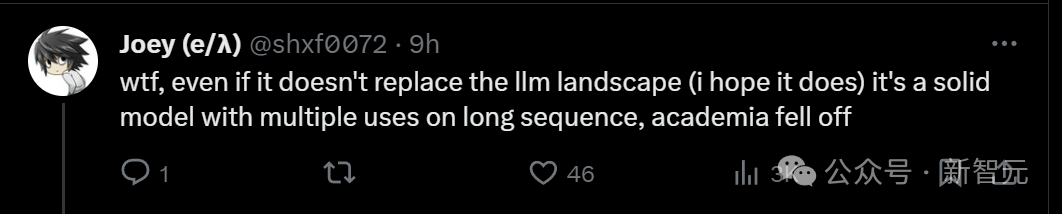
Alle sagten voller Emotionen, dass dies glücklicherweise nur einer der vier Kommentare sei. Die anderen Rezensenten hätten hohe Bewertungen abgegeben und die endgültige Entscheidung sei noch nicht gefallen.
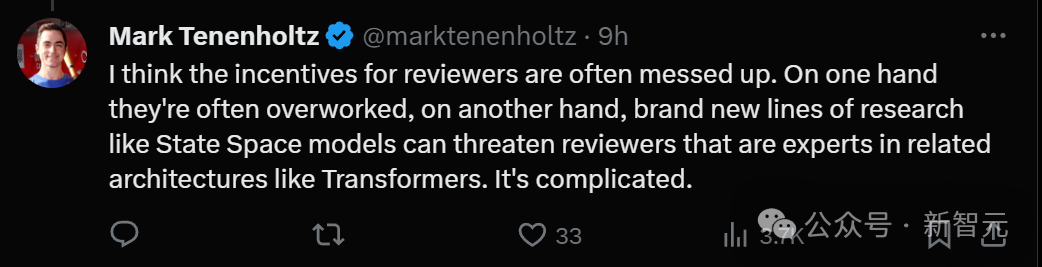
Einige Leute spekulieren, dass der Rezensent möglicherweise zu müde war und sein Urteilsvermögen verloren hat.
Ein weiterer Grund ist, dass eine neue Forschungsrichtung wie das State Space-Modell einige Gutachter und Experten gefährden könnte, die auf dem Gebiet des Transformers große Erfolge erzielt haben. Die Situation ist sehr kompliziert.
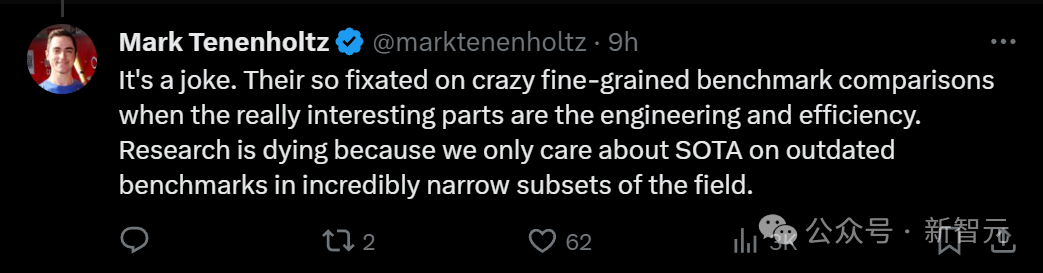
Manche Leute sagen, dass es in der Branche einfach ein Witz ist, dass Mambas Arbeit 3 Punkte erhält.
Sie konzentrieren sich so sehr auf den Vergleich verrückter, feinkörniger Benchmarks, aber der wirklich interessante Teil des Papiers ist die Technik und Effizienz. Die Forschung liegt im Sterben, weil wir uns nur um SOTA kümmern, wenn auch auf veralteten Benchmarks für einen äußerst engen Teilbereich des Fachgebiets.
„Nicht genug Theorie, zu viele Projekte.“

Derzeit ist dieses „Rätsel“ noch nicht ans Licht gekommen und die gesamte KI-Community wartet auf ein Ergebnis.
Das obige ist der detaillierte Inhalt vonDie bahnbrechende Arbeit von Transformer stieß auf Widerstand, die Überprüfung durch die ICLR warf Fragen auf! Die Öffentlichkeit wirft Black-Box-Operationen vor, LeCun berichtet von ähnlichen Erfahrungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Die Webseite öffnet sich langsam
Die Webseite öffnet sich langsam
 Wofür wird ein Softrouter verwendet?
Wofür wird ein Softrouter verwendet?
 So formatieren Sie die Festplatte unter Linux
So formatieren Sie die Festplatte unter Linux
 Methode zur Erstellung von Intouch-Berichten
Methode zur Erstellung von Intouch-Berichten
 So verwenden Sie die Averageifs-Funktion
So verwenden Sie die Averageifs-Funktion
 Der Unterschied zwischen Threads und Prozessen
Der Unterschied zwischen Threads und Prozessen
 Was man im Programmierkurs lernen kann
Was man im Programmierkurs lernen kann








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



