


Das jüngste Aufkommen großer Sprachmodelle (LLMs) und ihrer fortschrittlichen Hinweisstrategien bedeutet, dass die Sprachmodellforschung erhebliche Fortschritte gemacht hat, insbesondere bei klassischen Aufgaben der Verarbeitung natürlicher Sprache (NLP). Eine wichtige Innovation ist die Chain of Thought (CoT)-Prompting-Technologie, die für ihre Fähigkeit zur mehrstufigen Problemlösung gelobt wird. Die CoT-Technologie folgt dem menschlichen sequentiellen Denken und zeigt eine hervorragende Leistung bei einer Vielzahl von Herausforderungen, einschließlich domänenübergreifender, langfristiger Generalisierungs- und sprachübergreifender Aufgaben. Mit seinem logischen, schrittweisen Argumentationsansatz bietet CoT entscheidende Interpretierbarkeit in komplexen Problemlösungsszenarien.
Obwohl CoT große Fortschritte gemacht hat, muss die Forschungsgemeinschaft noch einen Konsens über seinen spezifischen Mechanismus und seine Funktionsweise erzielen. Aufgrund dieser Wissenslücke bleibt die Verbesserung der CoT-Leistung Neuland. Derzeit ist Versuch und Irrtum die wichtigste Methode, um Verbesserungen bei CoTs zu erforschen, da den Forschern eine systematische Methodik fehlt und sie sich nur auf Vermutungen und Experimente verlassen können. Dies bedeutet jedoch auch, dass in diesem Bereich wichtige Forschungsmöglichkeiten bestehen: die Entwicklung eines tiefen, strukturierten Verständnisses des Innenlebens von CoTs. Das Erreichen dieses Ziels würde nicht nur aktuelle CoT-Prozesse entmystifizieren, sondern auch den Weg für eine zuverlässigere und effizientere Anwendung dieser Technik bei einer Vielzahl komplexer NLP-Aufgaben ebnen.
Forschung von Forschern wie der Northwestern University, der University of Liverpool und dem New Jersey Institute of Technology untersucht den Zusammenhang zwischen der Länge von Argumentationsschritten und der Genauigkeit von Schlussfolgerungen weiter, um Menschen besser zu verstehen, wie sie die Verarbeitung natürlicher Sprache effektiv lösen können ( NLP-Problem. In dieser Studie wird untersucht, ob der Inferenzschritt der kritischste Teil der Eingabeaufforderung ist, der die Funktion von Continuous Open Text (CoT) ermöglicht. Im Experiment kontrollierten die Forscher die Variablen streng, insbesondere bei der Einführung neuer Argumentationsschritte, um sicherzustellen, dass kein zusätzliches Wissen eingeführt wurde. Im Nullstichprobenexperiment änderten die Forscher die anfängliche Aufforderung von „Bitte denken Sie Schritt für Schritt“ zu „Bitte denken Sie Schritt für Schritt und denken Sie sich so viele Schritte wie möglich aus.“ Für das kleine Stichprobenproblem entwarfen die Forscher ein Experiment, das die grundlegenden Argumentationsschritte erweiterte und gleichzeitig alle anderen Faktoren konstant hielt. Durch diese Experimente fanden die Forscher einen Zusammenhang zwischen der Länge der Argumentationsschritte und der Genauigkeit der Schlussfolgerungen. Genauer gesagt neigten die Teilnehmer dazu, genauere Schlussfolgerungen zu ziehen, wenn sie aufgefordert wurden, mehr Schritte durchzudenken. Dies zeigt, dass bei der Lösung von NLP-Problemen die Genauigkeit der Problemlösung durch die Erweiterung der Argumentationsschritte verbessert werden kann. Diese Forschung ist von großer Bedeutung für ein tiefes Verständnis der Lösung von NLP-Problemen und bietet nützliche Hinweise zur weiteren Optimierung und Verbesserung der NLP-Technologie.

Die erste Reihe von Experimenten in diesem Artikel zielt darauf ab, die Verbesserung der Inferenzleistung für Zero-Shot- und Small-Shot-Aufgaben mithilfe der Auto-CoT-Technologie im Rahmen der oben genannten Strategie zu bewerten. Als nächstes wurde die Genauigkeit verschiedener Methoden bei unterschiedlicher Anzahl von Inferenzschritten bewertet. Anschließend erweiterten die Forscher den Forschungsgegenstand und verglichen die Wirksamkeit der in diesem Artikel vorgeschlagenen Strategie auf verschiedene LLMs (wie GPT-3.5 und GPT-4). Die Forschungsergebnisse zeigen, dass innerhalb eines bestimmten Bereichs ein klarer Zusammenhang zwischen der Länge der Argumentationskette und der Fähigkeit von LLM besteht. Es ist zu bedenken, dass sich die Leistung immer noch verbessert, wenn Forscher irreführende Informationen in die Schlussfolgerungskette einbringen. Dies führt uns zu einer wichtigen Schlussfolgerung: Der Schlüsselfaktor für die Leistung scheint die Länge der Gedankenkette zu sein, nicht ihre Genauigkeit.
Die wichtigsten Erkenntnisse dieses Artikels sind wie folgt:
Die Forscher verwendeten Analysen, um den Zusammenhang zwischen Argumentationsschritten und der CoT-Eingabeaufforderungsleistung zu untersuchen. Die Kernannahme ihres Ansatzes besteht darin, dass der Serialisierungsschritt die kritischste Komponente von CoT-Hinweisen während der Inferenz ist. Diese Schritte ermöglichen es dem Sprachmodell, bei der Generierung von Antwortinhalten mehr Argumentationslogik anzuwenden. Um diese Idee zu testen, entwarfen die Forscher ein Experiment, um den Argumentationsprozess von CoT durch sukzessives Erweitern und Komprimieren der grundlegenden Argumentationsschritte zu ändern. Gleichzeitig hielten sie alle anderen Faktoren konstant. Konkret änderten die Forscher lediglich systematisch die Anzahl der Argumentationsschritte, ohne neue Argumentationsinhalte einzuführen oder bestehende Argumentationsinhalte zu löschen. Im Folgenden bewerten sie CoT-Hinweise mit Null- und Wenig-Schuss-Werten. Der gesamte experimentelle Prozess ist in Abbildung 2 dargestellt. Durch diesen Ansatz zur Analyse kontrollierter Variablen haben die Forscher aufgeklärt, wie sich CoT auf die Fähigkeit von LLM auswirkt, logisch fundierte Antworten zu generieren.
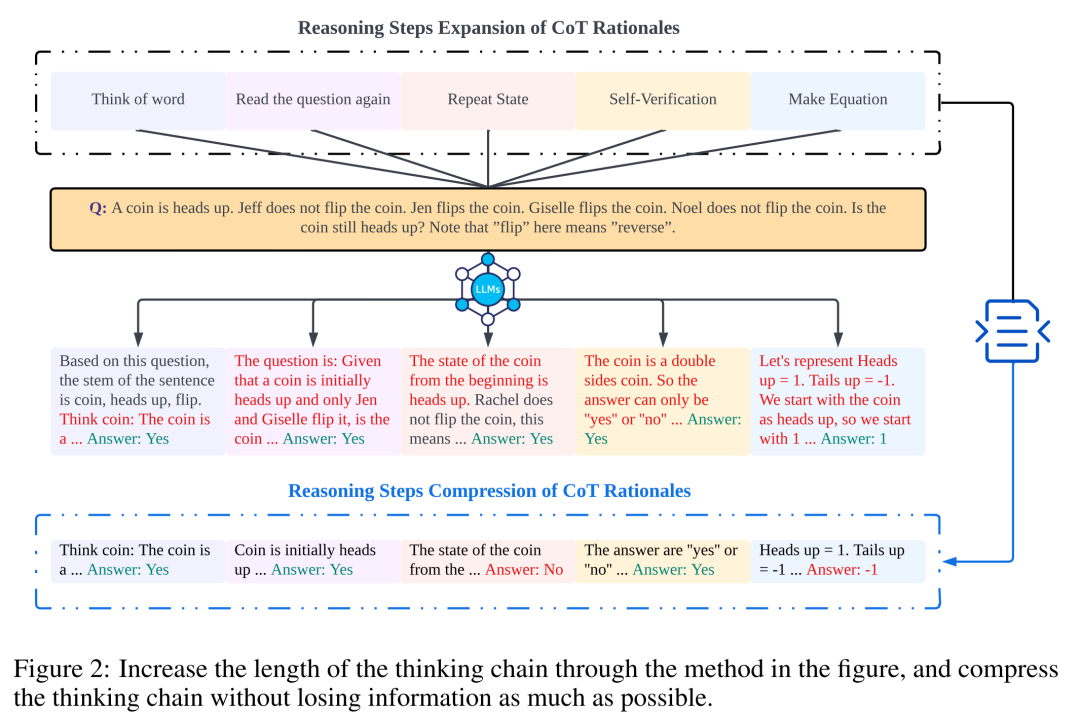
CoT-Analyse ohne Stichprobe
Im Nullstichproben-Szenario änderte der Forscher die anfängliche Aufforderung von „Bitte denken Sie Schritt für Schritt“ in „Bitte denken Sie Schritt für Schritt und versuchen Sie es.“ Überlegen Sie sich möglichst viele Lösungen „Schritt“. Diese Änderung wurde vorgenommen, da Benutzer im Gegensatz zur Fence-Shot-CoT-Umgebung während der Verwendung keine zusätzlichen Inferenzschritte einführen können. Durch die Änderung der anfänglichen Aufforderung veranlassten die Forscher LLM, breiter zu denken. Die Bedeutung dieses Ansatzes liegt in seiner Fähigkeit, die Modellgenauigkeit zu verbessern, ohne dass inkrementelles Training oder zusätzliche beispielgesteuerte Optimierungsmethoden erforderlich sind, die in Szenarien mit wenigen Schüssen typisch sind. Diese Verfeinerungsstrategie gewährleistet einen umfassenderen und detaillierteren Inferenzprozess und verbessert die Leistung des Modells unter Bedingungen ohne Stichprobe erheblich.
CoT-Analyse kleiner Stichproben
In diesem Abschnitt wird die Inferenzkette in CoT durch Hinzufügen oder Komprimieren von Inferenzschritten geändert. Ziel ist es zu untersuchen, wie sich Änderungen in der Argumentationsstruktur auf LLM-Entscheidungen auswirken. Während der Erweiterung des Inferenzschritts müssen Forscher vermeiden, neue aufgabenrelevante Informationen einzuführen. Auf diese Weise wurde der Inferenzschritt zur einzigen Studienvariablen.
Zu diesem Zweck haben die Forscher die folgenden Forschungsstrategien entworfen, um die Inferenzschritte verschiedener LLM-Anwendungen zu erweitern. Menschen haben oft feste Muster in der Art und Weise, wie sie über Probleme denken, wie zum Beispiel das wiederholte Wiederholen des Problems, um ein tieferes Verständnis zu erlangen, das Erstellen mathematischer Gleichungen, um die Gedächtnisbelastung zu reduzieren, das Analysieren der Bedeutung von Wörtern im Problem, um das Verständnis des Themas zu erleichtern, oder das Zusammenfassen Zur Vereinfachung den aktuellen Stand. Eine Beschreibung des Themas. Basierend auf der Inspiration von Zero-Sample-CoT und Auto-CoT erwarten Forscher, dass der CoT-Prozess zu einem standardisierten Modell wird und korrekte Ergebnisse erzielt, indem die Richtung des CoT-Denkens im prompten Teil eingeschränkt wird. Der Kern dieser Methode besteht darin, den Prozess des menschlichen Denkens zu simulieren und die Denkkette neu zu gestalten. Fünf gängige Prompt-Strategien sind in Tabelle 6 aufgeführt.

Insgesamt spiegeln sich die Echtzeitstrategien in diesem Artikel im Modell wider. Was in Tabelle 1 gezeigt wird, ist ein Beispiel, und Beispiele für die anderen vier Strategien können im Originalpapier eingesehen werden.

Die Beziehung zwischen Inferenzschritten und Genauigkeit
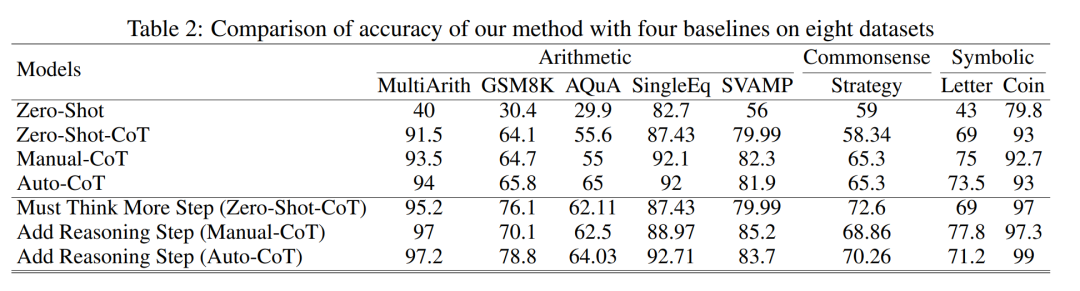
Tabelle 2 vergleicht die Verwendung von GPT-3.5-turbo-1106 an acht Datensätzen für drei Arten von Inferenzaufgabengenauigkeit .
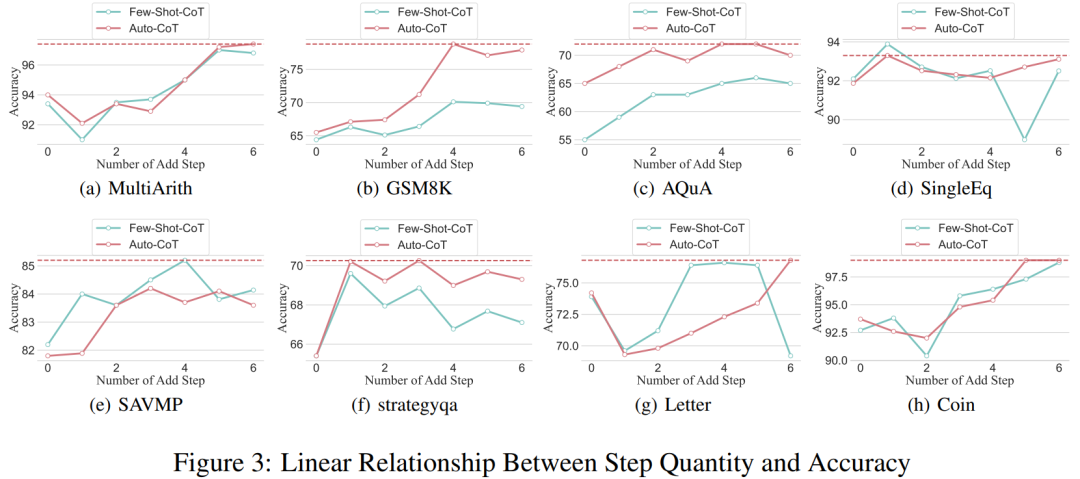
Da es den Forschern gelungen ist, den Denkkettenprozess zu standardisieren, ist es dann möglich, die Verbesserung der Genauigkeit zu quantifizieren, indem Schritte zum grundlegenden Prozess von CoT hinzugefügt werden. Die Ergebnisse dieses Experiments können die zuvor gestellte Frage beantworten: Welche Beziehung besteht zwischen Inferenzschritten und CoT-Leistung? Dieses Experiment basiert auf dem Modell GPT-3.5-turbo-1106. Die Forscher fanden heraus, dass ein effektiver CoT-Prozess, beispielsweise das Hinzufügen von bis zu sechs zusätzlichen Denkprozessschritten zum CoT-Prozess, die Argumentationsfähigkeit großer Sprachmodelle verbessert, und dies spiegelt sich in allen Datensätzen wider. Mit anderen Worten: Die Forscher fanden einen gewissen linearen Zusammenhang zwischen Genauigkeit und CoT-Komplexität.
Auswirkungen falscher Antworten
Ist der Inferenzschritt der einzige Faktor, der die LLM-Leistung beeinflusst? Die Forscher machten folgende Versuche. Ändern Sie einen Schritt in der Eingabeaufforderung in eine falsche Beschreibung und prüfen Sie, ob sich dies auf die Gedankenkette auswirkt. Für dieses Experiment haben wir allen Eingabeaufforderungen einen Fehler hinzugefügt. Spezifische Beispiele finden Sie in Tabelle 3.

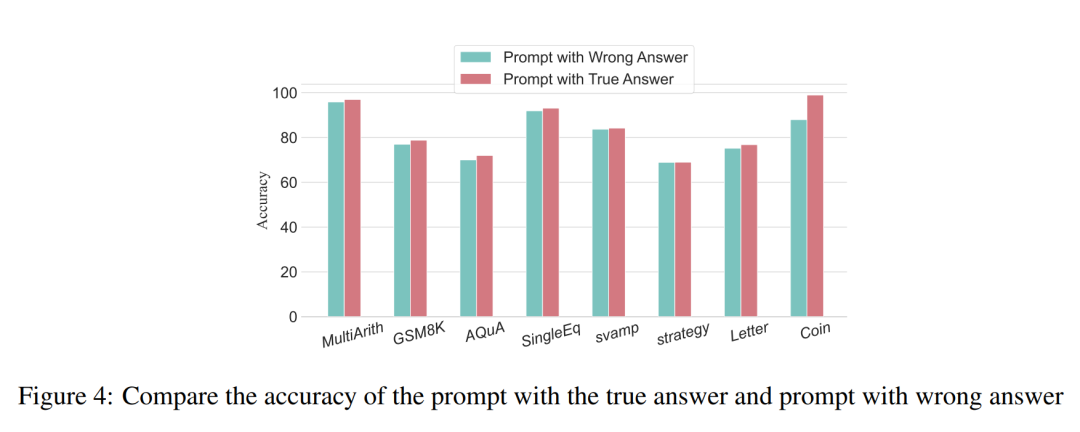
Bei Problemen vom Typ Arithmetik sind die Auswirkungen auf die Denkkette im Argumentationsprozess minimal, selbst wenn eines der Eingabeaufforderungsergebnisse verzerrt ist. Daher glauben die Forscher, dass bei der Lösung von Problemen vom Typ Arithmetik eine große Sprache erforderlich ist Modelle sind für Eingabeaufforderungen sehr wichtig. In der Kette mentaler Modelle lässt sich mehr lernen als in einer einzelnen Berechnung. Bei logischen Problemen wie Münzdaten führt eine Abweichung im prompten Ergebnis häufig dazu, dass die gesamte Denkkette fragmentiert wird. Die Forscher verwendeten auch GPT-3.5-turbo-1106, um dieses Experiment abzuschließen, und garantierten eine Leistung basierend auf der optimalen Anzahl von Schritten für jeden Datensatz, der aus früheren Experimenten erhalten wurde. Die Ergebnisse sind in Abbildung 4 dargestellt.
Komprimierte Argumentationsschritte
Frühere Experimente haben gezeigt, dass das Hinzufügen von Inferenzschritten die Genauigkeit der LLM-Inferenz verbessern kann. Beeinträchtigt die Komprimierung der zugrunde liegenden Inferenzschritte also die Leistung von LLM bei Problemen mit kleinen Stichproben? Zu diesem Zweck führten die Forscher ein Inferenzschrittkomprimierungsexperiment durch und nutzten die im Versuchsaufbau beschriebenen Techniken, um den Inferenzprozess in Auto CoT und Few-Shot-CoT zu verdichten und so die Anzahl der Inferenzschritte zu reduzieren. Die Ergebnisse sind in Abbildung 5 dargestellt.
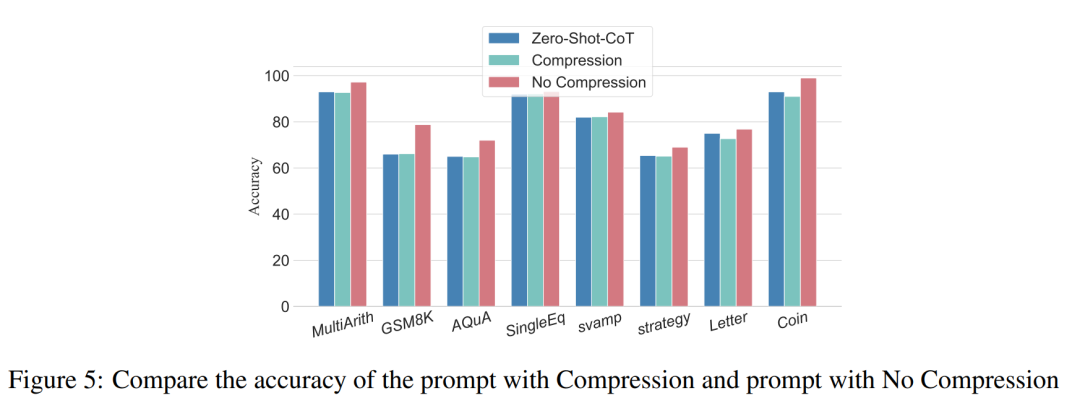
Die Ergebnisse zeigen, dass die Leistung des Modells deutlich abnimmt und auf ein Niveau zurückkehrt, das im Wesentlichen der Nullstichprobenmethode entspricht. Dieses Ergebnis zeigt weiter, dass eine Erhöhung der CoT-Inferenzschritte die CoT-Leistung verbessern kann und umgekehrt.
Leistungsvergleich von Modellen unterschiedlicher Spezifikation
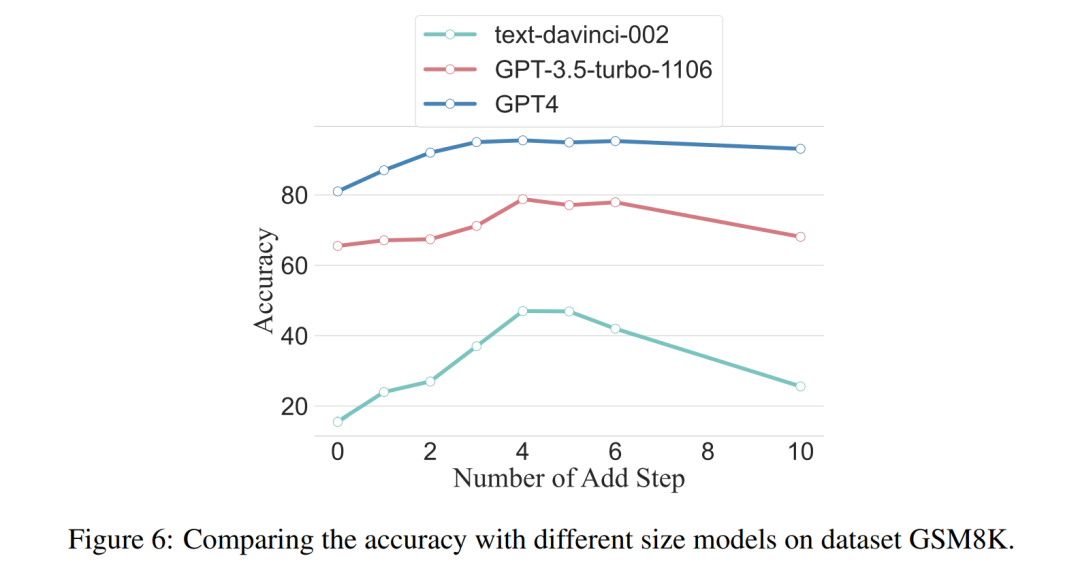
Die Forscher fragten auch, ob wir das Skalierungsphänomen beobachten können, das heißt, ob die erforderlichen Inferenzschritte mit der Größe des LLM zusammenhängen? Die Forscher untersuchten die durchschnittliche Anzahl der Inferenzschritte, die in verschiedenen Modellen verwendet wurden, darunter text-davinci-002, GPT-3.5-turbo-1106 und GPT-4. Die durchschnittlichen Inferenzschritte, die jedes Modell benötigt, um die Spitzenleistung zu erreichen, wurden durch Experimente mit GSM8K berechnet. Unter den 8 Datensätzen weist dieser Datensatz den größten Leistungsunterschied zu text-davinci-002, GPT-3.5-turbo-1106 und GPT-4 auf. Es ist ersichtlich, dass die in diesem Artikel vorgeschlagene Strategie im text-davinci-002-Modell mit der schlechtesten Anfangsleistung den höchsten Verbesserungseffekt hat. Die Ergebnisse sind in Abbildung 6 dargestellt.
Auswirkung von Problemen in Beispielen für die Zusammenarbeit Die Forscher wollten untersuchen, ob sich eine Änderung der Argumentation des CoT auf die Leistung des CoT auswirken würde. Da in diesem Artikel hauptsächlich die Auswirkungen des Inferenzschritts auf die Leistung untersucht werden, muss der Forscher bestätigen, dass das Problem selbst keinen Einfluss auf die Leistung hat. Daher wählten die Forscher die Datensätze MultiArith und GSM8K sowie zwei CoT-Methoden (Auto-CoT und Few-Shot-CoT), um Experimente in GPT-3.5-turbo-1106 durchzuführen. Der experimentelle Ansatz dieser Arbeit beinhaltet bewusste Modifikationen der Beispielprobleme in diesen mathematischen Datensätzen, wie beispielsweise die Änderung des Inhalts der Fragen in Tabelle 4.
Es ist erwähnenswert, dass vorläufige Beobachtungen zeigen, dass diese Änderungen am Problem selbst von mehreren Faktoren den geringsten Einfluss auf die Leistung haben, wie in Tabelle 5 gezeigt.

Diese vorläufige Erkenntnis zeigt, dass die Länge der Schritte im Argumentationsprozess der wichtigste Faktor ist, der die Argumentationsfähigkeit großer Modelle beeinflusst, und dass das Problem selbst nicht den größten Einfluss hat.
Für weitere Einzelheiten lesen Sie bitte das Originalpapier.
Das obige ist der detaillierte Inhalt vonNützlichere Modelle erfordern ein tieferes „Schritt-für-Schritt-Denken' und nicht nur „Schritt-für-Schritt-Denken', das nicht ausreicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



